Suppose I create a new Scrivener document using the General Non-Fiction (LaTeX) template. Then, I type the following into the Section text under the first chapter:
There is a 10% decrease in my enjoyment of Scrivener when I need to type percent signs.
Upon compiling this document, the first chapter contains only the following text:
There is a 50
Simple fix, right? I follow the lead of the LaTeX (Memoir Book) format that converts my quotes and em-dashes using Replacements, and add one more to change all instances of % with \%.
Nope! Now all the raw LaTeX code in the Frontmatter and Backmatter gets messed up because all the comment characters are escaped.
I’ve tried to resolve this using a new Style for LaTeX code that I “Treat as raw markup”, however that seems to make no difference. Those % signs always get escaped.
Is there a way to retain the % signs I write alongside my text by escaping them using Replacements, but not apply those Replacements in the LaTeX code that appears in the frontmatter and backmatter?
My existing workaround is to not bother with the Replacements, and manually escape (or format) every % that I type. But that feels…yucky?
I have to say this is not something I’ve been able to solve. I would be nice if Scrivener had a way to tell it to ignore certain documents for replacements, or ignore front/back matter. AFAIK, not available.
What I have done for a long time so muscle memory is working, is to write things like
79%percent
and in compile replacements:
replace %percent with \%
which results in the final document output from the LaTeX compiler:
79%
Concatenating % and percent avoids any singular use of “percent” to be erroneously replaced.
Works for me and have used this technique for many years so I’ve gotten over any "yuckiness’.
I’m not using any fancy stuff with Pandoc, only the really nice “General Non-Fiction (LaTeX)” which is provided by Scrivener. Might be some fancy stuff in the Pandoc approach, but I have never had the need to pursue that.
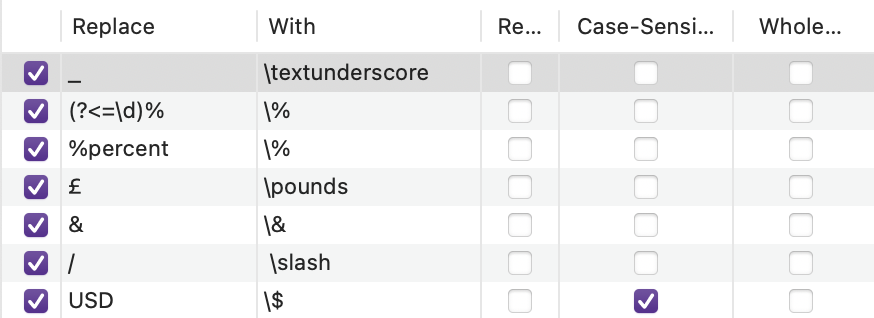
Another potential solution: couldn’t your replacement be a bit more “selective”? You want to escape when % is preceded by a number but not a newline or non-number character, a regex replacement like (?<=\d)% could handle this distinction:
I forget if Scrivener’s regex suppports lookbehind rules, but we can rewrite it to use groups if it doesn’t. Maybe there are comments that also sit before a number but it seems unlikely?
I vaguely remember trying Regular Expression years ago, but they tend to hurt my brain so I have no real experience with them to suggest.
I did try your suggestion and the compile test resulted in just removing the % when I entered 79%. Maybe I have to say something in the “replace” field to tell Scrivener it’s a Regular Expression?
You do need to ENABLE the regex option in the replacements for the regex to work, you didn’t select it in your screenshot (Re… column).
The (?<=\d) means that you look behind (?<=) for a digit (\d); this is not actually selected but “guides” the regex. Then comes the % character which is selected by the regex, but only when the lookbehind rule is satisfied. It is very elegant, but yes regex is a language which isn’t easy to learn. That is why I love the regex101 site, it breaks doen the regex meaning for you. I just checked the Scrivener manual and Scrivener uses the ICU regex engine, which does support lookbehind rules:
Regex is elegant yet obtuse!
Here is the group solution as a FYI
It uses (\d)(%) – two groups one containing a digit and one containing a % – the replacement ($1\\$2) injects group 1 then \\ and then group two to turn 55% into 55\%.
