Early in 2022, I switched to the Mac Mini M1, with 16 GB memory, from an iMac27"-K5 with 48GB memory. It has been working smoothly, but since I run some VERY large projects in Scrivener it seems that I hit the memory-roof fairly often, slowing down response, and the project size makes an eventual re-indexing hours-long.
So I am considering upgrading to a ‘Mini’ with more memory, and that means for me that the Studio with 64 GB memory would be affordable and powerful enough!
Still, maybe Scrivener does not really use a lot of cores? So why pay more for new idle hardware?
So I just wonders if anyone out there have experience to share with me, concerning this ‘technica’ question.
Can you give more detail on what you consider “big”? I ask because I once imported the bible from Project Gutenberg, split it down by book and chapter. When I load up the entire thing in Scrivenings mode on my M1 MBPro with 8 gigs of RAM, it takes about 3-4 seconds to display about 800,000 words. It scrolls pretty smoothly, and doesn’t seem to be struggling at all. I don’t have any images embedded in any of those files, and the total size of the project appears to be about 12 MB.
So it’s pretty “big” in word-count terms, but not so much in bytes. Either you’re using Scrivener as a massive database, you have lots of embedded pictures in your documents loaded into a Scrivenings session, or your project has some kind of corruption issues… Rebuilding indexes on my project took less than 3 seconds, so hours on an M1 seems ludicrously slow.
Checking the writing history of one of the largest Projects I get this:
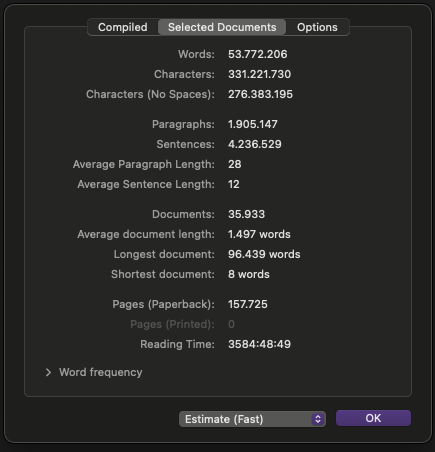
729.000 words in a file of 87 GB.
(If instead you go into Project/Statistics on such a monsterfile it takes LONG time to count!)
There will nearly always be pictures (photo/diagram) included. As simple as a webpage may look with photos shown as maybe 200 by 150 pix, there is often a fullsize jpeg behind. As modern cameras gets better sensors, files from a pro camera will be about 4000 x 3000 pix with a filesize of 45 MB… and people just place the fullsize jpeg and then scale down to fit the place on the page, but the filesize is NOT reduced… so the scrivener project increases on the disk.
The Internet is mostly fast (I have fiber) and disks are cheap, as such and getting larger, so why would they bother really?
Rebuilding index can be a prolonged process, but sometimes it is necesarry to perform (Alt Cmd S), and this is where I can see on the system activity monitor that Memory is constipated (and Scrivener stops, sort of).
I have never faced a problem like yours—and admittedly my projects where never that big. But speaking from my experience as a longtime Scrivener user for more than once it were “bad” imported files or content pasted from a web source that has caused trouble.
So my suggestion is to create one or even better a number of duplicates of one of your huge projects. Make sure (SURE, in capital letters) that you by no means confuse one of the duplicates with you actual projects and that you have plenty of backups.
Then delete parts in one of the duplicate projects. If you start doing that on a smaller or a larger scale is up to you. If my theory is right this way you might be able to locate the foul data or at least the area of your project that causes Scrivener’s obstipation.
And if it is the sheer number of removed files that gives relief that means back to the question others have asked here before: What else is going on on your M1 Mini?
Which version of macOS are you running? Monterey had some memory leak problem that to my knowledge is fixed in Ventura.
I better make this clear: Scrivener IS performing perfect on this huge project, and I have not encountered any kind of ‘corrupted’ data in the project. I deliberate push the limits, because it fits my purpose.
You can see this mega project as a combination of 4 projects. I use it as the look-up file cabinet:
“Was this subject mentioned before, and how many times?”
Searching in one project is faster and more efficient than running same search on 4 separate projects.
My concern is based on the (visual)data from the Activity Monitor, where Memory usage, clearly tends to hit the roof if I am not careful. This is my reason for wanting to find out if others, with a Studio and at least 32 GB Memory… experience hesitant performance from the Mac.
I run MacOS 13.01 Ventura and uses a Pegasus 3 R4 12 TB RAID for storage. The internal ‘disk’ in the Mini is 1 TB.
I happen to have a MacStudio with 64 GB of RAM, but I don’t have a Scrivener project that’s anywhere near the size of yours, so that’s probably not going to help you much. I find that my MacStudio is oversized for Scrivener (or really pretty much anything else I do, to be honest).
