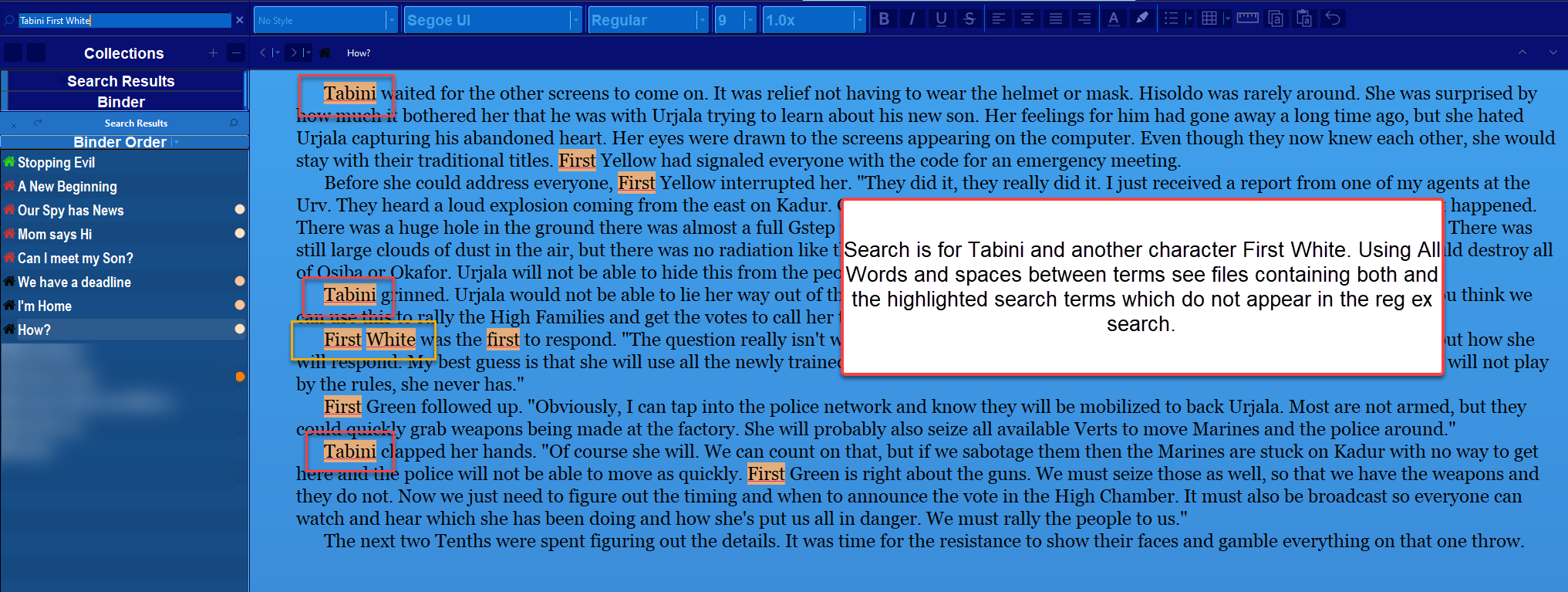
It would be very handy if there were a NEAR search (e.g. to find where two characters were speaking to each other, as their names are likely to be close together).
Since there is no such existing option, and expecting it to be non-trivial as a regex I asked GPT-4 for the answer. It works nicely, so nicely it would seem very easy to internalise and add as an additional search type.
PROMPT
Please provide a PCRE compliant REGEX to perform a case insensitive NEAR search for two words (using placeholders XXX and YYY for the target words) in any order, up to n words apart.
ChatGPT
A near search for two words in any order up to n words apart is a fairly complex regex problem. This pattern can be solved using lookahead assertions, lookbehind assertions, and non-capturing groups. This will ensure that the words can appear in any order and that there can be up to n words in between them.
To make the search case-insensitive, you can use the
iflag at the end of the regex. [Julian: Search seems to be case insensitive anyway. No idea how to force case sensitivity]Unfortunately, PCRE does not fully support variable-length lookbehinds, so it’s not possible to create a single regex that can match two words in any order with a variable number of words between them. We can create two separate regex expressions for the two possible orders of the words.
This is what those regex expressions would look like:
For XXX followed by YYY:
\bXXX\b(?:\W+\b\w+\b){0,n}\W+\bYYY\bAnd for YYY followed by XXX:
\bYYY\b(?:\W+\b\w+\b){0,n}\W+\bXXX\bYou would replace
nwith the maximum number of words that you want to allow betweenXXXandYYY. For example, to allow up to 3 words in between, you would use{0,3}.In these regex expressions:
\bis a word boundary. This ensures that the words match exactly and not as part of larger words.\W+matches one or more non-word characters (generally punctuation and whitespace).(?:\W+\b\w+\b){0,n}is a non-capturing group that matches up tonwords (surrounded by non-word characters). The\w+within this group matches one or more word characters.- The
iat the end makes the regex case-insensitive.Note that you would need to use both regex expressions and check for a match with either one to find
XXXandYYYin any order. Also note that due to the limitations of lookbehinds in PCRE, these expressions might not work exactly as intended in all regex engines. Specifically, they might not work in some versions of JavaScript and other languages that don’t fully support variable-length lookbehinds.