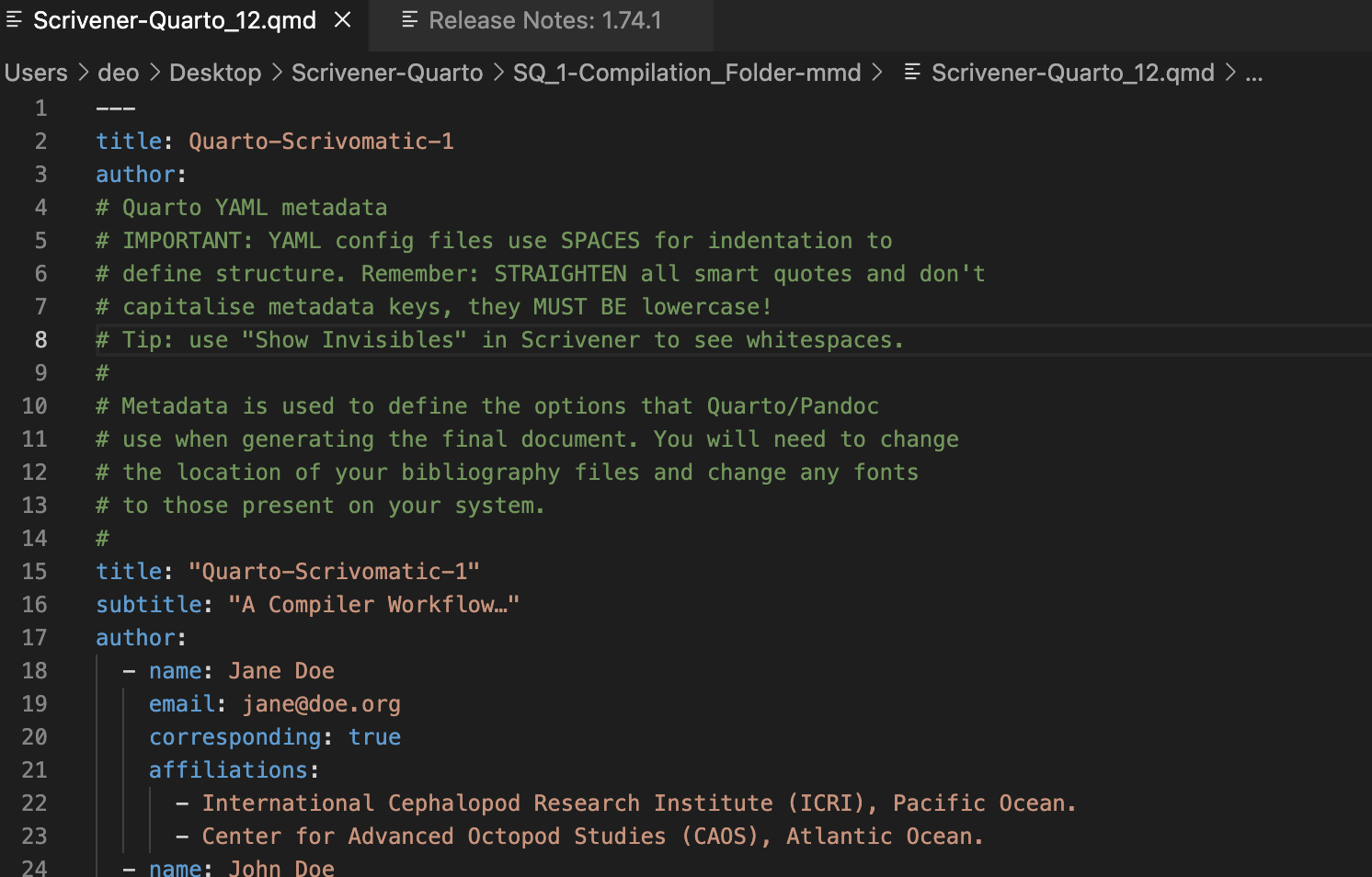
Oh, I guess what the compiler is complaining about is the title and author fields appear twice. I wonder what could cause that? Did I somehow accidentally alter the metadata section within Scrivener? A screenshot of the initial YAML section of the generated Quarto markdown file follows:
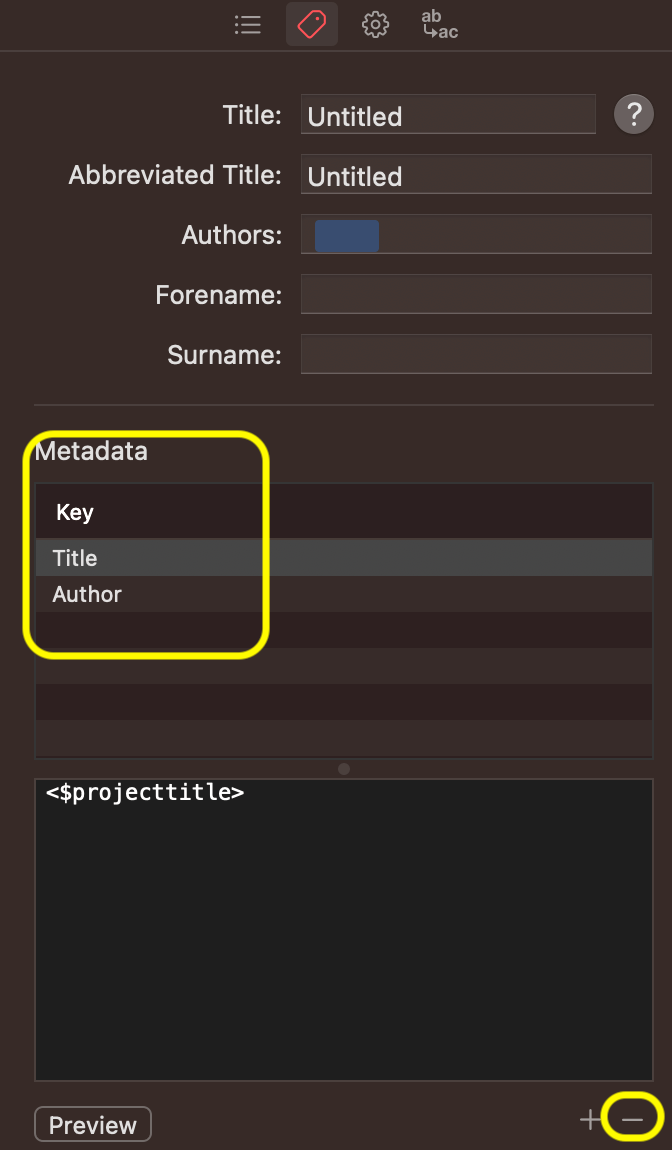
This is a known bug in Scrivener. I removed the Compiler general metadata in the template, but it comes back when you create a new project from the template. @AmberV has already flagged this so it will hopefully be fixed. In the meantime, just remove the compiler metadata:
