Have searched in the manual and online… can’t see whether this is possible, please:
I’ve just completed a massive (several hundred) import of (mostly) text files from elsewhere into a Scrivener (3.3.1 on 13.4) project.
Although I have them all correctly placed in a hierarchy in the Binder that I’m happy with, I want to be sure that I haven’t imported the same file twice - and inadvertently placed a second one in another folder, thereby creating a duplicate.
Is there any way to detect (and ideally Reveal in Binder) and duplicated notes, please?
I fear that won’t work, though because any two duplicates (if there are any… it’s been quite a slog) will contain different such (long) chunks of text from any two others.
Is there a way that I can export (or otherwise safely get at ‘list’ of) all the names of all the Notes which are in the Binder?
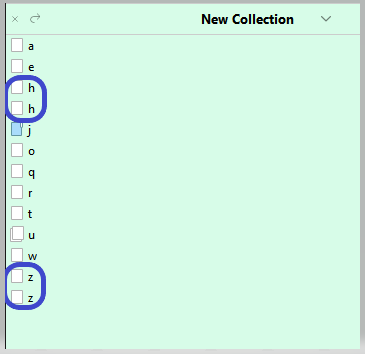
Then a simple sort would reveal duplicated Notes .
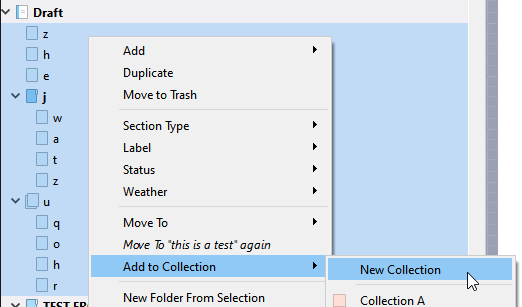
If your files have names in the binder, select them all, right click on one, create a new collection.
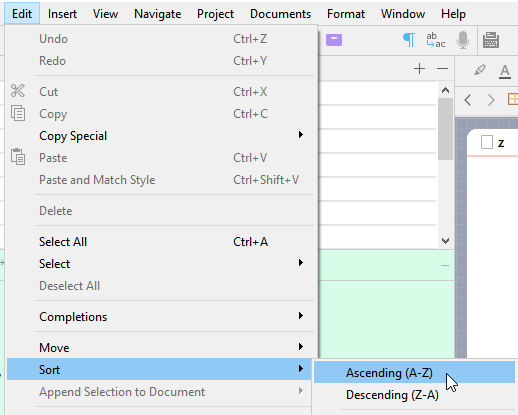
Sort alphabetically.
No need to export or compile.
You can also search as per my screenshot, but only for the title field.
Click the magnifier glass at the far left of the search input.
Click “title” from the drop down.
Search for your title.
For your first suggestion, why do I need to create a new collection? The snag is that I can’t see a way to sort Folders separately from Notes; and there’s every chance that I have the same duplicated Note in more than one Folder. So - as things stand now - no individual Folder appears to have duplicates inside it. That’s good: by Expanding All.
But there’s some chance that I have the same Note in more than one Folder
Sorry for not being clearer as for your second suggestion, if I understand you correctly (and thanks for taking the time and trouble to suggest this), I’d have to put each and every one of several hundred Titles in the Search box to see if each occurs one after another more than once. I just need to find any duplicate, I’m afraid.
You have to create a collection because Scrivener won’t let you destroy your project by inadvertently (or naively) reordering the binder alphabetically.
If this still doesn’t do it for you, then I guess I completely misunderstood the question.
Might try wild card search for 1 in titles As any exact duplicate might have a 1,2,3 etc. using wild card might show this. *1
Admit this a guess and have never tried
Thanks, @GoalieDad - the files I imported as New Notes were all added manually, so there was no prefixing of numerals that would have denoted duplication
While Windows doesn’t have this feature yet, there is a quick way to handle this on the Mac: set up your project search with the criteria you want and then also tick the “Find Duplicates” setting at the bottom of the search options.
What specifically counts as a duplicate will depend on your search settings, so e.g. if you search in “All”, you could have items with identical titles but distinct text showing up in the list. If you want to be more specific, limit the search to only that area you care about—so in this example, maybe duplicate titles don’t matter and you’re only interested in those with matching text, so you could set the options to search in Text only. If you use the All Words operator, you can search for * to find items with any text at all within the search-in scope.
You can check in section 11.1.3 of the user manual for a fuller description.
There is another Mac-only feature that is more useful when you may have duplicated text fragments throughout the binder, but not so much cases where the whole item matches another (a full duplicate):
Load the item you suspect has duplicated text elsewhere in the project.
Open the inspector to the Bookmarks tab (yeah, this feature was kind of shoe-horned in after the design was complete, it has nothing to do with bookmarks): Navigate ▸ Inspect ▸ Bookmarks.
At the top of the list of bookmarks, use the dropdown to switch from Project or Document Bookmarks to “Similar Text”.
In large projects it may take a few seconds for that to run. It will go through the whole search index looking for duplicate fragments of text and return a list that is sorted by how much fragmented text is found. So this will also find full duplicates by nature of how it works, but it will also find things that are almost duplicates, save for one or two words being different, or having a stray empty line at the bottom of the text, etc.