Is there a way to not count strikethrough text from this stat after compiling the manuscript?
I ran a test and compiled two words, with and without strikethrough and the returned result is 2 words. It should be 1 in this case.
It doesn’t reflect the total wordcount that is on the actual compiled manuscript so it is useless if you want to gauge the length of your published work.
So, I ask this because I have subscenes/beats within my chapters and I don’t like the idea of separating every chapter into little file chunks, it breaks my workflow too much.
Is it possible to do something about it? Just asking, thank you.
Hi.
I suppose that you actually want to keep the strikethrough text in your compiled output?
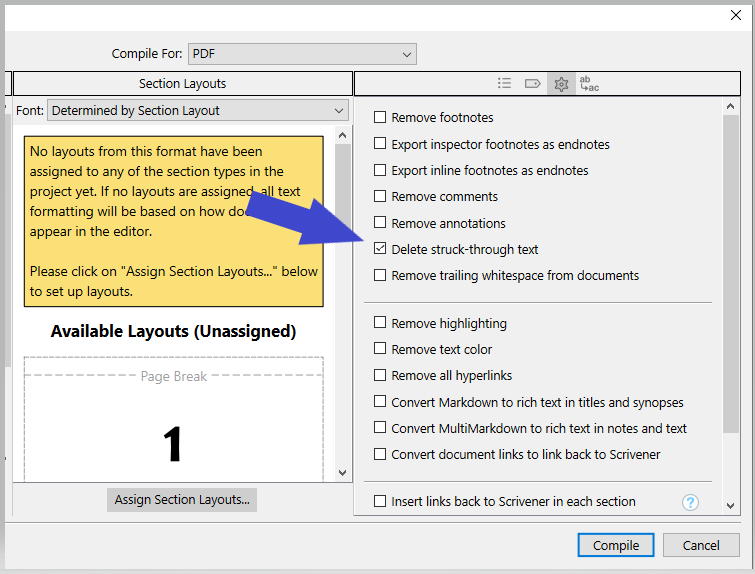
Because otherwise you can have it removed from compile altogether. That should give you the right count.
Another possibility would be to open the compiled file in a third party app, say LibreOffice, and have it select all strikethrough text, and then you note the selected wordcount and do the math.
Or delete the strikethrough text, note the wordcount, and quit without saving.
. . . . . . .
There might be a Scrivener function somewhere, but if so, I don’t recall ever seeing it.
I have it removed in the final manuscript, this I know how to do it but while doing so, it’s not giving the right count in the <$wc> placeholder after compile. It’s giving me the wordcount strikethrough included.
I don’t know though if I can have the word count in my Scrivener stats/files (so, before compile), without strikethrough. If it’s possible, it’s ok for me but I don’t think it is, isn’t it?
I don’t know, either I didn’t find anything or it just flew over my head.
Like I said, I did a test just to be sure, so I compiled just one file with two words : one with and one without strikethrough and, although there was just one word on the page after compile (so the strikethrough is removed, that’s not the problem), the count showed 2.
I have recategorized the thread/issue as a bug.
I don’t know what the devs will do of it (perhaps even recategorize it again), but it sure looks to me like it is not intended behavior. (Logically that placeholder should “happen” at the very end of the chain of operations. – Which is obviously not the case.)
Meanwhile, in your shoes I would just do with. Compile then manually replace the wrong wordcount with the one you get off of loading the resulting file in another app, or in a dedicated dummy Scrivener project.
If there is a better solution, I can’t think of any.
I don’t think Word Count has a way of determining what actually compiles, aside from reading in what’s marked or filtered to compile in the Draft.
There are other permutations users would require, all of which would require the placeholder to run a separate compile analysis to be exact, and I believe that would slow down compile by running a duplicate process.
Even without any choices, the code would run, and the experience would attract comments like: I used to be able to compile lightning fast, what’s gone wrong?
I think maybe the problem with this simple test is that the <$wc> placeholder itself is being counted as a word, so in fact you would have had a count of “3” if you left the checkbox off, and the count of “2” is the result of subtracting the one word that was struck-through. That is at least the result I am getting:
Here we can see the Markdown metadata being added also doesn’t get counted.
While this may not seem ideal, it’s more a side-effect of putting the placeholder into the main matter. By default anyway, the Statistics compile format option pane excludes front and back matter from the word count, and that is more typically where such a token would be placed (like on a cover sheet). Here is the same project, with the counter separated out to a different binder item in a front matter folder:
I did not give much details but the <$wc> placeholder was not in the manuscript but in the front matter (on a typical page with various infos to submit to editors).
Okay, I don’t know why we are getting different results then. Have you checked the Statistics pane to make sure the settings exclude front matter?
That +1 word tangent aside, I can’t think of a way to make removed struck-through text counted, on purpose anyway. I might need a more complete example to work from. Here is mine, maybe see if you can modify this to produce the result you’re getting, and then attach an update to your response:
Ok so that’s a bit unexpected, I didn’t know it worked that way.
I did some other tests with different compile layouts to make sure (like the default ones).
There is no problem with the strikethrough count. The problem here was that it counted the chapter number! There was a chapter number on the first layout I tested so that’s why I had two words.
On another layout, it even included the suffix appended at the end of the manuscript (like “The end”).
I didn’t expect that. I thought it only counted actual words in the compiled files.
So, here, case closed I guess, but it’s good to know. I guess if you have chapter titles and subtitles with quotes and everything, you want them to be included I don’t know.
Got it! Yeah, the line gets a bit blurry with that kind of stuff, which is probably why there is no one right answer. In non-fiction for instance, subheadings in the text are very much a part of the content, and contribute to its bulk. But even in fiction I think it is fairly common to count sectional wording in the overall. It’s a minimal enough shift to be of any substantial impact (unless I suppose you go for Victorian era chapter titles/paragraphs-with-a-number, but then that probably should be counted! ).