It sure has been a long time since those discussions, and it looks like you did at least find the newer thread, which is more informative toward how things ultimately settled down for me, into a system I still use daily and heavily.
While I may have said some or all of the below before, it’s probably scattered all over the place, and stated from the context of various stages of development, so to speak. So here are a few thoughts on the questions you posed, specifically.
File names
All right, so I might not have ever shared how things ended up, but this is the format I have used for quite some time now, and it would make sense to have a modern example before getting into the specifics of it.
24061492 M2.1.ICFS updates on the system from years gone by
The date prefix
I’m unsure of the filenaming convention, though. If I’ve understood correctly, the datestamp works as a sorting mechanism as well as future-proofing the archive against moving to a different computer system during which filesystem metadata might be lost. What I’m wondering about is if it’s still usefull or necessary to insert a timestamp in the filename.
That is part of it, yes, but there are two important components about that initial number that may illuminate its prominent placement in the filename. Yes, it is the date-of-filing, and is thus something that sorts nicely because it is chronologically incremental at the beginning of the name, but the primary purpose is exposed in how it is used as an alias for the entry, and in how I use that number within other entries to definitively refer to this one single entry: it is its unique identifier.
Combining the date-of-filing with unique identification is an elegant form of efficiency for how I work, since both of those components are so integral to how the system is glued together and how individual entries within it are meant to be referenced and discovered: chronology for search scoping, fuzzy human browsing or meandering, and an identifier for precision point to point networking.
Arguably there is nothing more important to the mechanical functioning of the system than having the unique identifier in the file name—at least within the context of what we are doing here: using the file system and file management tools, or software closely aligned with that philosophy.
Or, if the mechanical aspect were theoretically all that mattered, I could get away with ‘24061492.md’ by itself.
If the ID is buried in the metadata alone, then we must rely upon other (slower) tools that are capable of searching within files, rather than being able to use the file system itself and scripts that can very efficiently traverse it. Such would limit our scope and increase dependency upon types of tools.
The secondary reason is, as you put, to have a static and permanent record of any entry’s chronological context amidst other entries that will, like all text, survive import, export, unzipping and any manner of action that might “damage” our original record of that date and time.
There is a tertiary benefit to doing that as well, and that is when you use tools like Obsidian to manage the file system, as such tools tend not to have columns for dates, and only print the filename. Again, we’re keeping the scope of what tools we can use with this system as wide as possible.
The purpose of an entry
With the next filename component, the type, I’m wondering if it’s better to group all metadata at one location, in a header inside the file.
That metadata is of course also in the file, and for how I work, it is the primary metadata in the document from which the filename is derived. The metadata is canon, the filename is a result of its disposition. If I change the tag to {M1.1.ICFS} in a text editor because I decided to respond to you privately, I would regenerate the filename.
So the question becomes whether that kind of information is useful for the fuzzy human component of the system, which the file name is in large part about. In browsing a list of entries, does it help me to know what the purpose of a thing is? And for how I work the answer is, absolutely, it is worth the clutter.
The wording there is significant. I don’t consider this so much a type declaration, but rather I try to use these to indicate why the entry exists. Often these two concepts overlap, but by thinking of it in those terms, it is much easier to avoid categorical sprawl.
And I would say it also serves a mechanical purpose, as having that kind of information at the file system level means being able to easily filter by it—again without having to use tools that dip into content.
The shell command, ls *M2.1* gives me all forum posts within a certain time frame if run from within a quarterly subfolder, while find . -name '*M2.1.*' when run from the archive root gives me a list of all forum posts, from the '90s to now.
Being able to segment and chunk your entries by such criteria can be an essential ingredient in fuzzy human browsing, but whether that is useful to you is a personal matter. The concept of even giving a type or purpose designation may not be crucial to everyone, even in the metadata. It certainly works well for me though.
I’ll skip to this since it is related:
What I’m unsure of in Amber’s system was the choise of using a numbering scheme instead of words. Putting down for example R2.1 instead of ”External observation”. It might seem odd to file receipts under something like ”3.3”. Is the reason for such a system really as simple as being a short-hand that is worth the memorization effort for the benefits of expandability and aid in searches?