1 Like
Removing the redundant metadata fixed the YAML error! Thank you @nontroppo.
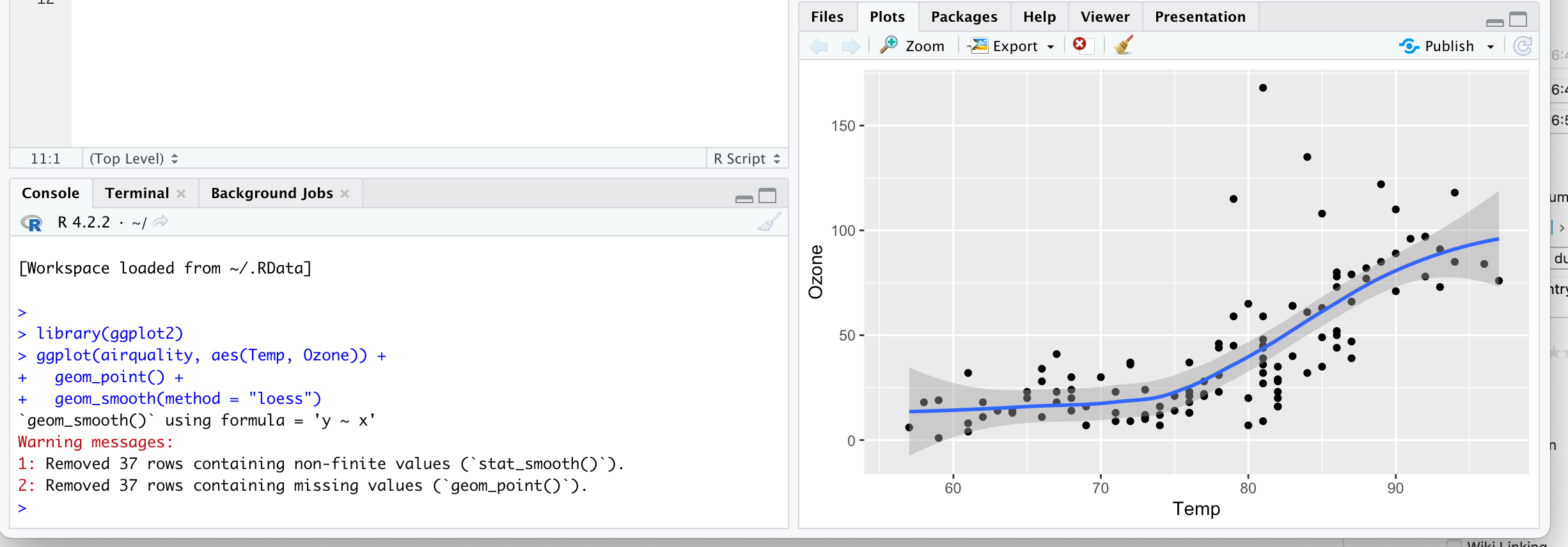
Now that the metadata redundancy is resolved, the next error I think is related to Quarto’s inability to locate the relevant R-code for the Fig. 3.3 of the sample document, the Ozone v. temperature plot with the loess fit. I am, however, able to generate the plot when I type the code into R-Studio on my M1 Macbook Air, as the figure shows. Any assistance you could give me would be greatly appreciated. The full log-file follows.
