Hi,
I’ve played around and mimicked the example that’s in the Help > Placeholder Tags >
Specifically Figure and Table numbering.
Although I was able to copy the example, it is not clear to me how I can use it in my projects.
More in general, I’m trying to learn how to create a scrivener document with:
- consistent numbering - like the user manual
- ability to integrate images - full page and also smaller, say 2 per page, using <$img:path/to/image;w=width>, but also be able to use this as a reference in the rest of the document.
- generate a TOC
- generate a list of included images & footnotes
Below is a screenshot of what I concocted. I’d like to better understand the following parts:
$n -> this will be the auto-number
eg -> ??
foo / bar / inbetweener are whatever you / I want it to be
It seems auto correction has capitalised some of my $n but it doesn’t seem to bother Scrivener’s functioning.
Can someone shed a couple of megaWatts of light please? 
If you haven’t had a look, AmberV has shared the Scrivener source of the User manual, it is like the Old AND New Testament for Scrivener power users, all the tricks are in there:
literatureandlatte.com/support.php#docs-mac
Personally, I use numbered figures extensively in a Scrivener+MMD writing format.
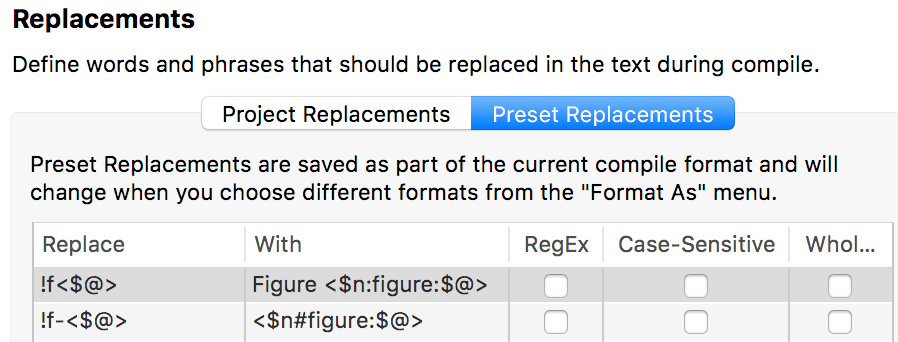
I use preset replacements (a trick AmberV suggested) to make writing them a bit easier:
…so I actually write:
Sizing of figures depends on the output format (I tend to use LibreOffice or Word). I also number equations, but don’t use any other numbered things. The cool thing about Scrivener⇨MMD/Pandoc⇨LibreOffice/Word is that it correctly marks up and styles figures + captions, and Heading 1-6 are all correctly defined. That means that TOC and Table of Figures is a simple click away. Pandoc also supports some cool filters for more complex numbering (by section for example, numbering of subfigures, figure sizing):
github.com/lierdakil/pandoc-crossref
I haven’t used this yet, and for me Scrivener’s “Placeholder tags” are good enough for the moment, but it is nice to know if I need more power it is quite quick to switch to these.
$n == number stream
eg == kind tag, can be figure, equation, table, part — for each name a number stream is created.
foo/bar == your unique label
The other important point is $n:eg vs. $n#eg — I always use : when I am labelling something and # when I am referencing it. This means you can reference something BEFORE it has been specified in the text. In my replacement this becomes !f< vs. !f-<, I use the hyphen to specify that i am referencing a label.
1 Like
Hi NonTroppo!
Thanks for elaborating!
I guess I will have to do more exercising to ‘really’ ingest all of this and really be able to fluently use it.
Up to now I have been using Scrivener as a bucket for some project related note taking I had to do, mainly using the binder as a handy way to organise stuff.
It has really only become different now that I start using the compiler, as it is only then and there that things start to lead a life of their own if you don’t fully grasp its inner workings.
Indeed I found the source of the user manual, which is really great but which also lacks kind of ‘real life’ matter of factness as an example to follow in the way that it is set up as a MMD project and the fact it is set up to be compiled for LaTeX.
Now I am aware of postscript and LaTeX capabilities and have been toying with it in the past. (My emacs / org-mode era)
But this does not make it an easy example to follow and learn from unfortunately.
Related to this I have another question:
Chapter 22 of the user manual treats MarkDown and MultiMarkdown extensively.
But is MMD working in the background all the time (with captions and replacements and the way you ‘write’ these)?
Or will it only do its work when you ‘compile’ for MultiMarkdown?
Thanks for helping out!
No it only works at compile time, it is your job to write the markup. In fact if you compile to plain MultiMarkDown, it doesn’t even run at all; Scrivener does the work to compile to an .MD file but it is then up to you to manually convert the project.md to a project.odt or whatever you output to. If you can write a simple script you can then do a lot of customisation not possible with the built-in mmd compile options.
You don’t have to use MMD at all (most Scrivener users don’t, and quite a few are put off by the mmd format). You can do numbering and most other things not using MMD, just sticking to “normal” compile formats. But Scrivener does not output well-formed documents (where levels in the binder draft get correctly assigned different outline levels), and you end up having to do a lot of additional manual formatting.
The super cool thing about MMD and Pandoc (you can use either with Scrivener) is their flexibility and how they make everything easier. For example, you can pass a “template” to mmd or pandoc, so when it creates a DOCX for example, it uses your template so the document is fully styled with your template. Block quotes, code blocks, equations, figure legends, and bibliography all already formatted using your preferred template styles, so convenient!
Yes, AmberV’s source file is quite overwhelming I agree, but that was to give you a sense of what is possible!!! 8)
NonTroppo,
Thanks for explaining!
Grazie Mille!
Prego!  I suggest you start with figure numbering in a working project and slowly build up from that, ask more questions if you need help.
I suggest you start with figure numbering in a working project and slowly build up from that, ask more questions if you need help.