I touched on the memorisation aspect in those threads, and how there is less of that if you come up with a logical system behind the numbers. What that system is will vary from one person to the next, I’m sure, but what has worked well for me is the concept of internal vs external, or 1 and 2. That doesn’t require a lot of memorisation. If the second numeral also follows logical patterns that are shared between higher categories it helps further.
It does sometimes get a little nebulous, in that I consider creative writing to be internal and visual arts as external, but it makes sense to me, and that’s all that really matters. Once I’ve established that logic, I1 for Information.Internal can host concepts like I1.1, which is meta. A document on how this system is put together would be I1.1.ICFS, an entry that exists purely to bind other entries together by a common thread, I1.1.Thread. Whereas I2 would host entries that exist for the purpose of referring to works external to the system.
I won’t deny that I don’t use my cheat sheet now and then, but this only takes seconds, and I doubt that if I used a more verbose syntax that this would change. If I need to look up C2.5.Palette for a colour scheme I’m developing, okay, but I’d probably also have to look up “Creative.Visual.SoftwareThemes.Palette”, or whatever else.
And that leads directly into the secondary reason for why I use a shorthand approach, because that goes right back to file naming. Which is easier to read in a list?
20258834 C2.5.Palette literature and latte colour palette.md
20258834 Creative.Visual.SoftwareThemes.Palette literature and latte colour palette.md
Maybe it’s a matter of taste, but for me it is the former, especially since many programs that list things by filename tend to truncate the middle. But, I’ve seen people who adopt this system use a verbose classification in the filename. It can work.
Another oddity is the use of curly braces: {R2.1}, use of which I couldn’t figure out.
That syntax, if you will, is only ever used in one place, where you see it in the screenshot below. It is thus a way of differentiating between my talking about C2.5.Palette, as I have in this post, and wanting to actually find entries that are for that purpose. If I want that, I include the brackets in the search.
That of course is of more importance when using tools that search content as well as filenames by default, like Obsidian. But I suppose some kind of marker like that would be important if one left it out of the file name and relied upon content searches for it.
Using Markdown for dynamic entry linking
Am I right in assuming that even as a non-programmer, I could learn MultiMarkdown to format my notes in a specific way and then use a command-line script to create an html- file to view in a web browser, thus having implemented clickable links on top of plain-text notes?
On the matter of creating a script that can take a shorthand reference to an entry’s ID and turn it into a clickable link—sure something extremely specific and bespoke would most likely require a little programming, but I think it’s useful to consider that whole approach I took within the context of its time.
As with many other things in this system, a lot of these ideas have taken off in different ways since then, and are a lot more convenient now in modern software than they used to be. The need for a clickable link is greatly diminished when you can just double-click the ID number to select it, and hit Ctrl+Shift+F to search for it (no need to even copy and paste in Obsidian). I habitually do this to an entry’s ID in the metadata when I pull something up to reference it. Doing so builds a list of back-references and I can easily jump around to things that have referred to this document—or see perhaps to discover that I’m looking at an older revision for which there is a newer copy, etc.
So I would tentatively say that nowadays you can find ways to get this kind of capability without learning how to program or use Markdown beyond what other programmers give you. Some systems might even be able to turn an alias like in the screenshot into clickable links, perhaps even automatically. I seem to recall DEVONthink doing that in the past, for example. I prefer searching though, overall, because searching gives me the network the entry exists within, rather than merely loading that one document by itself.
Searching is, I would say, integral to how the system is meant to be used, and thus modern software like Visual Studio and Obsidian are major force amplifiers for how well they handle material organised to be searched against via IDs. This type of software only barely existed back in 2007 – 09, when I developed most of this, and so I needed to make my own tools to make it more efficient. While I do still use those tools, I probably would not have developed them if I had started doing this today.
Referencing materials
For (Scrivener) projects
This would mean bringing in projects I handle in Scrivener, by exporting in plain-text to the archive section of the directory layout, while also preserving the original project as a file in the reference section of the directory layout.