--> Input Filename: /Users/deo/Desktop/Scrivener-Quarto/SQ_1-Compilation_Folder-mmd/Scrivener-Quarto_1.md
--> Modified path: /usr/local/bin:/Library/TeX/texbin:/opt/homebrew/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/Applications/Scrivener.app/Contents/Resources/MultiMarkdown/bin
--> CrossRef figure details: Label={#fig-elephant .column-body} | We add the *cross-referencing label* to the **_start_** of the caption. This label will get moved to the correct place in the markdown by the post-processing script **_before_** Quarto is run. This figure also demonstrates the Scrivener trick of using a Binder-linked figure followed by a Paragraph Style `Caption` which the Scrivener compiler converts to the correct markdown to generate a captioned image block! | Elephant1
--> CrossRef figure details: Label={#fig-castle} | Elephant castle. | Elephant2
--> CrossRef figure details: Label={#fig-trunk} | Angry elephant with big trunk. | Elephant3
--> CrossRef figure details: Label={#fig-withattributes .myclass fig-align="right" width=3cm height=2cm} | This figure uses custom metadata values to identify the class, ID, width and height. The ««AB»» tag at the start of the caption is replaced with the correct Scrivener placeholders by the compiler; see global replacements for the details… | Elephant3-1
--> CrossRef figure details: Label={#fig-elespan} | This should span the whole page. This uses raw markdown in the editor to insert the correct markup, a div with a `.column-page` class, for Quarto's layout for extend-to-page-width. | Elephant1-1
--> CrossRef figure details: Label={#fig-elespan3 width= height=} | This should span the page to the right in HTML. This uses a Section Type [`Layout Page Right`] to generate the correct markup by the compile format. | Elephant1-2
--> CrossRef figure details: Label={#fig-castle2} | Elephant. | Elephant2-1
--> CrossRef figure details: Label={#fig-trunk2} | Angry elephant with big trunk. | Elephant3-2
--> CrossRef figure details: Label={#fig-alignright fig-align="right"} | This should be right-aligned if there is space… | Elephant3-3
--> Modified File with fixed cross-references: /Users/deo/Desktop/Scrivener-Quarto/SQ_1-Compilation_Folder-mmd/Scrivener-Quarto_12.qmd
--> Parsing took: 0.008014s
--> Running Command: quarto render /Users/deo/Desktop/Scrivener-Quarto/SQ_1-Compilation_Folder-mmd/Scrivener-Quarto_12.qmd --to html --log-level=INFO --verbose
e[31m
processing file: Scrivener-Quarto_12.qmd
e[39m
|
| | 0%
|
|...... | 9%
ordinary text without R code
|
|............. | 18%
label: fig-airquality (with options)
List of 4
$ fig.cap: chr "A plot generated at compile-time by R, using a Scrivener paragraph style [R Block] and using column-page layout"| __truncated__
$ column : chr "page"
$ warning: logi FALSE
$ message: logi FALSE
e[31mQuitting from lines 260-270 (Scrivener-Quarto_12.qmd)
Error in dev.control(displaylist = if (record) "enable" else "inhibit") :
dev.control() called without an open graphics device
Calls: .main ... call_block -> block_exec -> eng_r -> chunk_device -> dev.control
In addition: Warning messages:
1: In grSoftVersion() :e[39me[31m
unable to load shared object '/Library/Frameworks/R.framework/Resources/modules//R_X11.so':
dlopen(/Library/Frameworks/R.framework/Resources/modules//R_X11.so, 0x0006): Library not loaded: '/opt/X11/lib/libSM.6.dylib'
Referenced from: '/Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/modules/R_X11.so'
Reason: tried: '/opt/X11/lib/libSM.6.dylib' (no such file), '/Library/Frameworks/R.framework/Resources/lib/libSM.6.dylib' (no such file), '/Library/Java/JavaVirtualMachines/jdk-17.0.1+12/Contents/Home/lib/server/libSM.6.dylib' (no such file)
2: In cairoVersion() :
unable to load shared object '/Library/Frameworks/R.framework/Resources/library/grDevices/libs//cairo.so':
dlopen(/Library/Frameworks/R.framework/Resources/library/grDevices/libs//cairo.so, 0x0006): Library not loaded: '/opt/X11/lib/libXrender.1.dylib'
