I’d honestly be terrified for said project to get corrupted or lost somehow! ![]()
Honestly though, omitting the actual text, having one Scrivener file that leads to a bunch of other Scrivener files - an organizer basically - seems smart.
I’d honestly be terrified for said project to get corrupted or lost somehow! ![]()
Honestly though, omitting the actual text, having one Scrivener file that leads to a bunch of other Scrivener files - an organizer basically - seems smart.
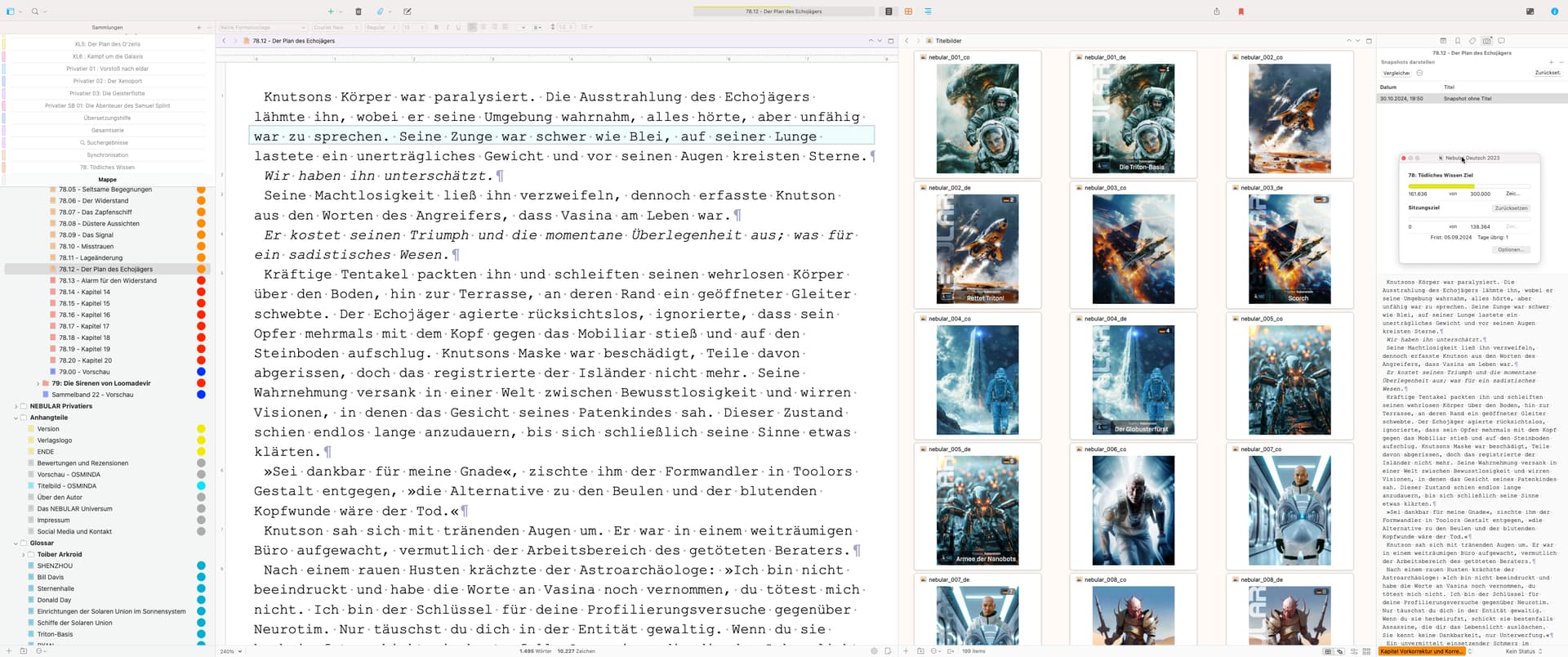
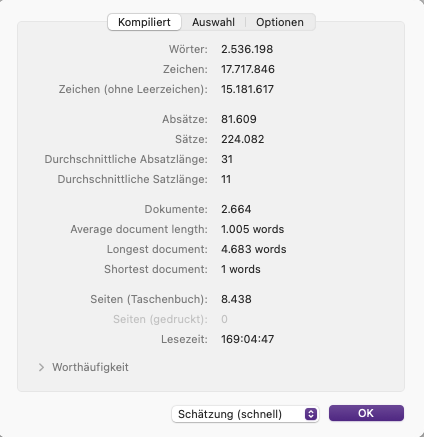
One reason why I have always favoured Scrivener as my writing software is the fact that even large amounts of text can be managed without a loss of performance. So far, there has never been a data crash, but I also have a consistent backup strategy. Here are the statistics of my SF series, currently 82 individual novels plus cover images and illustrations in one project file.
