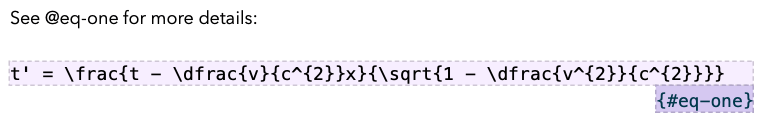As I previously demonstrated how to use Scrivener with pandoc, it was straightforward to add a new workflow for writing in Scrivener amd compiling using the new scientific and technical publishing system, Quarto. Quarto bundles Pandoc along with a set of extensions and templates to provide an all-in-one experience, including Tufte-like output, extensive cross-referencing, running code (R, Python, Julia, Dot, Mermaid etc.) to generate figures and complex layouts, generation of complete websites and more…
Because Scrivener supports Pandoc-flavoured markdown and automated post-processing, it already “supports” Quarto. However, for cross-referencing Quarto places labels at the end of the line, and this conflicts with Scrivener’s block style injection of markup. A small mod of a previous pandoc-crossref post-processing script solved this problem. This new script runs from the post-processing pane of the Scrivener compiler, and runs quarto automatically after tweaking the path and fixing the cross-references.
DOWNLOADS:
Scrivener + Quarto Project Template: save this file removing any .txt suffix if added by your browser; import the Scrivener + Quarto.scrivtemplate file using File → New Project… dialog, and then select the Non-Fiction → Scrivener + Quarto template to create your new project!
Alternative: project as a regular ZIP file.
Example PDF compiled directly from the above Scrivener project.
The bundled post-processing script can be checked here.
Quarto supports many journal templates and extensions which can be downloaded and installed. See this awesome list for a curated list.