Referenced from: '/Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library/grDevices/libs/cairo.so'
Reason: tried: '/opt/X11/lib/libXrender.1.dylib' (no such file), '/Library/Frameworks/R.framework/Resources/lib/libXrender.1.dylib' (no such file), '/Library/Java/JavaVirtualMachines/jdk-17.0.1+12/Contents/Home/lib/server/libXrender.1.dylib' (no such file)
3: In (function (filename = if (onefile) "Rplots.svg" else "Rplot%03d.svg", :
failed to load cairo DLL
Execution halted
e[39m
There was some problem opening /Users/deo/Desktop/Scrivener-Quarto/SQ_1-Compilation_Folder-mmd/Scrivener-Quarto_12.html, check compiler log…
Did you install XQuartz, as this is a requirement for R, although I would have thought that would be required by RStudio as well (but maybe it bundles this for you?). RStudio is not needed by Quarto, as long as the R package is available and set up it should work. The error mentions X11 which is what xquartz provides…
brew install xquartz
brew install homebrew/cask/r # the cask alone works fine for quarto
You can always remove the documents from the compile that require R unless you are actually going to use it for your work, it is entirely optional for Quarto. The example I included requires at least the tidyverse packages https://www.tidyverse.org, and one table (Table 3.1) uses kableExtra, in R running in a terminal you need to install with (or install with RStudio):
install.packages("tidyverse")
install.packages("kableExtra")
This should then get the sample documents compiled…
2 Likes
Looks like we are getting very close, @nontroppo ! Thanks for sticking with me on this! Specifically, the figures are generated without error but at the end the compiler complains about the not finding a binary file:
pandoc: /Users/ian/.local/share/pandoc/csl/apa-ian.csl: openBinaryFile: does not exist (No such file or directory)
There was some problem opening /Users/deo/Desktop/Scrivener-Quarto/SQ_1-Compilation_Folder-mmd/Scrivener-Quarto_12.html, check compiler log…
I assume I need to download this .csl file and place it in my pandoc directory?
1 Like
Yes, you need to replace any linked files in the Scrivener Metadata document with your own files, for both the bibliography file and the CSL file.
If you want to try with my bibliography data (the JSON database and the CSL style file), I zipped it up here:
Biblio.zip (6.8 KB)
Note Quarto requires absolute paths so you need to change to your user name etc.
You may also need to change the fonts to those on your system, or install the ones my compile uses, Alegreya and Alegreya-Sans – fonts can be installed using homebrew: brew install font-alegreya font-alegreya-sans
2 Likes
You may also need to change the fonts to those on your system, or install the ones my compile uses, Alegreya and Alegreya-Sans – fonts can be installed using homebrew:
brew install font-alegreya font-alegreya-sans
I need to type brew tap homebrew/cask-fonts first, as suggested here? This must make the OS aware of the potentially downloadable and installable fonts? I am new to using homebrew.
install the ones my compile uses, Alegreya and Alegreya-Sans
Alegreya, used in your sample document, looks like a good choice to me.
1 Like
Yes, I forgot homebrew fonts are in the homebrew/cask-fonts tap, as you found it is easy to add. There are many great fonts and it is so easy to add/remove.
Alegreya is a great font indeed, though perhaps with too much personality for some! My only issue with it is it is missing a superscript - which causes problems for scientific notation in output formats that can’t do font substitution (like LaTeX)… Missing U+207B makes Alegreya hard to use for scientific writing · Issue #49 · huertatipografica/Alegreya · GitHub
1 Like
Thanks, Ian, for your continued help! I think your Scrivener + Quarto system is wonderful.
