The Windows version provides this option. I hope it can also be provided on macOS. Is there any difficulty in implementing it on macOS?
For users of Chinese, Japanese, and Korean, this is a relatively accurate word count method.
Alternatively, a new CJK word count algorithm could be introduced, enabling it only for users of the corresponding languages.
In CJK, one character is considered a word, and multiple characters together form a phrase, but current statistical methods treat the phrase as a word for counting.
This is the CJK block in Unicode, where a character in one of these blocks needs to be treated as a word for statistics.
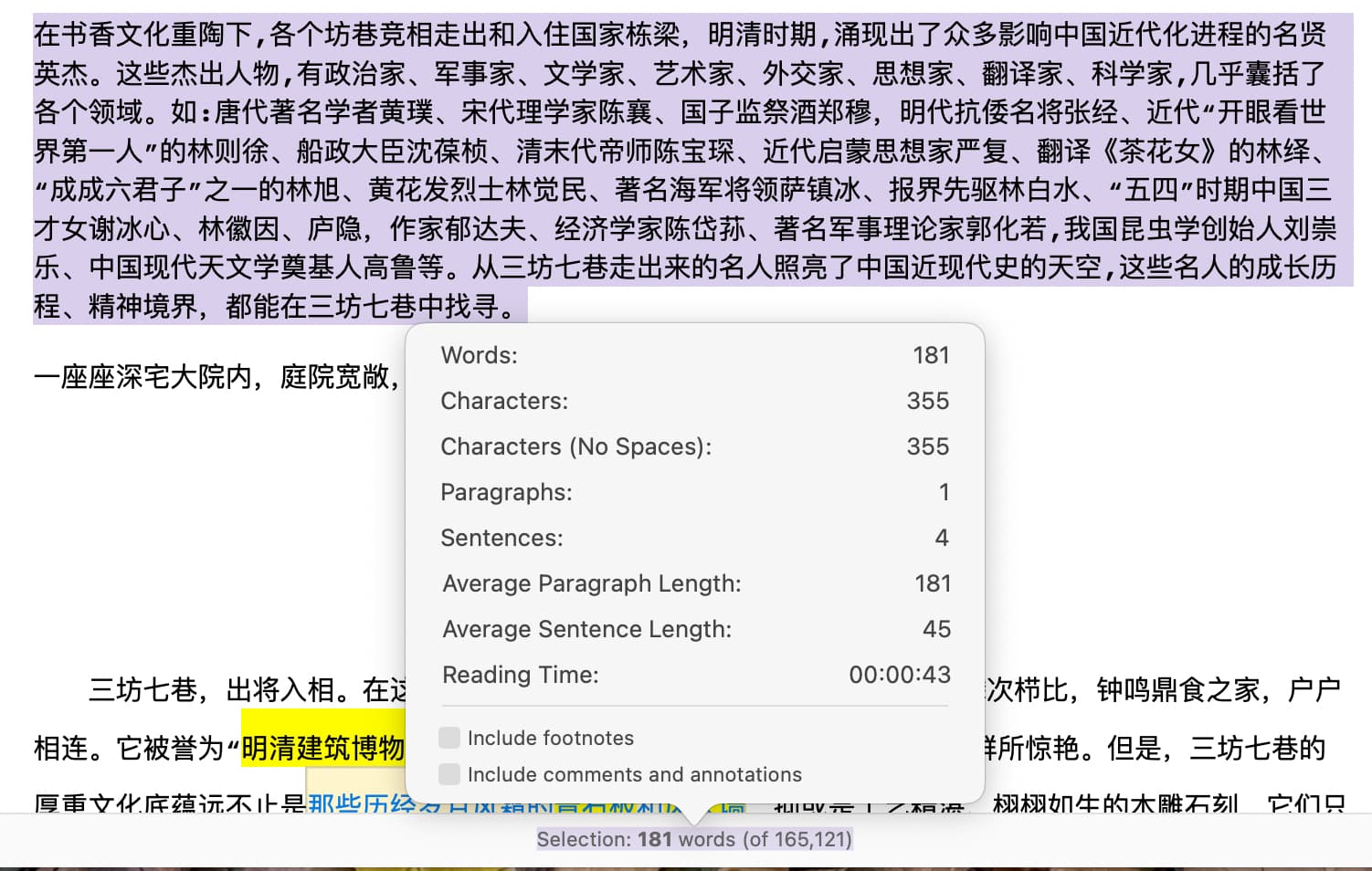
When submitting novels to publishers and websites, they have word count requirements. The character count (no spaces) is quite close to the requirement, but it still counts punctuation marks, so it’s not entirely accurate.
Papers and research reports are the same.
It would be best to achieve accurate CJK word count statistics, but if that’s not possible, placing the character count (no spaces) at the footer bar can also be more convenient.
This count is not accurate, not an industry standard, and cannot be used.