Most Quarto features can be used via three routes, and the Scrivener + Quarto template demonstrates all three:
- Using Scrivener Styles — examples: Callouts, Live Code. The main caveat with Styles is Scrivener doesn’t allow paragraph [block] styles to be nested.
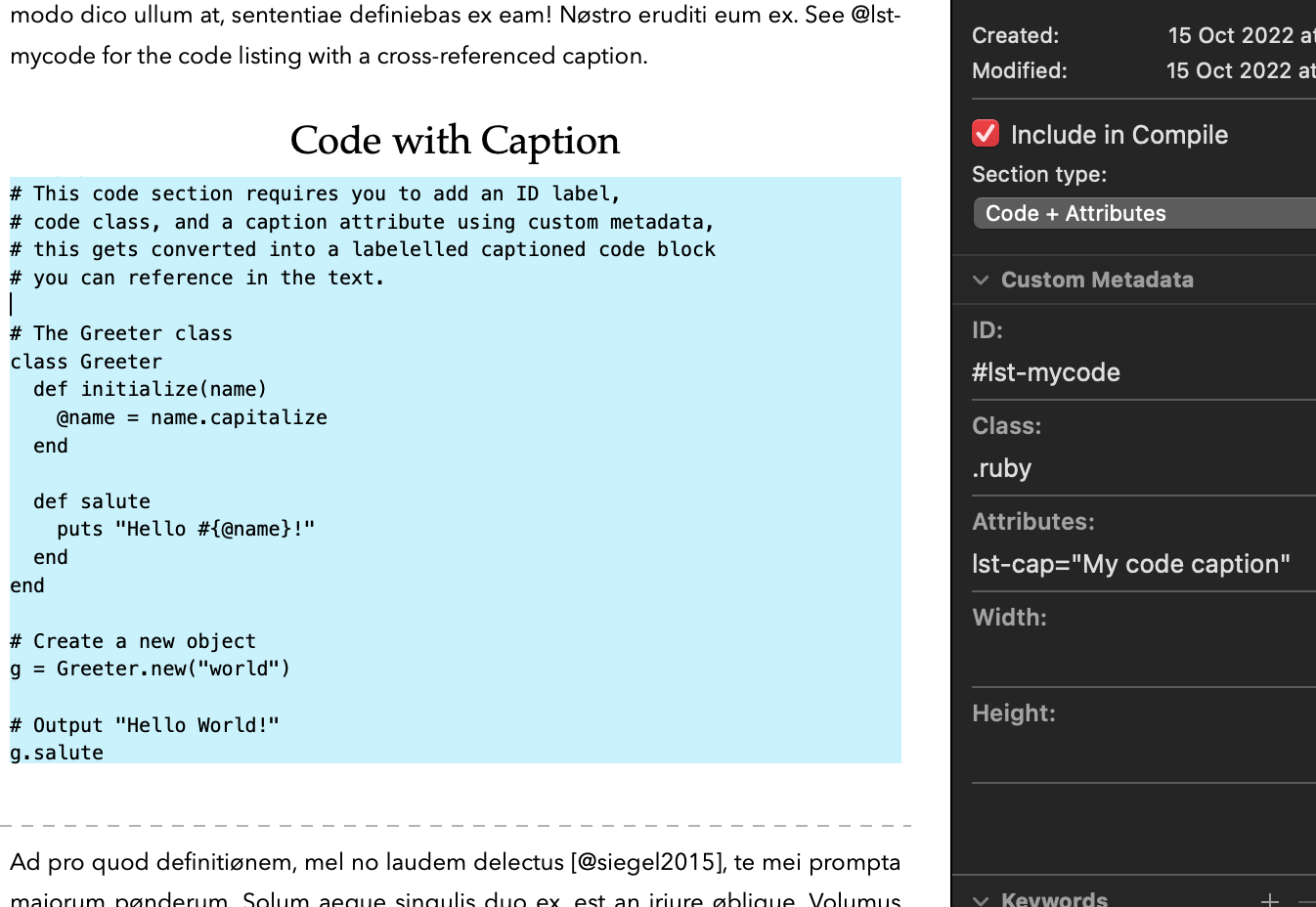
- Using Scrivener Section Layouts — example: multi-item images / tables using cross-referencing attributes. This method allows nested blocks. Scrivener document templates are provided.
- You can always write plain markdown in the editor if you prefer…
Quarto’s documentation is excellent. Some of the cool features that Quarto includes and work well with Scrivener:
- Panels with sub-figures and sub-tables.
- Based on Tufte, you can use margins for notes, figures, equations etc. Layout can be modified to span the page in many ways. You can rewrite layouts using Pandoc’s templating language.
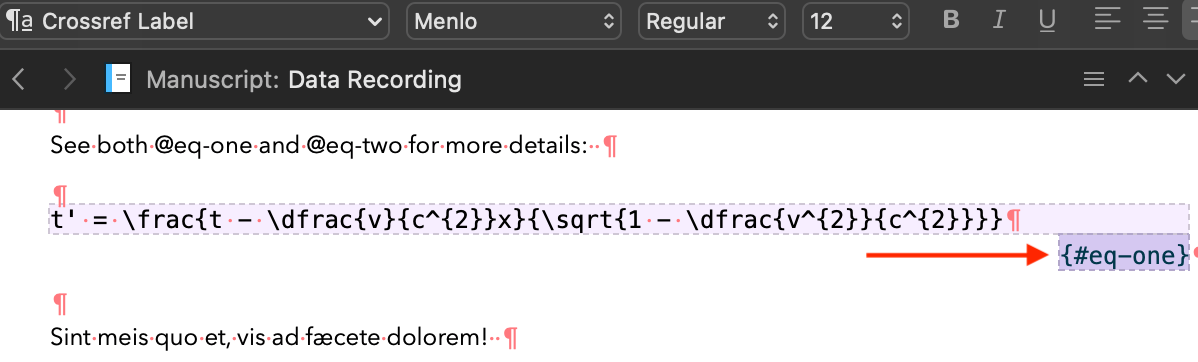
- Comprehensive cross-referencing, using Pandoc’s @citation markup (based on pandoc-crossref). For sub-figures / tables, you can add labels, like Figure 3(c) and these can be customised.
- Academic author + affiliation metadata «similar to scrivomatic and pandoc scholar».
- Run Python, R, Julia code “live” to plot figures on each compile.
- Use graphing engines like Mermaid and Graphviz.
- HTML output has lots of cool tweaks, see https://quarto-dev.github.io/quarto-gallery/page-layout/tufte.html for example.
- Quarto allows installable extensions, so you can plug in new layout templates and code to extend its powers!
- As it is Pandoc-based, there are many formats supported and Pandoc’s custom filters customise many aspects of the final document.
