RexEx searches are incredibly useful, but Scrivener beta 26 still has a number of issues.
Certain searches producing unexpected results:
I use b[/b] or b[/b] to locate paragraphs starting with a space character. In beta 26 documents containing these are not listed on the left-hand Search Results column, but occurrences are highlighted in the documents themselves.
This has to be a bug.
Last off, a plea:
Please give us a way to locate soft line breaks. These little nasties creep into my manuscripts somehow and I need to find and eliminate them.
This comes up often. Scrivener is using the regular expression syntax (QRegExp class and the QRegExp::RegExp2 style syntax) described at the following URL: doc.qt.io/qt-5/qregexp.html
Most likely your regular expressions are not compatible with this syntax.
We plan on jumping to QRegularExpression class(which is a more common and Perl compatible style syntax), but this is not going to happen soon.
Testing your RegExp seem to work and return proper results. The only problem I can think of is that your documents are not within the current filter settings. Play with the “Search Included/Excluded Documents” Options in Binder search.
If nothing helps, feel free to upload a small demo project demonstrating the issue.
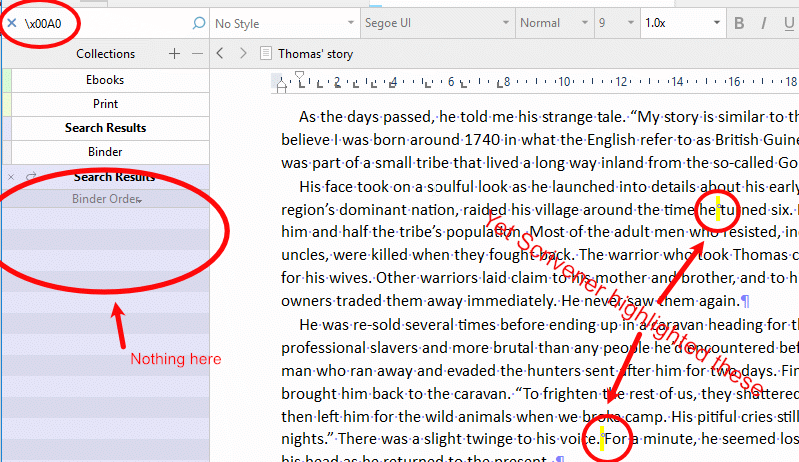
I hope this illustrates the issue.
This time I have chosen to search for non-breaking spaces in my manuscript. These have Unicode x00A0. As you can see, Scrivener finds these and highlights them inside the individual documents on the right, but the document names containing the hits fails to manifest in the Search Result list on the left.
Note, this only happens when one searches for “unusual” things.
I have tried playing around with the search settings without success.
Please, come up with a different example, as Non-Breaking spaces are special(in some search cases they are treated as normal spaces). Your screenshot also does not show the current search operators, although I assume this is not a problem. Still I appreciate the Non-Breaking space example, but I will need a different use case to test and fix any issues here.
Please, also have in mind that in some cases the current document search and the global project search might return different results, depending on the search criteria. This is due to the fact that Project Search is searching a database file which contains a plain text version of all your documents. When you search within a document, you actually search within the current document contents. The two searches although similar, are indeed different as they search in different data. This is done to speed up project searching and avoid loading all your project documents upon search, which is extremely slow. Because of this some special type of searches and special character searches might return different results.
If the searches are dramatically wrong, you should also run File > Save and Rebuild Search Indexes, which will rebuild the search database, which might end up with different contents in case Scrivener or your OS crashes for example.
I suspect my problems stem from the current document search and the global project search differences as you suggest.
Nonetheless, this is a major problem for someone like me, as non-breaking spaces, spaces in front of paragraphs, and soft line breaks crop up in my documents and need to be weeded out.
I really hope a way for this to be addressed can be worked out, for example by offering a ‘slow’ global search option.
Nonetheless, I’m including a couple more examples in case it helps. Note that these are all ‘special’ types of searches.
Same issue as my first example and probably the same cause.
This one is a bit more curious.
The offending document, i.e. the one containing a space in front of a paragraph is NOT listed, but multiple other documents that do not seem to have the issue ARE listed. The ones listed contain various items such as 1) a single bitmap image, 2-3 lines of text for a title page, etc.