That sounds very close to how I work, with one important difference I’ll get into below. Whenever I start a major endeavour, whether it be in the form of a single Scrivener project or a host of supporting files, or just something other than Scrivener entirely—I have a special token for projects. So I create an entry with that token, describe the project and its goals, and now I have an ID for that whole project.
So it’s really the same idea as the library card approach to handling media, only I start before the media is done, and include supporting files used to create said media in that equation. The entry contains a file link to the Scrivener project in the note and makes mention that this represents a work in progress—it’s a stub basically.
Then, once the project is complete:
- I usually compile if its purpose was for the creation of a document, and since I use Markdown exclusively, that means I can simply copy and paste that final compile right into stub entry I started.
- I zip up the project, name it to match the entry (if it isn’t already), and drop it into the correct reference folder based on its purpose.
- The “Source” metadata field is added to the entry, referring to the zipped file’s final placement.
If I ever need to pull it up for revision, I create a new versioned copy of the master entry, and will eventually create a second zip of the project once it is complete. So the chain of revisions is left intact. I use the master entry to mark down revision notes, usually.
Thus the main difference between what you describe and what I do is that I don’t often host the working Scrivener project in the reference directory. I could, I suppose, but for most things I do like to have a strong working vs archived dichotomy in the system. I have a working folder in my user folder, and in there are typically other folders for major projects. Eventually those folders will be zipped and dropped into the reference archive. Overall I very rarely open and modify files in the media reference folder.
How and when the reference media folder is used
I should also say I don’t use the reference archive for everything. I probably could, but I mainly limit it to things that support entries in the archive. I don’t for example, put all of my receipts into this folder. That’s just me though, and I think finding that line where the notes archive should begin and end will be a personal journey. There was a time when I considered everything being worthy of putting into it, but over time I have found it more useful if I am somewhat selective about what is worth putting into it.
A few notes on subfolder naming:
- As for using curly brackets in the reference archive folder names—I stopped doing that years ago. It’s clumsy if you use command-line tools, and it’s entirely unnecessary. I know what the folders are there for, so “R1.4” is all I need to know what kind of things I’ll find in that folder.
- I think it’s also worth noting that these subfolders exist primarily for the same reason the year-quarter folder hierarchy does: I don’t really use it that much. It is mainly there to keep from having a single folder with tens of thousands of things in it. For me it made sense to use token-prefix folder names, because that does actually come in handy now and then. I could easily see this being broken down by some other criteria like file type. Maybe all .scrivs go here, and all .pdfs there. It doesn’t matter too much if you’re linking to these resources from the main entries, that’s how you get to them primarily.
On developing a tag system
I see this as something that is highly personal, but is there a basic, objective framework and a method of expanding it that can be used by anyone as a starting point? For example: Use a top-level set of as few types as possible. Subtype these with the decimal notation where necessary.
Yeah, it’s hard to give even broad advice on this, given how even the core internal structure of my token is probably something more or less only interesting to me. But I like your starting summary:
“Use as few categories as possible and as many as you need. Subtype these with the decimal notation where necessary.”
Less is more
Perhaps there is no good way to advise on this other than to share what worked for me. The categorical system I came up with was designed for conceptual compactness. By that I mean I wanted to have a “language” for describing things in as few branches as possible. This is perhaps in part because the very early attempts at this were so sprawling that they became useless.
So I guess the major principal of the system is to have as few branches as possible, and to trust other mechanisms in the system to provide beneficial specificity. The “token” is all by itself a generalisation tool meant to aid in narrowing down searches and to help identify things in lists of related entries. It can get pretty precise all by itself sometimes, with that last plain-language component, but it doesn’t need to be, and that in and of itself is a stress-relieving component of the system.
In designing one’s own token, I would if anything go back to the roots of where this came from. The two systems I borrowed from on this concept only had one marker level and about four or five of them in total. One used symbols and the other used colour-coded tape on the side of envelopes. I started there, and only allowed things to expand outward when it started feeling claustrophobic.
Here are the four basic components of the token, that I use:
- Broad concept: record, communication, creative work, information. What those are will be different for everyone.
