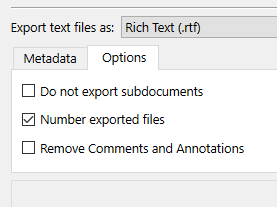
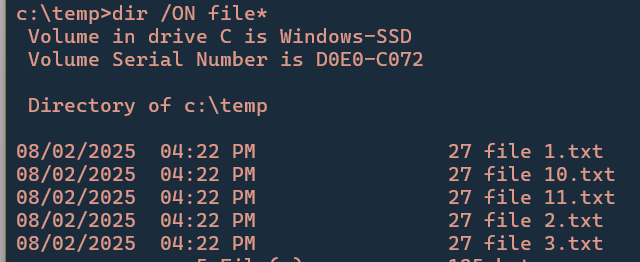
Please give numbered exports leading zeros, which would allow a file-explorer sort by Name, Ascending to work correctly. I.e. if a novel has 100 scenes, the exported scenes should be named 001 Foo.docx, 002 Bar.docx, … 010 Zoinks.docx, … 100 Finale.docx. This allows a flattened folder structure to sort in the correct reading order (otherwise the sort-order yields 1 Foo.docx, 10 Zoinks.docx, … 2 Bar.docx, etc.).
Some beta-readers and analysis tools need an easy way to order scenes. Lexicographical sort helps here. (See also feedback re. numbering folders and chapter-header parent documents.)
If you don’t get what you want out of the auto-numbering from File / Export / Files..., you should compile instead.
That’ll give you a single consecutive/continuous file, with complete control over the numbering of parts/chapters.
Easy to chop in smaller bits, if required, after the fact, for a beta reader.
This is a bit of a rabbit hole, but I think I can give you a helpful solution.
Scrivener can sync to Obsidian via a sync folder. To accomplish this, it generates .md files that have appended numbers for ordering in a flat file system such as Obsidian’s. You could then zip up the Obsidian .md files (which are just plain text files) and send them on to your collaborators. Your collaborators could then move them into Obsidian (or similar) for reading, and they’ll be in the correct order. Or, you could use a cloud syncing method to share the Obsidian files with your collaborators (Obsidian offers a paid cloud version, btw, that might suit for collaborating).
You can read about sync folders in the Scrivener manual at 14.3 Synchronised Folders.
As a note on the issue itself, yes this is less a feature request and more a note on how a particular checkbox implementation was never completed. It has always been meant to zero pad, to whatever level is necessary within each folder that files are exported into.
On the other hand, the external folder sync feature also supports RTF file syncing, which may be a more familiar environment for readers to work with, and add comments to. If one can convince others to use this approach, it is may be ideal for the OP, as comments will sync into the project directly, rather than having to import the notes and look up where X, Y and Z is in the originals.
Yeah, I’m suggesting we don’t rely on that. I’m not sure which of my collaborators seeing the export folder are using which tools, OSs, etc., and when. Amber’s file-syncing is a great suggestion, but it too presupposes workflows/toolsets less universal than the zero-pad idea.