No, it doesn’t - not for me, anyway. It searches the current text, won’t find text that I removed in a previous snapshot.
Click in the snapshot’s text, then “Next”
Sure, if I know which snapshot to search, and of which document…
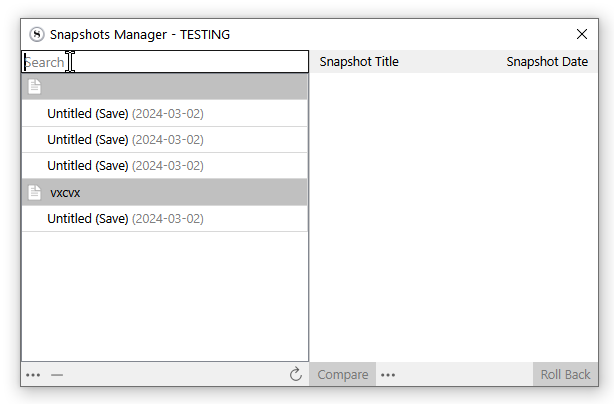

Very well, that does it. Although having to switch to Snapshots Manager every time the regular “project search” fails to find anything is a bit of a bother, especially if I’m trying a few variations of a phrase I thought I used somewhere.
Project Search doesn’t search the snapshots.
I know, that’s what I just said. To truly search the project in its entirety, I have to first run Project Search to search in current content, or, if that fails, go to Snapshots Manager and repeat my search there. It’s a way, but not a good way.
Sure.
But that is the purpose of snapshots. To keep somewhere what might no longer be in the project itself…
There is nothing annoying about it once you know what to do in order to get what you want.
Well, yes, I know that as well, I’m confused why you’re explaining the basics again. But if I don’t remember whether I deleted or rewrote something, then I have to search twice: in current content, and then in snapshots. I’d’ve expected for Search to find in everything at once, current and history, perhaps ruled by a checkbox somewhere, that’s all.
I couldn’t disagree more, frankly. There is everything annoying in having to know what I want in the first place. One could easily extend that logic to writing in general - why do we need snapshots, if we can just write what we want to write already? And yet we invent tools to help with that. Same with my “search in everything” suggestion, loosely formed here. I shouldn’t be expected to know where to search, if the program can quite easily search in everything’s histories.
That’s not what I meant.
You want to find that funny sentence you wrote. So you use Project Search.
It tells you in which document(s) it is.
Yay.
It lists no documents. Ok. You know you wrote it so you’ll search your convenient snapshots.
You know how to search your snapshots. And so you find it.
Yay.
You know how to get what you want and so you get it efficiently.
If Project Search tells you that it is in the project when it is not, how’s that better ?
Snapshots are a sub layer of the project. And so they have their own system. (My understanding of it.)
We seem to be running in a circle. You don’t mind having to search twice, I do if I know that’s a trivial task for the program. Project Search could quite easily list out matching snapshots in the list of results. Hence, my surprise that it doesn’t already do that, and my voice that maybe it’d be better if it did, letting users search just once, in one field: if it’s found, you get to see where and when; if it’s not, it’s just not in the project at all.
Keep a single file of those things in your project. Everything is one spot. Search that using Project Search. Having One Ring to Rule Them All is easy with one bucket. Or do something else if that’s not for you.
Scrivener is not going to give you the level of version tracking that you might expect from dedicated source control tools.
FWIW, the tools that do provide that level of tracking mostly don’t have anything resembling Scrivener’s split/rearrange/merge functionality. If version control is important to you, you can certainly use cut/paste exactly as you would in those tools.
Technically, the issue is that Scrivener’s Split/Merge functionality creates (or removes) actual files on the disk. So you’re asking to keep track of changes to a file that literally no longer exists. Most of Scrivener’s core audience – people writing long documents more or less independently – simply don’t require that level of detail.
2 Likes
Oh. Separate, actualy files, you say. Well, that does put a dent in the idea. Not a huge one, since tools like SVN or Git nicely tag files that are renamed or, technically not a big deal, merged or split. All it’d take is an annotation in the database - “files Y and Z, created right now, are children of file Z that got split at line 34”. But indeed it could require a shift in the approach the program is built on.
What I was trying to envision, sans the separate files technicalities, was a way to build a story from the first draft gradually to the final form, using ONLY the basic “change/split/merge” tools.
I was thinking of starting by writing, say, “A young boy goes on an adventure and ends up marrying a princess”. Then I’d enhance it into “A young boy encounters a witch. The witch kidnaps him to Lalaland. The boy defeats the witch and gets to marry Lalaland’s princess”. This is now a three-act structure, more or less. Split all sentences into three separate threads. Rewrite “A young boy encounters a witch” into “A young boy is sent to town for groceries, and on the way …” I’m sure one can easily imagine the rest of the process, with - ultimately - each couple of paragraphs being a separate object, worked on and enriched or stripped down independently of the rest of the story. And at any time one could easily see where the current version came from.
I guess I’m still on the lookout for a piece of software that would do this… ![]()
You can do all of that except the tracking in Scrivener.
1 Like
Now envision how large that metadata file would become over the course of a 100,000 word novel. Or a 300,000 word trilogy.
My 32 GB of memory plus efficient compression algorithms yawn at the difficulties ahead.
I’m happy for you, but many of our users have much less capable hardware.
1 Like
I’m pretty sure even 8 GB is enough to store a 300,000-word trilogy, in its entirety, several times over. And who’s to say it’d all need to be stored in RAM at all times? We do have hard disks, far more capacious…