- Modality, I guess you could call the second level. Internal/external, private/public, meta/referential, these are different aspects of the broad concepts that have similar themes. A private communication, a self-referential document, a journal entry. Different things, but sharing a similar mode. Again not everyone will find this particular concept useful. Or maybe there is nothing that large and binary that would work for how they understand information, and they skip this numeral and only have three levels, or have three ‘modes’ instead of two.
- Categorical: with the first two we can say things like ‘public communications’, but at this level we can break things down into concepts like ‘forum’, ‘article comments’, ‘chat rooms’, ‘meeting minutes’, etc. Is that always useful? Maybe not, maybe only very broad strokes are useful along with a final topical declaration. Maybe M2.Scrivener is all you need to file something as a public comment or post about Scrivener. Knowing that it was to a forum, or a blog comment, a conversation in Discord, isn’t essential to you. To me, it helps me find things because that’s how I remember things, by when and where they took place. And when I don’t need that, this is where file system globbing comes in handy, because
find . -name '*M2.*.Scrivener*' returns all the public discourse about Scrivener, no matter where it took place.
- Finally the topical, which isn’t always strictly speaking topical, but that is a good way of thinking about it. It’s the most recognisable part being the bit you type out fully rather than codifying. I2.2.Colleague, for example, gives one a good idea of what the codified part is all about even if you are completely unfamiliar with the codes. Information.Facts.People.Colleague. There are my email addresses, phone numbers, whatever else I need.
So do you need all of that in your listing? Is 24063922 I.Colleague name of person.md enough for you? Is that enough for all of the areas of knowledge you intend to record? For me it would be too little, but as noted at the start: for some the “I” is all they need, the blue piece of tape. It’s all I used for a long time as well in the filename, even though the internal metadata was more detailed.
Do you even need this?
And it would also be fair to note that not everyone needs anything at this level. Some advocate avoiding all categorical statements at all, and to depend entirely on interlinking. This is more the Zettelkästen approach in fact. For me the overhead in putting this into the metadata is so low though, because it is purposefully just vague enough, and I find it very useful and productive to know the kinds of things I’m looking at in a list. I’ve experimented with different file naming schemes, some that just had the date and title—and I never found it has efficient because you have to do much more full title reading and guesswork (clicking one after another and reading content). Titles tend to become categorical statements in my experience.
If that is going to be my tendency, then I would prefer to systematise it. Cut down on the verbosity. Make it something that can be depended upon.
Trust the rest of the system
So to come back to that idea, if we aren’t so much using these to find specific items, but are instead using it as a listing or browsing tool, then that helps to define why they can be so simple as colour-coding or a few letters/numbers.
Consider for example the case of a large complex project. As noted above, when I start such a project, I create an entry for it. I likely won’t ever put much into that entry other than a description of the project, and what its goals are. That entry only exists as a binding agent for what will likely become many other entries: todo lists, gathered research, search results, writings and documentation, etc. That is where these will be most useful, and so within that narrowed context we can see how broadly stated purposes are more useful than detailed typing.
That notion of using “meta entries” to network related entries together, to in essence become a bit of a “tag” themselves, has become essential to how I work, and solved a lot of problems that I had in earlier versions of the system.
Binding entries together with links
In my mind, this doesn’t seem to work since a book could be referenced in many contexts. I might write a note recording a thought I had that references Steven Pressfield. I’d tag the note with (R)ecord. But the book should probably not be filed under that letter since it might also be referenced from a different context.
So yes, this is where the concept of binding entries really comes into play. I already described one scenario using a large project as a binding entry. A book is very much the same sort of thing. The book itself gets filed into the Info tree and pretty much states the raw details of the book, library card style, ISBN, publisher, author, date, etc. and that’s it.
If in reading the book I come across a passage I really want to have readily available, I create an entry for that one passage, and put the book’s entry ID into its metadata area.
There are similar ideas out there in this field. If you search for “Map of Concepts”, or “MoC” as it is often abbreviated to, you’ll see those that advocate creating indexes of other entries in an entry that exists solely for that purpose. It is similar to how I work, but I prefer a lower-overhead and more organic method. I would rather clusters of entries naturally evolve rather than be planned for.
