Maybe I am getting old, but I still type fast. The problem is that I often have to backspace to repair a double capital. YOu know what I mean… I know Word fixes this automatically. Someone asked this question here a few years ago, but nothing was available in Scrivener. How about today? Did v3 address this? Is there a way to automatically repair these?
I’m pretty sure using RegEx it can easily be done, as RegEx makes a distinction between caps and normal case (I think).
In combination with project replace, this should be no trouble.
I don’t know how to design a formula myself, but all you need is
[Replace] Whatever - x Caps - y Caps - Whatever
[With] Whatever - x Caps - y normal case - Whatever
Shouldn’t be too complicated.
Here is a place to try things out if you feel like playing with it:
You could alternatively use that option:
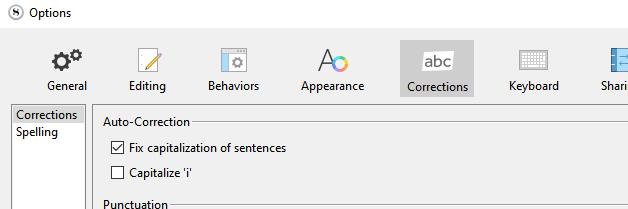
and refrain from capitalizing the first letter of your sentences yourself.
Can’t seem to find anything that works in RegEx, but second idea is an option. Provided I can train myself not to capitalize the beginning of sentences! It also wouldn’t help with names. Sure would be nice to have this fixed on the fly as Word does.
Thanks for the help!
I got this to work:
In the “Find” field, ([A-Z][A-Z]) locates consecutive caps.
That’s a start.
You could use that to locate mistakes later on. Then fix them manually. Better than nothing.
But give it time, someone I’m sure will come up with a proper formula.
Great! If there is no way to do it on the fly, I might be able to use this for a whole document repair. At least then I can stop backspacing! Could I replace with ([A-Z}{a-z}) ? I am not RegEx smart.
Oops. I meant ([A-Z][a-z])
I tried and it doesn’t work.
It is a tad more complex than that.
You need the formula to isolate groups.
When replacing like you posted, it inserts the formula as text. No go.
@AntoniDol
Yes, that’s what it did for me. Seems like the right track, though.
I’ve got this:
Search for: \A([A-Z])([A-Z])(.+)
Replace with: $1\L$2$3
Or with: \1\L\2\3
but it makes lowercase of capital letters in the rest of the string… Think “I” becoming “i”…
1 Like
Hi Antoni. ![]()
Yes, “I” could be a problem.
But given that it is systematically preceded and followed by a space, first in the sentence or not, could there be a way to isolate it based on this criteria?
And design a formula that only affects the first two (or maybe three) letters of a sentence, so that proper names don’t become a problem?
(I am just chatting… ![]() I have no clue how to do this.)
I have no clue how to do this.)
1 Like
Actually “I” is not always preceded by a space. Now that I think of it, it doesn’t work for a paragraph. But there is always a space after.
More even, I think that if the formula only targets the first two letters of a sentence, there is no need to bother with it.
You’re right. Just ditch the last capturing group:
Search for: \A([A-Z])([A-Z])
Replace with: $1\L$2
Or with: \1\L\2
1 Like
Not quite yet :
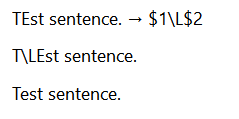
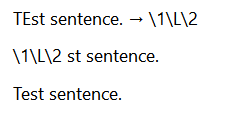
I does target only the the two capital letters at the beginning of the sentence though.
That’s a great start.
Scrivener doesn’t seem to like \L so much. Like it doesn’t know what it means. Treats it as plain text.
Same for \1 and \2.
Out of curiosity, I searched the web to see if there was any other way to transform UPPERCASE into lowercase than \L, but couldn’t find any.
I think this might be the end of it.
At least you have a way to spot wherever a sentence starts with two or more uppercase letters, and manually fix it.
Looks like you’re starting to get the hang of this “puzzles with characters” thing?
I’ve been fighting RegEx for years, denouncing it as a programmer’s toy.
But now, especially when creating e-books, RegEx is an indispensable tool.
I’ve written a layman’s introduction in Mastering Scrivener, you might want to check out.
I’m using https://regex101.com on my mobile to create and test RegEx…
A similar niggly anomaly in Scrivener is double clicking on the first word in a sentence that begins an inverted comma. (Well, any word in the middle of a sentence with inverted commas on either side as well.)
The double click selects the inverted comma as though it’s part of the word, whereas I simply want to edit the word.
I’ve been playing around with this one: for the Find string
\b([A-Z])([A-Z])([a-z]+)
will find you all words beginning with double caps wherever they occur in the text, but will jump over all-caps expressions like UK or USA. However, as has been pointed out, I’m failing to find a way to convert the second letter to lower case. I’ve put out a plea on the Nisus forum to see if any of the coding gurus there have a solution. If they come up with anything, I’ll let you all know.
So if you need, you could do a find, make the correction, then CMD/CTRL-G to jump to the next one, and so on.
Mark
2 Likes
I certainly appreciate the help! Looks like I’ll just have to deal with it. Since I see the errors right away, I almost always fix them before moving forward. It just ruins the flow, if you know what I mean. As unlikely as it sounds, I might just try a new keyboard. I didn’t used to have this problem even with Scrivener, so I assumed it was age, but it could be something mechanical. Again, thanks!
1 Like
In this case just ignore it, knowing you have an efficient way to locate wherever needs fixing later on.
(Perhaps handle it whenever you are out of ideas…)
Else, it could indeed be mechanical.
Although myself having a good keyboard, I sometimes, out of the blue and for an undetermined period of time, get those annoying double caps as well. (?)
→ I type relatively fast. But that in itself doesn’t seem to be much of a factor.
OK, here is what I’ve learnt from the ever helpful Martin at Nisus. Nisus uses ICU RegEx; I’m not quite sure/can’t remember exactly which flavour of RegEx Scrivener uses, but it’s not ICU. Martin favours replacing the minimum amount of text possible, so his formula is:
Find: (?<=\p{Upper})(\p{Upper})(?=\p{Lower}+) — i.e. look behind for an upper case letter; capture an upper case letter; look ahead for a lower case letter
Replace: \T{lowercase:\1} — i.e. transform found to lower case.
Now in RegEx101.com. testing PCRE RegEx, the equivalent find string works:
Find: (?<=[A-Z])([A-Z])(?=[a-z])/gm
but in Scrivener it returns “No matches” on the same test sentence.
Presumably the Replace string would be /L:$1 or something like that. I’m not enough of a geek to work out how to check a Find and Replace in RegEx 101, and as the Find string doesn’t find matches in Scrivener (at least on Mac), I can’t go further.
But it would be useful to know what exact flavour of RegEx Scrivener uses on both Mac and Windows.
![]()
Mark