The question I would ask is if your project has to be this way or if you wouldn’t benefit from some of the things others mentioned in this thread, e.g. @drmajorbob
Good to know, that there are users running Scrivener on the Studio.
I have found out that running these larger project is a good sensible solution, for my purpose, and must repeat that I still experience Scrivener to perform excellent, under the given conditions.
I do quite a bit of photography and some video so the Studio may be a nice capable ‘oversized’ solution for me
Yeah, if you’re editing photos and videos, I can see this being a nice machine. I rarely do that, though. So far, anything I’ve thrown at it has been dealt with swiftly as if it’s asking me “is that all you got?” It’s the version with the M1 Max, btw, not even the Ultra.
If I’m reading your stats right, you have 53 MILLION words of text in your draft folder alone!? That explains the long indexing; the index is an unformatted copy of the text of your entire project (even stuff in your research and trash folders), so it’s having to go through and strip out formatting and then copy all that text, and then store it somewhere (I’m not sure where, or how the index is used generally).
You could benefit from a larger amount of RAM, but quite frankly, I think a Mac upgrade is going to give minimal benefits to performance. Scrivener can handle what you’re throwing at it to an extent, but your usage looks like someone using a (very good) spreadsheet to run Amazon.com’s inventory system.
You really should look into alternative tools for your warehouse of data, such as Devonthink (or others, but I can’t think of what alternatives there are at the moment)–you’ll get a lot better boost in performance if you offload your research, or whatever all that data is for, to a tool or set of tools designed for that volume of data.
I completely agree… I had that expectation on several occasions, that now, was the time for a REAL database tool… but everytime I have become amazed over the simplicity of the way Scrivener handles it.
SO yes, I am totally outside the box… and it is my perfect tool.
I know of Devonthink, tested it for a while, and then came Scrivener along, because I needed some good tool to write ‘THE BOOK’ … and it came naturally to use scrivener also for gathering background info… and now… it has grown
I have worked with ‘Real’ database tools, in my earlier PC incarnation, where I guess I spent most efforts in setting up the database rules, only to come back to my core competence, the spreadsheets.
I am fairly sure it was never on the mind of the Scrivener team, that anyone would want to write a book of 157.725 pages… and the quality of the design of Scrivener contains this too. Amazing to have such a tool at hand.
But if a project is 53 Million words and 87 GB, our advice is almost always going to be to slim the project down before spending money on hardware. That’s probably the largest project I’ve ever seen “in the wild.”
For images in particular, you might want to take a look at any of the purpose-built image database tools that exist.
It has become huge, and I see it as a challenge (for the software), Who blinks first? Me or Scrivener.
But bear in mind that this huge project represents a ‘Total’ of about 5 years. The day to day projects contained in it are, relative smaller in wordcount.
I rely heavily on the use of Custom Metadata, and those are the only ones that may be added/changed in ‘older’ projects.
For the general ‘more 2 dimentional’ look I sync project to Aeon Timeline. In Aeon it is possible to make queries based on boolean-like input between these metadata types.
I dont do that on the big one, even if it could be done I cant take in such a enormous matrix… but otherwise the combo is great. Syncing may go both ways.
When I feel the time is available I find the documents with the huge photos, scale them to 400 pix and take a screenprint of that. Then I replace the original photo with its screen-twin. And the whole project is trimmed that way.
Suggesting DEVONthink as the proper research tool for you is what came to my mind too. Using it together with Scrivener makes a very fine combo I have been using for many years.
If you are interested you should not wait until next month because this month you can get a 25 % discount (but no stocking).
Spliting the humungous project into its four constituent projects perhaps you could do that same search using Spotlight. If that doesn’t provide what you want then some KWIC utility run over the project(s) files would. FSF/GNU’s ptx utility (part of their coreutils package Coreutils - GNU core utilities) does a reasonable job of producing a concordance. Otherwise you could use a corpus linguistics tool such as LancsBox #LancsBox: Lancaster University corpus toolbox which can read RTF files as standard.
I suspect that much of your problem is that of the almost 58million words in this project is the images you have in the Project. Last time I looked Scrivener will convert images to RTF files reconstituing them as required (without loss of quality). But the problem is Scrivener will then try to index the “text” it finds in those RTF files.
By the way, 58million words is over half what many of the very best available corpora have available. The two British National Corpora (BNC1994 and BNC2014) each have 100millions in them!
I dont see any indexing of any image to RTF convertions happening!! And find it difficult so see any benefit Scrivener would offer doing such an extraordinary job. Neither does Activity Monitor show any peakings in CPU use.
Just testet one document with 625 words counted in statistics. Added one fullsize photo of about 40 MB.
Quit scrivener and started it again, The document was still 625 words.
I know that Devonthink is a fine tool. But in this specific case it is not practical to use.
Overall Scrivener is the perfect tool to use, for me, for these kind of jobs.