Backups, Backups, Backups, not just what Scrivener does automatically. Backups on another (external) hard disk are the best life insurance.
“large amounts of text” is relative. Your project has around 2,600 documents. My experience is that “without a loss of performance” ends at around 4,000 documents … unfortunately.
This project shows clear performance problems. This is just an observation from my everyday work with Scrivener, not a reproach.
The number of documents is 3800 and no, it does not show any performance issues. This is also what I can tell from my daily work with Scrivener.
There is one thing to consider. I was planning with a huge project file from the beginning and so I did setup my mac. My M1 Max has 64 GByte of shared memory.
Ich habe fast 50 % mehr Dokumente als du, oder verstehe ich etwas falsch? Dort beginnen die Probleme. Aber dein üppiger ram ist sicher von Vorteil ![]()
I would expect that the document with 298,160 words would have performance issues, as would any others in that range. Scrivener is designed to work with much smaller chunks.
This is hardly a new topic, if someone is interested in the nuances there are other threads that can be looked up, but I split it off from the screenshots thread to avoid it getting too derailed.
In my experience, actual corruption is extremely rare, and has little to do with the size or complexity of the project, it could happen to projects of all sizes. In most cases such things are the result of improper use of transfer technology like cloud services—i.e. the “corruption” (it’s not, really, but in a very colloquial sense we might think of it as such) isn’t happening in Scrivener, but as the data is being copied from one machine to another (or not, which is often the case).
That might seem to fly in the face of the advice to not put all your eggs in one basket, but a very important thing to consider with Scrivener is that it already doesn’t do that by design. It uses hundreds if not thousands of separate files for each project, so it already is spreading out everything to keep it safe and performance high. It’s doing that for you, and making it easier to manage such distribution than using nothing more than a file manager would do.
But whatever the case, one should have backups of everything important anyway, so in a worst case scenario you could restore to an hour or two ago, or at least yesterday, and lose very little.
Honestly though, omitting the actual text, having one Scrivener file that leads to a bunch of other Scrivener files - an organizer basically - seems smart.
Some people use Scapple for that, too, if they are more visually inclined. But yes, I’m a fan of nesting egg organisation systems. ![]()
Overall it is going to have more to do with the raw text amount (not relative), for most people, which will impact full-project-text searching much sooner than other issues that may arise. The other most common factor most will encounter is backup slowdowns, where lots of research is involved. If the computer is being asked to copy and zip 4gb of data every time you close your project, it’s going to be slow to do so even on fast modern drives.
The number of items in the binder is an extremely small factor in the equation for most uses, crazy extremes that break GUIs in general aside.
Just for perspective, I have multiple projects with that many items in the binder or far more, but only very small fraction of the overall word count. They are lightning fast in all regards I can think of, on modern equipment (nothing crazy to be clear, just the cheapest 8GB Mac Mini you can buy, but recent hardware). The only project I ever had that felt slow had, you guessed it, millions of words.
And I would never have any documents with 300,000 words in them all by themselves. I would be surprised if any are over 10k. Many of these binder items are empty, existing only as outline entries for thoughts, todo lists and such. That is why counting just the number of items is going to be faulty, up to a point, because all you’re talking about then is how many lines are in an XML file as there aren’t even any physical files for them on the disk.
So search speed: the search engine is largely off the shelf components, although optimised fairly well in the grand scheme of things, it takes a fair amount of custom programming and optimisation to make 18 million character searching feel fast.[1]
This is an outlier example in that regard. I think most people will encounter backup speed issues first, as well as index rebuilding (which in some workflows can be a constant thing, like those that use mobile).
Where that breaks down is different on Mac and Windows, since again these are off the shelf search engines. The one we have available on Windows is not nearly as good as Apple’s, and will slow down much earlier (though still at a point well above the average book length). ↩︎
I think folks forget just how tiny text documents are relative to images (or any other media). Your novel might be 100Kb, and one image might be several hundred Kb. These are trivial things for a modern computer to process. My day job is coding. My projects have tens of thousands of lines of code, split across thousands of files. Search remains instant (modern MacBook with SDD, mind you). I’ve never had issues with novels (which are typically 120k, with hundreds of scenes, references etc etc)