It sounds like you are using default settings to me, which are yes, tuned toward an audience that doesn’t know what HTML stands for and just expect something that looks roughly like what they formatted, no matter how messy it needs to be in order to execute that. You can probably see that there is a benefit in biasing the default settings toward that. Instead of you and three other people complaining about the HTML quality over the past four years, we’d have thousands upon thousands of complaints about how the compiler requires one to become a “programmer” (as some refer to HTML/CSS).
A key thing to know is that, internally speaking, Scrivener uses Multimarkdown to generate the HTML. So at a very basic level it produces pretty clean output—the more WYSIWYG style stuff you pile on top of that, the messier it will get (kind of out of necessity).
For those that actually care about the quality of the ebook at a technical level, you will definitely want to tweak some stuff. For one thing, I’d set aside the entire “Ebook” compile format. Use it as a frame of reference for the kinds of things you can do, if you want, but it was not created from a standpoint of adhering to bests practices, and uses techniques that produce undesirable HTML, like empty paragraphs with a br to introduce spacing, major sections starting with h2 level headings (and no h1 to be seen anywhere), using h3 for “subtitles” and etc.
Now if you want a very vanilla and semantically correct ebook with minimal work, try this:
- Scroll down to the enumerated checklist in this post, and go through it, up to step three.
- Instead of step four, since you don’t indicate using Markdown to write, you’ll want to have Scrivener convert direct-formatting (like font variations such as italics to indicate emphasis) to semantic Markdown. Click on the general options tab in compile overview, and enable Convert rich text to MultiMarkdown.
- Visit the Metadata, Cover and ToC tabs and set those up the way you want, and give that a test compile.
Since you mention using h1…h6 level styled headings in your text, you should find those work as you expect. Scrivener will convert them to Markdown headings, which ultimately are indistinguishable from any headings it might insert as structural conversion of the outline hierarchy. So all in all, that might produce a better result out of the box, for how you work, than the native ePub generator would. And because of that, you should find the automatic ToC works better with them, too.
If you edit the “Basic Pandoc” compile format, you’ll find a “Pandoc Options” pane, where you can set the ePub format to v3 (that really should be fixed to default to that, I’ll make a note of it), and a place to insert your CSS.
Say you have a dislike of Markdown and don’t even want to use automatic conversion or something, and really want to use Scrivener’s ePub generation. Well, as I say you won’t be able to escape that entirely since even the native generation uses MMD internally, the main difference between the two is that instead of having Pandoc produce the internal .epub structural files, Scrivener will. The HTML itself will be similar though—if you work toward that end.
So try this:
- Switch back to regular ePub ebook output.
- Select the “Default” compile format in the left sidebar, and set up some basic section layout assignments.
- There are some things we’ll need to adjust, so double-click the Default format to edit it.
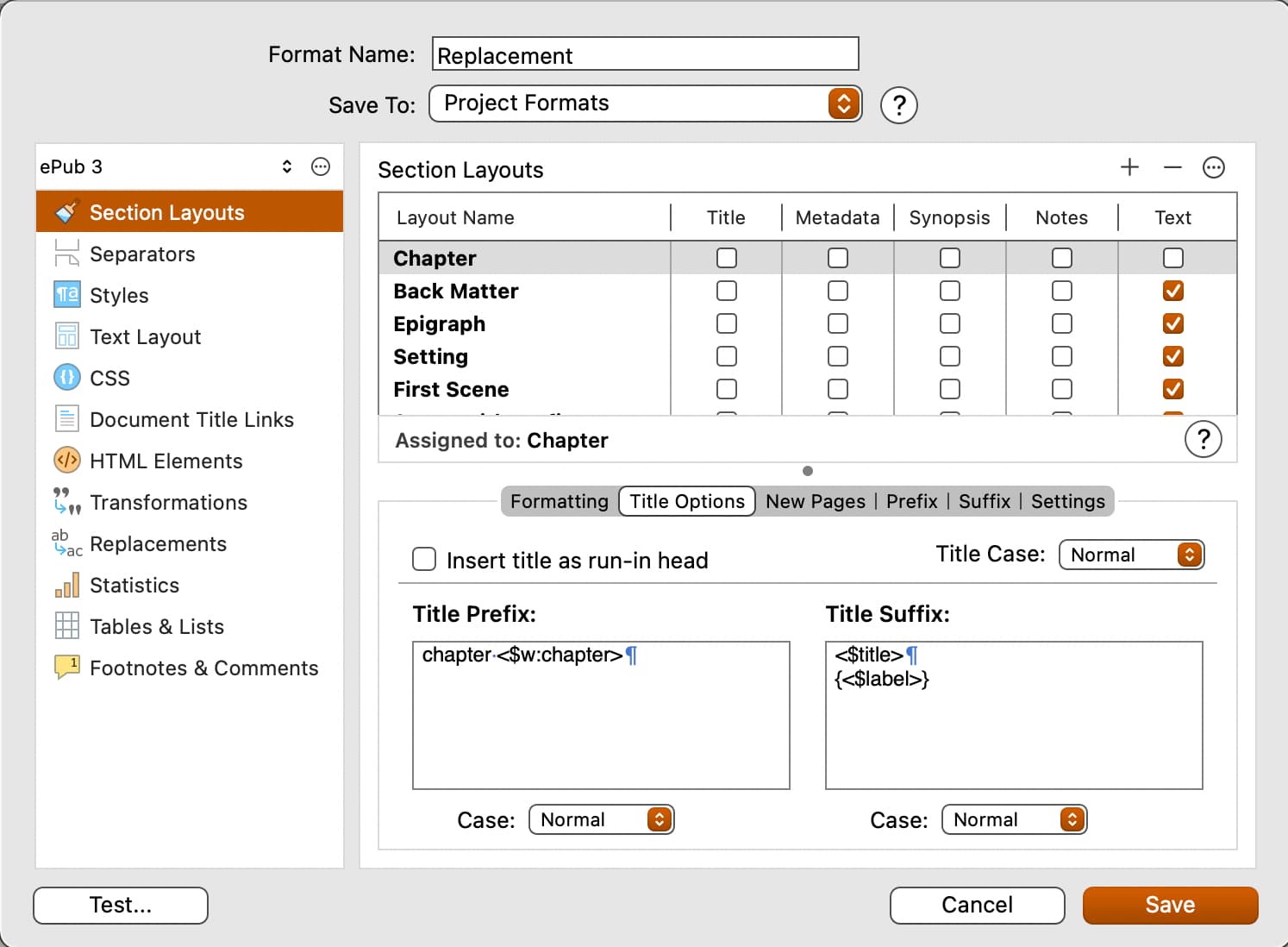
- In the Styles pane, create styles for any heading levels you want to have the compiler generate, beyond the ones you have in the editor. As you add them from the project’s stylesheet, you should find they are already set up correctly, so you probably won’t have to do much here.