You might think that creating a binding entry is planning, and yes that act itself would be, but a crucial point here is that any entry can become that solely through the collective act of other entries pointing back to it in a retrospective manner.
So, I’m not maintaining a list of all the entries I’ve made about this book, in the book’s entry card by hand. That list builds itself merely by referring to that book ID from other entries. It can go other way as well, and often does in cases of binding entries made years after the fact.
For a practical example of the latter case, I have one for this topic, naturally. It is a master list of forum threads, emails, documents I’ve written and so on. Since it refers to those entries by ID, and since referring to an ID becomes a search result, it doesn’t really matter if I list the entry from the binding entry, or reference the binding entry from the forum post or whatever. Either way a search for the binding entry’s ID returns all of it. So I get my “MoC” without having to curate it by hand.
Thus the implementation would seem to lead to managing the referece section of the system (creating symlinks and such) instead of pulling the reference and getting to work.
Again that hierarchy only exists to file away supporting materials that aren’t plain-text entries. I very rarely go into the reference folder first.
So let’s return to the book example to illustrate that:
- The book details go into an entry. This is a plain-text Markdown file with some metadata (and likely only metadata), using the standard file name in filed into this quarter’s folder along with everything else.
- All of the materials that arise about the book also get filed into this same place, using their own classification, but referring to the book’s ID to establish their relationship.
- The book itself, as an .epub, gets filed into the reference material folder, and its existence would be marked in the main book entry.
So hopefully that makes more sense. The passage I wanted to remember isn’t going into any of these folders. It’s a plain-text file in the main flat-list archive. If I want the ePub, I don’t go looking for it by hand in the reference folder, I pull up the book entry and discover it from there.
All of this is designed to reduce categorical filing (and decision-oriented stress) in the reference folder. If a particular resource is useful to multiple projects, the fork is in the multiplicity of entries that refer to it, rather than having to fork at the file system with symlinks into different project folders.
Recent changes to the system
As for where things have gone since its initial “final” state in 2009, which the newer thread does address: much of what I said there still holds true. I have not radically changed anything with the approach. Of what has changed:
YAML metadata
About four years ago I redid the format for the metadata block to be YAML-friendly. While that does mean a bit more ‘clutter’ than I would sometimes like, to keep it valid, there are distinct advantages to having done so.
Chiefly, since I originally started filing things this way, the concept of a “metadata block” went from a very loose definition that one Markdown tool used (MultiMarkdown), to something many tools started using—and almost all of them settled on YAML, including Pandoc which is the powerhouse behind most other tools that easily generate documents from Markdown.
It is an ideal combination of uses. We can establish personal archival details in the very mechanism that other tools like Quarto might use to turn that entry into a page in a website.
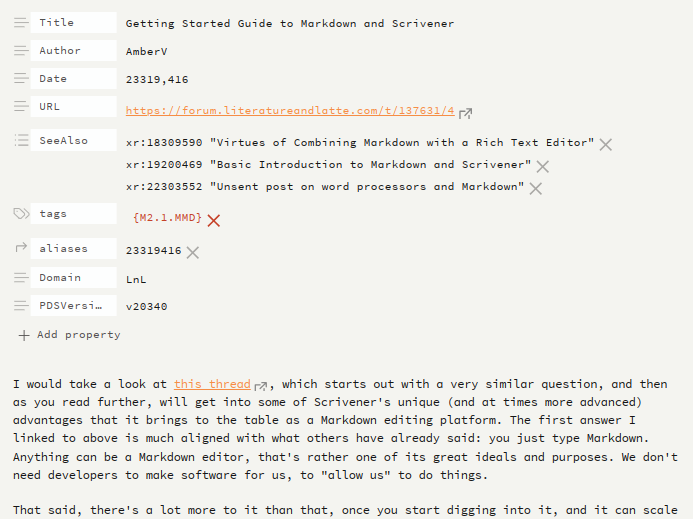
This, for instance, is what my now standard metadata block looks like when dropped into Obsidian:
It detects field types, lets me add list items easily, new fields, click on a link that takes me straight to the original forum post, and so forth. That this can help generate a cover page when using Pandoc to create a LibreOffice document is fantastic for some things (maybe not a forum post, but for internal documentation, surely).