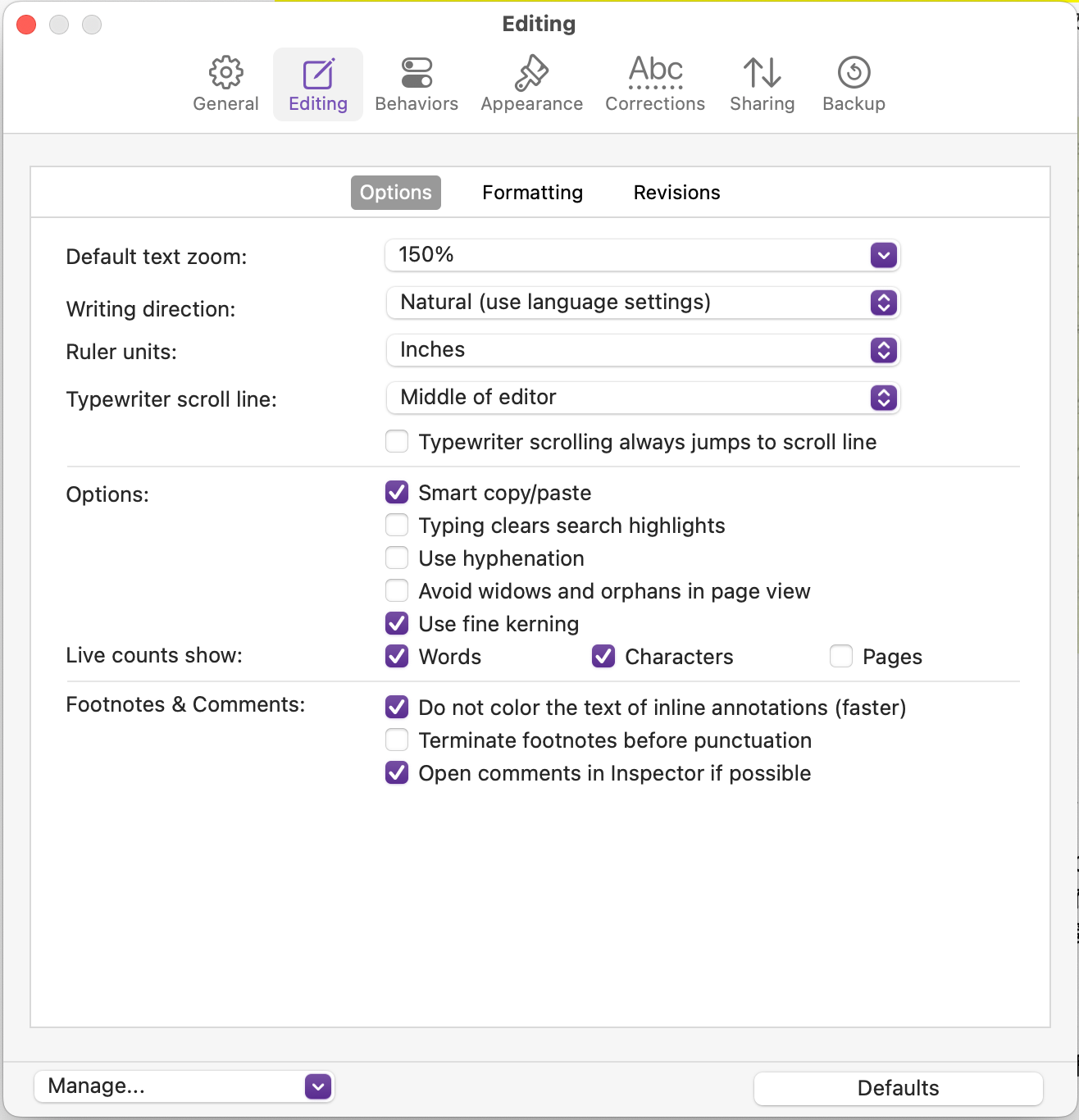
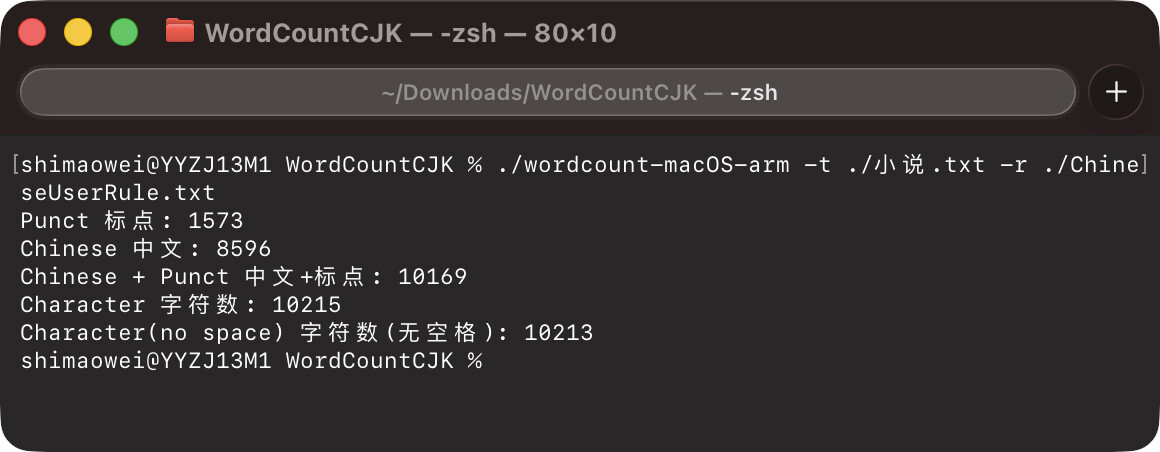
I just implemented a command-line counter that can take in rules and text, quickly count and output the results.