- In Section Layouts, review the layouts you are using that have headings, and make sure to apply those styles to the sample text.
- In Separators, you’ll probably want to adjust the default “Text Files” to “Single Return”, and click through any of the bold Layouts to verify their settings. “Section Break” is what will cause an .xhtml file to be created internally. “Empty Line” you don’t want. If you really want spacing, you should use CSS for that of course.
- Next visit the CSS pane and disable Create styles for paragraphs using custom formatting, at the bottom. For the CSS, you can do what you want here. If you set the selector to “Use Custom CSS Stylesheet”, then the default styles will be printed for your reference, but they won’t be used—CSS will be 100% up to you, and if you leave it empty you’ll get vanilla output.
- Lastly, go through the HTML Elements pane, and if you use any of those styles, create them in the Styles pane first, and then assign them here. Appearance is meaningless for these special styles—setting “Block quotes style” actually causes the compiler to handle it as a Markdown quote environment, for example.
It may not be exactly what you want, but you can build up from that starting point, perhaps more easily than starting with a very opinionated format like “Ebook”, and trying to disable much of what it does.
I’d say you’re still going to have issues generating a ToC as you want with headings in the text, just based on how Scrivener generates HTML, but at least you won’t be stripping out piles for formatting. Again, the Pandoc Markdown approach is much more conducive to “inline” headings. I’d say the short pros and cons for each would be:
- Native: if you’d rather a generator create CSS for you, it’ll do a pretty good job of that based on WYSIWYG style inputs. You centre-align “Heading 1” in the styles pane, and it’ll look that way on output. With the Pandoc approach every single aspect of design is up to your CSS because what Scrivener actually generates is a raw Markdown file.
- Pandoc: overall if you prefer style-based and pure semantic writing styles, you will probably find this to be a better option. It is also easier to inject raw HTML into the output. You do much better thinking of document production as building a Markdown file. Styles are not for making things look a certain way, but making the text function a certain way, etc.
Both have their own unique learning curves, which works better for you is more a matter of preference I’d say, when it comes to that. If you want to wrap sections in divs for example, you’d go into the Settings tab in Section Layouts and give it a class name. With Pandoc, you’d use the prefix/suffix tabs to insert the HTML directly (though you’ll note it does wrap major sections in divs automatically).
To summarise:
OK - the fact is that Scrivener is horrible at generating an ePub document.
No, but with the wrong settings you can certainly make a mess of things.
Net result - a very nice ePub. Only, however, after many hours of sorting out HTML and CSS.
You may have to spend some hours in initial design—but honestly nothing other than template-driven junk is going to let you skip that part. The good news here though is that once you get the settings tuned to a baseline level of what you want, you can save that compile Format for future use, and fork from it with specific book designs, rather than always having to start over from scratch.
At least those hours will be productive hours, rather than hours spent tearing down unwanted output!