OK, I read the manual & referred to perldoc but I can’t seem to make a replacement with RegEx
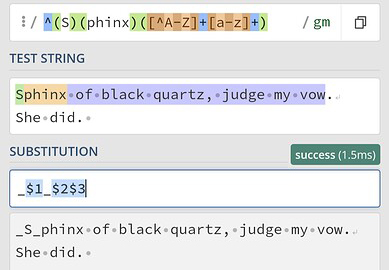
Given this text (MWE)
“Sphinx of black quartz, judge my vow.”
UPDATED to make the missing underscores appear
And the Find regex ([^A-z])S, what is the Replace regex to replace the S with “_S_”? (keeping the text in the first group and changing the text after)
i.e. “SPHINX” → “_S_PHINX”
I tried \g1 (per perldoc), $1 (per a Q &A) in the forum, and \1 (c.f. word) but none worked…
Now, the RegEx code in Scrivener’s Project Replace is a bit buggy, especially concerning replacements. So this may not work in Scrivener. Maybe Document Find and Replace RegEx gives better results?
P.S. I noticed I missed a “^” in the last group of the RegEx, but it doesn’t affect the result.
Many thanks, but as you feared this doesn’t work in practice… I tested a regex at that site before using it to completely mess up my MS (because it “worked” differently in Scrivener i.e., didn’t), so I’d prefer to know what works and what doesn’t in the target application
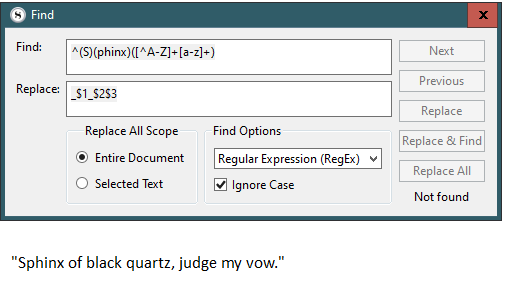
And if I use my own pattern, document containing (with quotes) “Sphinx of black quartz, judge my vow.”
Find: ([^A-z])(S)
Replace: $1_$2_
Result: "S_$2_phinx
i.e. 1st group replacement worked but not the second (should have been just the S)
I don’t use regexes very often because I’m not very good with them (often not knowing what the specific regex system is, doesn’t help, but in this case it’s clear). How can I tell whether I’m making a mistake or this is buggy? Should my version have worked?
PS For others…
The regex website I referred to is https://regex101.com/ and I think Scrv uses PCRE2… repeat, I think
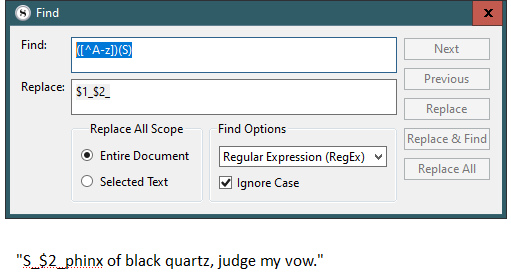
Thanks for the report, this is another variation on a bug in the replacement parsing. Standard $1 notation does work, but specific to the bug here, fails if such a marker is found at the beginning of the replacement string. Add a space in front of it, and you’ll find it works fine.
It’s been a bit of a pain, because evidently the Qt RegEx library was built without a single shred of code for replacement logic, just pattern matching, so they have been having to reinvent the wheel over here to get that working.
By the way, would either of the following patterns work for you? If so, they are also a workaround (without awkward two-step searches to first offset the $1 from the beginning of the string with junk characters and then later strip out the junk characters):
Find
\bS
Replace
_S_
The “\b” word-boundary code would do very similar to what you’re doing, but in a more robust manner (if that is indeed the intention), and since it’s a zero-width marker you aren’t having to capture the prefix.
Otherwise, I’d go with:
(?<![A-z])S
Same idea, dodge the need to capture the prefix condition by using a negative look-behind (and since the logic is negative, we don’t want to stipulate a negative set).
TL;DR I may return to regexes if and when the need is greater than at present… but thanks for the thoughtful contributions.
Alas I find myself in one of those, “Why do I bother?” states of mind, when the real replacement I was trying to do didn’t work (despite success on the test site) and the MWE I invented stumbles into another issue.
@AmberV, your suggestions are no doubt good, but to the extent they apply to an artificial example I don’t need them, and to the extent that their relevance to real applications is limited, they’re not worth losing further sleep over checking, refining etc. and I am not worthy of further detail because you lost me at “negative look-behind”
@AntoniDol all the same, can you share where the quote came from?
If you want to make use of Regex on Windows for individual documents in the binder, you may find it best to just use Sync with External Folder, and open the external sync files in a word processor/text editor that has a robust regex available to it.
If you export to plain text, you can even experiment with scripting the changes if you have such tools installed on your PC, redirecting the output to another file and using a diff tool to examine the changes.
Thanks, I wanted to use it on the whole project (e.g. global change from “a word…” to “a word …” (extra space before ellipsis), but after screwing that up, was testing regexes at document level only for safety.
A BAD THING happened to me when I used sync files… I have yet to get back on that horse
 thx!
thx!