Word Count CJK Tools: WordCountCJK.zip (1.0 MB)
usage: wordcount-macOS-arm -t textFile -r ruleFile
I want the result to be Chinese 中文: 8596, not characters: 10215 or characters(no spaces): 10213.
The macOS version of Scrivener tells me the word count is 6108, and the Windows version of Scrivener tells me the word count is 1030, both of which are meaningless results.
It looks like Scrivener word count as the same as the following regular expression
macOS version characters (?s).
windows version characters .
characters (no space) \S
Now just add a regular expression to count CJK characters (?=\p{scx=Han}|\p{scx=Hiragana}|\p{scx=Katakana}|\p{scx=Hangul})(?=\p{L}|\p{Nl}).
and all Punct \p{P}.
And add them to form CJK characters(with Punct).
Your original post was to ask for live character counts were not provided in the Mac version, when they were in the Windows version, so I showed you that it was already available.
I am not going to bother counting the characters in my selection, though clearly it includes punctuation. Equally obviously, I cannot comment on the word counts provided by Scrivener for your text, though I wonder if for some reason they are only counting a selection within the whole project.
I can’t talk for what Lit&Lat may respond (especially given their current development priorities).
Careful. CJK is not just C. Scrivener counts 나무늘보 as 4 characters / 1 word, which is correct. (Maybe C and J need a better algorithm, but K works just fine as it is.)
Japanese also can (and often does) have more than one character per word.
For translation tasks, one English word per two Japanese characters is a decent rule of thumb, though the exact number will vary depending on the material.
Understood, I indeed don’t understand Korean, but I use both Chinese and Japanese simultaneously, and they both share Chinese characters.
Microsoft Office Word tells me that even if a Japanese word needs two characters to have a basic meaning, it still treats it as two words.
What’s being discussed here isn’t the academic meaning of a word, but what the recipient considers a word when delivering, at least in China and Japan, one character is considered one word.
I think you are conflating two different concepts.
It may very well be true that Japanese editors specify their desired manuscript length in characters.
But it is absolutely not true that each individual Japanese character represents a word linguistically.
(Why does this matter? Because we are having this conversation in English, where ‘character’ and ‘word’ are very different concepts, and conflating the two will just confuse everyone.)
OK.
But things aren’t that simple. The editors didn’t actually count the number of characters, because English words and numbers are still counted as one word per word.
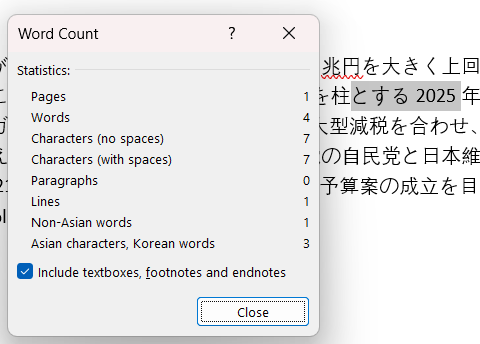
In Microsoft Word, “Words” = “None-Asian words” + “Asian characters, Korean words”
“とする2025” is 4 words.
If you want to avoid conflating word with character , you could introduce a new counting unit called Zi or Ji.
In Chinese and Japanese it can be written as 字 , and you can allow users to enable it if needed.
Word counts
日本人です
[(understood subject) is a Japanese person.]
as five words. (Mac) Scrivener counts it as 3. A sentence parser designed for Japanese treats it as two words, ‘日本人’ and ‘です.’
Based on the plain meaning of the sentence, I would say that Word is wrong, and treating kanji characters like ‘日’ the same as kana characters like ‘す’ gives nonsensical results.
You might be right.
But now Scrivener’s algorithm for counting Chinese and Japanese characters differs from other editor, and they have become the de facto standard.
Unfortunately, your correct result is meaningless; no one needs to know how many Japanese words there are, they just want to know how many kanji, kana, and English words there are.