I have used the File menu/Import/Import and Split function to bring in a manuscript from a text (.txt) file.
When performing a project search or referring to a search collection I’ve previously set up (always searching only the text and only within Included Documents), I am at times seeing the original .txt document that I imported listed in the found documents list of the collection?
The project is new, and started as a Novel Template. I selected Import and Split, pointed Scrivener to the source .txt file, and gave it the string of chars that were the chapter dividers. It imported correctly splitting the .txt file and making a new text document in the binder for each chapter.
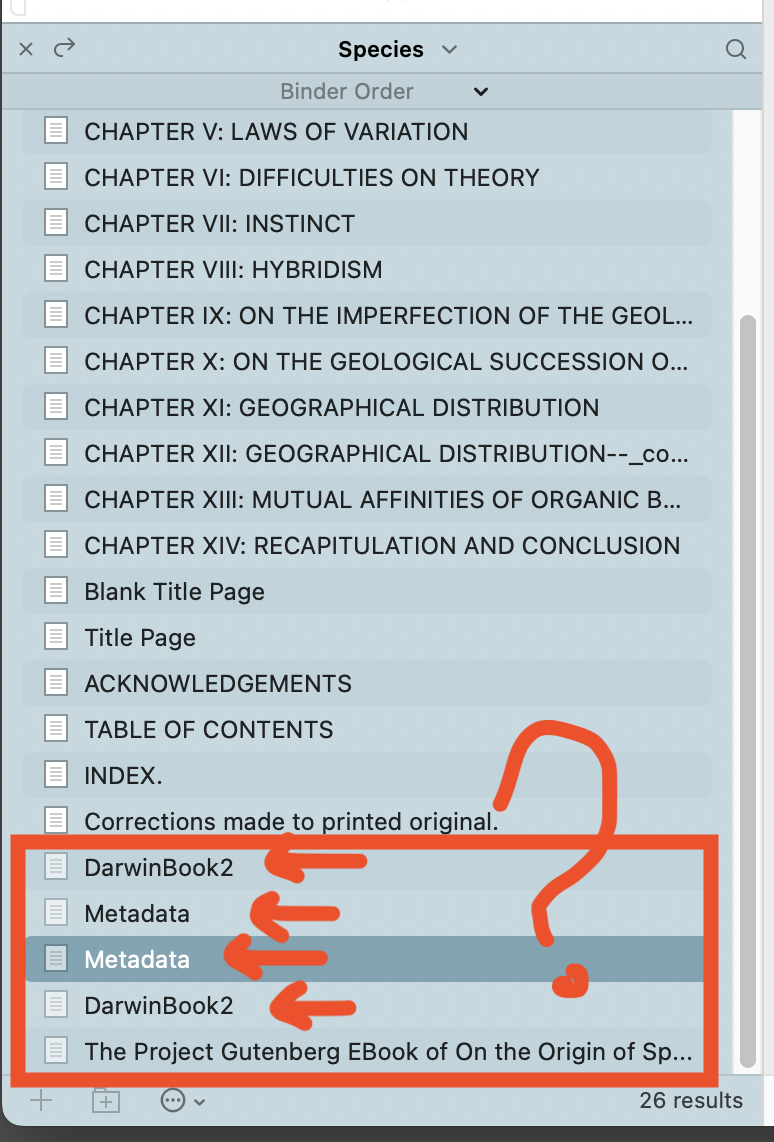
That original .txt file doesn’t exist in my binder (or at least it isn’t visible if it does), yet it is being referenced in a search collection???
PS I am using Scrivener 3.3.6 running on Sonoma 14.2.1 on a 2018, 15 inch Intel MacBook Pro with 16gb RAM.