Field conformance to conventions
Along with the v20340 revision to the spec was changing a few of the core field names to also match what had become convention in various different software. In the past I used a combined ID + tagging line using MultiMarkdown’s, at the time, convention for “Keywords”:
Keywords: {M2.1.MMD} id23319416
While concise and good enough for a human, most tools ended up calling such a field ‘tags’, and the concept of an identifier has also in many cases become systematised in some software like Zettlr. I believe Obsidian is not the only one to use an ‘aliases’ key for the purpose of allowing a thing to be identified by something other than its title.
So the above has become:
tags: '{M2.1.MMD}'
aliases: '23339416'
(You can see some of the YAML clutter I referred to. In an ideal world I wouldn’t put quotes around values like that, but one does get used to it after a while.)
Identifier handling
I dropped the two-letter prefix on the ID as well. It was a very early idea from before the compound tag idea, and gradually became redundant once that was implemented more fully. By that I mean you may have come across posts where I would prefix the ID with something like ‘em’ for ‘email’ so that I could see at a glance what kind of thing it was. That’s entirely unnecessary when I’m saying “Email about Markdown” on the line right above it.
Where I do still use a prefix, as you may note in the SeeAlso list of that screenshot, is on outward bound references. ‘xr’, as shown there, is generic for cross-reference. But this is where ‘v2:24061506’ (to indicate that document 24061506 is an older, second revision, of what I’m reading now) comes in quite handy for avoiding excessive and repetitive annotation of links.
The key thing here though is that I’m not replicating the purpose signifier. I’m not saying: this thing I’m linking to is an email, I am saying: I’m linking to that from here for this reason.
version: 2
seeAlso:
- op:23339416
- re:23341824
- v1:23339580
aliases: '24061508'
From this bit of metadata we can see that the current document is the second revision of a response to 23341824, which is a conversation that started with 23339416 (Original Post). I don’t need to say anything more than that to establish the chain of how this current note came to be, and where to go to find the rest of the conversation. Searching for the op ID in any conversation thread will always pull up the entirety of it, and any fork points, since every entry will reference it. The ‘op’ entry organically becomes the binding entry I referred to above.
Domains
Lastly the screenshot also demonstrates a concept I might have mentioned in the newer thread, that of domains. This was my solution to the problem of whether to keep one universal archive or to have separate archives for major life divisions. I went with using a field to establish that, and kept everything together. It’s a concept I use very sparingly, because there is a temptation to having it broaden its scope into areas that perhaps tagging and interconnections should instead establish.
Domains are primarily used to establish local token specificity. There are for example topical tags that don’t make a lot of sense in my larger personal archive, but in this data set, the LnL dataset, Communications.Public.Forums.MultiMarkdown, or M2.1.MMD, is very useful, as would be M2.1.Usage. Here the supposition is that since it is under the LnL domain, I can assume Usage refers to usage of our software.
If I were to be archiving both of those forum posts in a domain-less system, that would be far to specific, and both would probably be something much more generic like M2.1.Scrivener, vs M2.1.Reddit or M2.1.MetaFilter.
So that’s a good way to think about domains. If the scope of a very large area of one’s life is so narrow that there really only is one forum in the entire universe of it (or if that concept itself doesn’t matter nearly as much as something else), then what was once a useful high level breakdown becomes useless, and could benefit from a different kind of topical specificity.
Question: macOS warns me about renaming a folder with a name such as X.Y.Z. Adding the third component might cause the folder to be seen as a single file. Do you know of a workaround? Dashes or underscores, sure, but I wonder how Amber did it. I tried to use curly braces around the name, but this did not solve the problem.
I don’t know much about that to be honest. I would have thought that might only be a risk if the last part uses a registered package extension, like “.scriv”. I guess if macOS is getting picky about how you name your folders in general though, some other punctuation mark like dashes should be fine.
Sorry if I missed anything specific that you asked. I think I got everything, but if I didn’t, I’m always happy to expand a bit further!