There may be some other incantation to stop replacements via some compile setting (i.e. don’t apply replacements to front/backmatter), but I don’t remember if there is. I would like a place in the manual that clearly specified the order and precedence of the many compile steps, I don’t remember this visualised anywhere at least…
Well, just demonstrated my lack of usage (and perhaps interest) of Regular Expressions!
I did check “on” the row with the Regular Expression and compiled again, and the result was the same–the % character disappeared. I’ll let others get involved with debugging (if that and not me is the cause) the Regular Expression. My simple work-around works for me. I have no doubt I could have done something wrong with the Regular Expression.
Thanks for the suggestions re: Regular Expressions. I had considered messing with this, but worry about it being delicate, and introducing surprises down the line.
In practice, I don’t actually use the included LaTeX template. Rather, I make my own for writing papers using specific conference templates. To do this, I just copy and paste a whole bunch of boilerplate into the Frontmatter and Backmatter. My concern is that these files might introduce % characters directly after numbers. When something goes awry, I’m stuck chasing for needles in a (possibly) large haystack.
However, I managed to relieve my anxiety a little: grepping around the last few conference templates I’ve used reveal no matches for such a pattern. So I guess that regexp will have to do for now.
An alternative pattern is to create an inline “escaped character” style that I apply inline while writing for the handful of characters that show up now and then. That solves the much larger problem that is the &, which will absolutely fail to survive a regular expression as it’s also used as a separator in tables and equations.
Anyway, while I have a solution/workaround for my immediate problem, I find it odd that replacements are not disabled in the regions where we’ve asked Scrivener to “Treat as raw markup”. I really would like a “Just pipe this file, contents untouched by Replacements, directly into the result” feature. But I know that’s probably non-trivial to solve in the app—especially because I also expect things like <$projectTitle$> to be replaced in such files. I imagine that’s driven by the same process.
Edit2: row was and is “active” and RegEx check on. Same result. The LaTeX source is “79%”. So I conclude my lack of success is the creation of PDF as in the source LaTeX the 79% shown as expected, but in resulting PDF stripped out. Using “texmaker”. Must be a setting in texmaker somewhere. But the Regular Expression definition you provided works. thanks!
Edit3: I went back and looked how my replacement “%percent” shown in the LaTeX source. It’s escaped with a \ as in 79%. So the RegEx missing a \ in the replacement. On closer inspection you gave the answer. Two backslashes in the “With” column to get one escape!
That is certainly an option I have considered before. However, there is a great deal of project-specific text I need to intersperse in those areas. For example, it is not uncommon for the abstract to appear somewhere mid-way between the start of the template, and the beginning of the document text. This opens up a nifty way for me to keep all the crazy components organized, and editable from one place.
In Scrivener, I create folders in the Frontmatter that encapsulate these logical chunks of document setup and content. So I would make—among others—a Preamble folder with all the \usepackage and page setup nonsense, and an Abstract folder containing three items: (1) a LaTeX snippet that opens with the relevant control bits and metadata, (2) a rich text document where I actually write the abstract text, and (3) another LaTeX snippet that closes it off.
This approach is really handy, because I can use Scrivener’s full feature set while I’m hacking an abstract together, and then cutting it down to the prescribed word count set by the conference organizers. Things like snapshots, having alternate options that can be toggled in and out of the compile, and turning my rich text into the right control sequences, all make life easier while I stay focused on the task at hand. Also, if the LaTeX code needs some changes I’ll be able to find it more easily to make those tweaks. (Seriously—there are some super dense templates out there that rely on comments to maintain structure, and it’s far too much to deal with IMO. Introducing structure like this is a godsend!)
Another thing is that I like how I can use placeholders (like <$projectTitle$>) that make this all template-friendly whenever I start up a new project.
Is your starting (and perhaps ending) point the Scrivener Template “General Non-Fiction (LaTeX)”?
I use that, but over the years have tweaked a few things, but basically still relying on that. The instructions given in the Template are terrific (concise and correct). I’m pleased with how it does table and figure numbers, table of contents, indexes, etc.