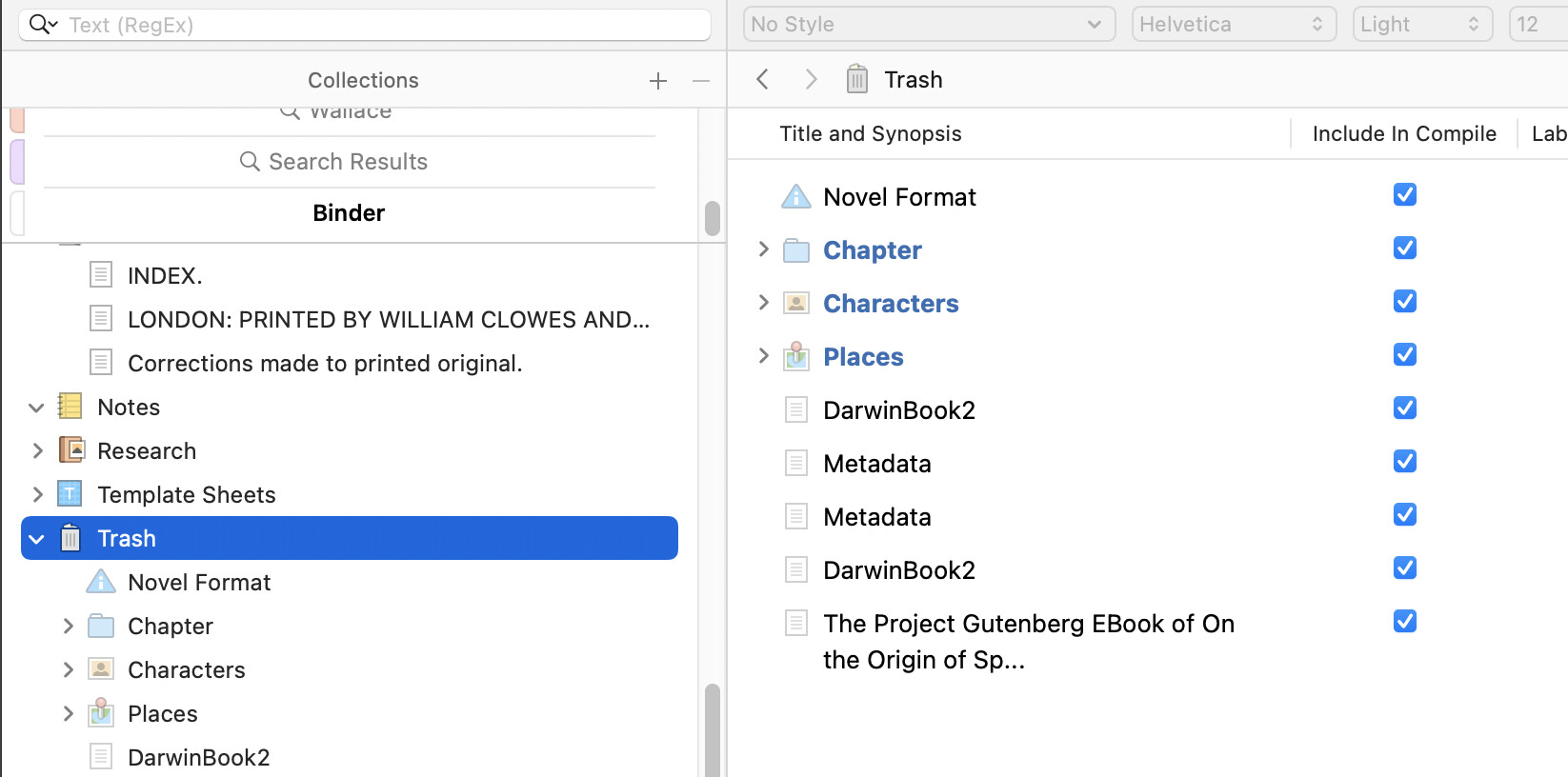
Just found the original text files in Scrivener’s Trash folder in the Binder. Then I switched to Outline view and added the “Include in Compile” column. Low and behold all of these trash items (that I never touched) are automatically marked as “Include In Compile”. So when Scrivener imports from an external file, it leaves the original file intact in the trash folder (and sets its "Include In Compile setting to true. Also, Scrivener does this each time you attempt an Import and Split of an external text file.
The .txt file cannot exist in the Binder, but at rtf version of it should, and the search should find it, unless you’ve placed it outside the Manuscript/Draft and you’re searching only inside it or vice versa.