I guess this could be a separate topic, related to technical-writing style, but I sometimes think scientific notation might just as well be treated as inline mathematics. I guess it depends in part on your field, but if you have a physics orientation then it seems to me that the number will often be followed by some collection of units, and then it seems like too much to ask for any general font to handle, practically speaking. But perhaps I am not thinking about it right.

Now that the HTML version is compiling without errors, I have to say the result is quite impressive visually! I like it!

1 Like
Yes that is one workaround. At least for most biomedical science however using scientific notation for statistical p values is ubiquitous (p=1.4×10⁻⁹) and inline maths seems overkill for what is a very common requirement. I have another font I use personally (Dolly Pro from Underware), but if I was to use Alegreya i’d use fontforge to add the missing characters (editing fonts isn’t too difficult, I’ve done it many times for tweaking my work, but I am a typography geek)…
Yes, .bib works fine. I prefer JSON as it is much faster for Pandoc to use (my database has >9000 refs). My reference manager Bookends exports BibTeX so I use an automated script to convert my .bib to .json. This conversion is triggered using launchd whenever the .bib file changes, using Pandoc to convert using pandoc -f bibtex -t csljson input.bib > output.json
![]()
2 Likes
The ruby script at compile time could solve this by replacing ${USERDATA}/ with the appropriate Pandoc user data folder (or simply .local/share/pandoc) at compile time ![]()
Yes, good point. I added ${USERHOME} expansion. I don’t want to hardcode the Pandoc data folder itself as Quarto doesn’t require a Pandoc install and doesn’t use this folder itself… scrivomatic/quarto-run.rb at master · iandol/scrivomatic · GitHub
- New output format:
chunkedhtml. This creates a zip file containing multiple HTML files, one for each section, linked with “next,” “previous,” “up,” and “top” links. (If-ois used with an argument without an extension, it is treated as a directory and the zip file is automatically extracted there, unless it already exists.) The top page will contain a table of contents if--tocis used. Asitemap.jsonfile is also included. The option--split-leveldetermines the level at which sections are to be split. – Pandoc 3.0 Changelog
This might will, no doubt, make things a lot easier.
2 Likes
Indeed Pandoc 3.0 has a huge set of improvements including chunkedhtml output. Others include support for using ==marked text== to represent highlighted text, and native implementation of complex multi-part figures.
Integration of Pandoc V3.0 into Quarto is taking place here: GitHub - quarto-dev/quarto-cli at feature/pandoc-3 — they will need some time as the changes are significant…
1 Like
Not to mention native support for [[WikiLinks]], which is very convenient. Looking forward to seeing it integrated into Quarto.
1 Like
nontroppo, do you think it is safe to install it now, if it will have to be used with Scrivener? I’ve not even understood if upgrading would be transparent to the final user, or there are different workflows to learn.
Paolo
I would keep a copy of v2 around just in case I missed something, but nothing that I saw in the v3 change logs looks like it would break integration with Scrivener. We’ll have to switch to using --split-level instead of --epub-chapter-level for the ePub output, but for the time being the old argument is still recognised.
1 Like
As I use homebrew to install and there was some problems with some other tools in homebrew that use pandoc but were abandoned, I only just upgraded myself.
- Quarto bundle their own Pandoc, so that will probably stay at 2.x until they verify a safe upgrade. Installing V3.0 will not affect Quarto at all, so you can play with v3.0 and keep using Quarto.
- Direct from Scrivener, if you use Pandoc via MMD post-processing you should be fine, as you are responsible for all the command-line options. If you use a defaults file then you will need to tweak your files if you want to access to some of the new features.
- Direct from Scrivener + Scrivener’s compile settings: as @AmberV mentioned there shouldn’t be a breaking change, though as these formats are closed (in the sense we can’t see what the pandoc command is), there isn’t much we could do if there was, so if you are cautious stick to V2.x until someone else tries.
- Direct from Scrivener + Scrivomatic, as I use Pandocomatic then this update is being tracked here: Investigate what pandoc version 3.0 means for pandocomatic · Issue #109 · htdebeer/pandocomatic · GitHub — I still need to test so the best bet for scrivomatic users is stick to V2.x until I’ve tested.
Note: pandoc’s executable is a single file so it is easy to install several versions and use symlinks to call them. In general as all template and data files (i.e. the LaTeX template, docx reference etc.) are embedded in the executable, it is only your own user data files you need to worry about.
2 Likes