None of that is true, so I would say there is some other cause. What happens when you import:
The original file is read from the disk and passed through a conversion library from its original text format into Scrivener’s internal file format. Which library is used depends on the file format. There is a Java-based converter for ODT, but if you don’t have Java installed it will fallback to the system converter. For DOCX it uses a bespoke converter. For and RTFD the system libraries are used, as well as plain-text formats.
This is then further processed using bespoke code to convert various features that might not be supported directly by the system (embedded images, styles, footnotes, etc.).
The important thing to be aware of is that prior to this conversion and the previous, is that there is no purpose at all for the resource to be stored in the binder. At step one it would be in a file format Scrivener doesn’t understand, so it would be a read-only Quick Look preview at best. Before step 2 it is the right format (RTF) but is missing crucial features that could cause data loss, so we wouldn’t ever put that into the binder either.
Now that the content is prepared the software integrates it with the data model in one of two ways:
For drag and drop or simple file imports: it is given a binder title based upon the file name, it acquires some basic default settings (such as “Include in Compile” being true).
For import and split: the prepared content is processed using the given criteria and the above process is used for each chunk that is recognised. This can involve building hierarchy when the split criteria and content causes such (like Heading 1 and Heading 2 styles building a nested tree). Items are named according to other rules that differ depending on the split type and settings; it’s probably not worth getting into that. In essence, for the purposes of step one, the import and split feature acts like you imported multiple files, at that point the import process is the same.
Internally this also involves creating .rtf files on the disk, saved into matching subfolders based on their data model and internal IDs.
The original content data is flushed from RAM, save for whatever is loaded into the editor. Again it has no useful purpose in the project and wouldn’t be placed anywhere.
So that is why you see everything included in compile, not because it is changing anything, but because that is the core default for all new items, whether they are imported or created within the software. It doesn’t matter where you create them, because this setting operates at a level beneath the Draft folder. You can drag things in and out of the draft without losing that setting, or even trash them, which is crucial because that setting is more important than where the item currently is. This is what allows people to swap books in and out of the Draft folder without losing their important inclusion settings. This is what allows people to compile material from outside of the Draft, which isn’t common, but can be achieved by compiling search results or collections.
Therefore the presence of these items in the Trash must be because they were trashed at some point. Perhaps it was long ago, it doesn’t really matter too much. You have, I think from other threads, figured out how to exclude trashed items from your search results, so that resolves the main confusion that started this thread. We do have that on by default, because a common desire for searching is to locate missing things, and accidentally trashed data is a not uncommon place for things to go missing.
I just wanted to point out that some other activity caused them to be in the Trash folder, so you don’t think you have to periodically clean them out when importing.
There are no automated processes in Scrivener that would trash items without you doing so yourself. That folder is 100% user controlled.
This is basic.
You had not looked for your ghost files beforehand. (Or not everywhere, the least.)
It is ok. We all make mistakes.
But I wanted to bring to your attention how that is in contradiction with the other threads where you rebuff people, saying you know how the software works. (I think it is obvious you still – like the rest of us – have a few things to learn.)
People here are only trying to help.
Worse case scenario – say the fix/answer/workaround doesn’t pop right away –, by narrowing down the possibilities. By investigating. (Often out of enthusiasm ; – as a general rule, it is a good idea to keep that in mind.) Investigation which in many cases also imply giving one the opportunity to clarify things (there is room for improvement regarding the way you formulate your bug reports and support queries too – my personal opinion), and therefor, by elimination, make one’s issue/case progress toward a resolve.
Else, what could I say ? With the right attitude, there is a lot to learn from other users, here on these forums.
. . . . . . . . . . . . . . . .
Issues aside, as for the matter of bugs we mortal users can only do two things :
1- Confirm / infirm them.
2- Help you with a workaround.
Fixing them would be in LL’s staff hands. None of us users can do anything about them.
If you don’t want interactions concerning bugs you might have found, report them using the direct channel.
. . . . . . .
[ This post was initially flagged as offensive by the community. I’ve now made it as polite as I could. ]