Quarto installs [almost] everything required (you can use it to manage Pandoc, LaTeX, Graphviz, Mermaid and other tools all-in-one). For LaTeX it can install and update TinyTeX, which enables a small install footprint and automated addition of packages from CTAN as required (no fussing with tlmgr)…
Here are some screenshot of the HTML/PDF output from Scrivener, showing a few of the nice features:
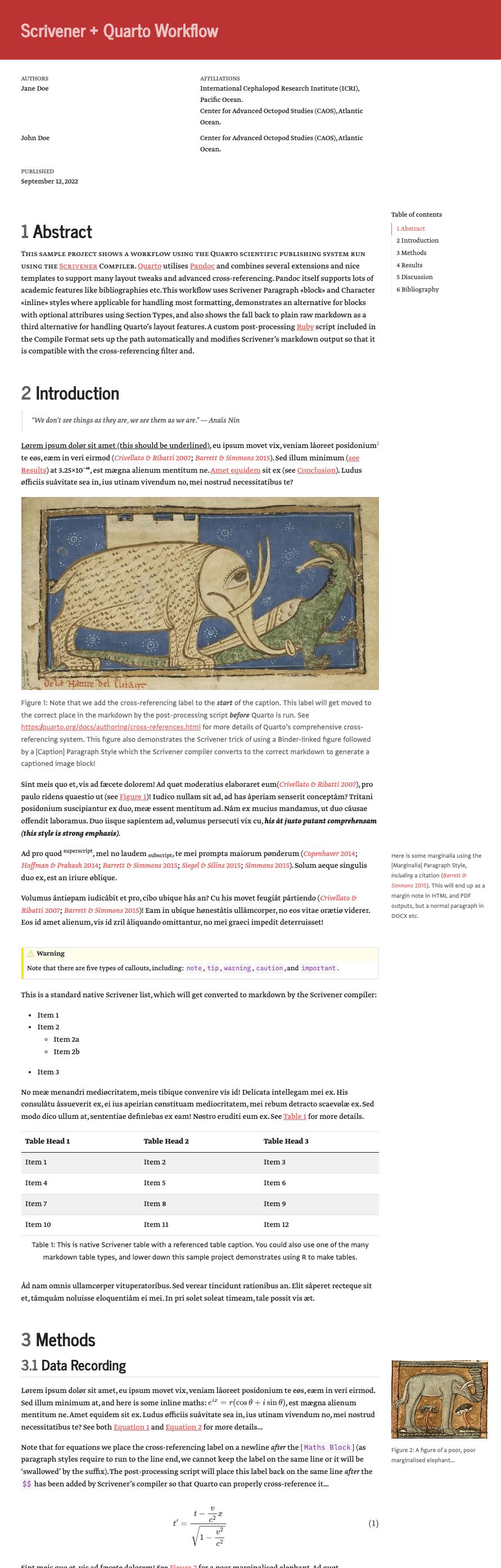
Showing margin notes, cross-referencing of figure blocks, academic metadata, equations, citations etc. «HTLML example»
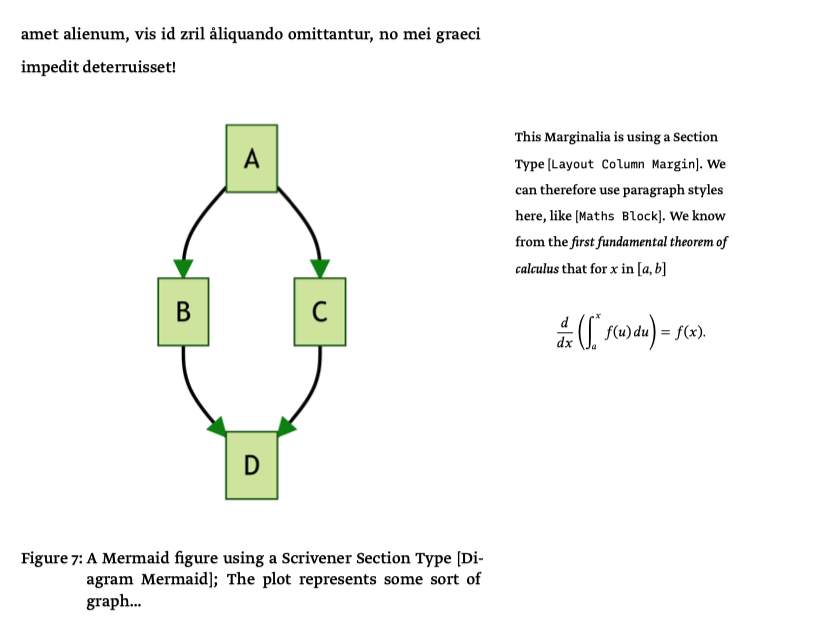
A margin note ala Tufte; these can include figures, equations etc. The figure also demonstrates the use of an auto-generated Mermaid graph made from editor text at compile time. «PDF example»
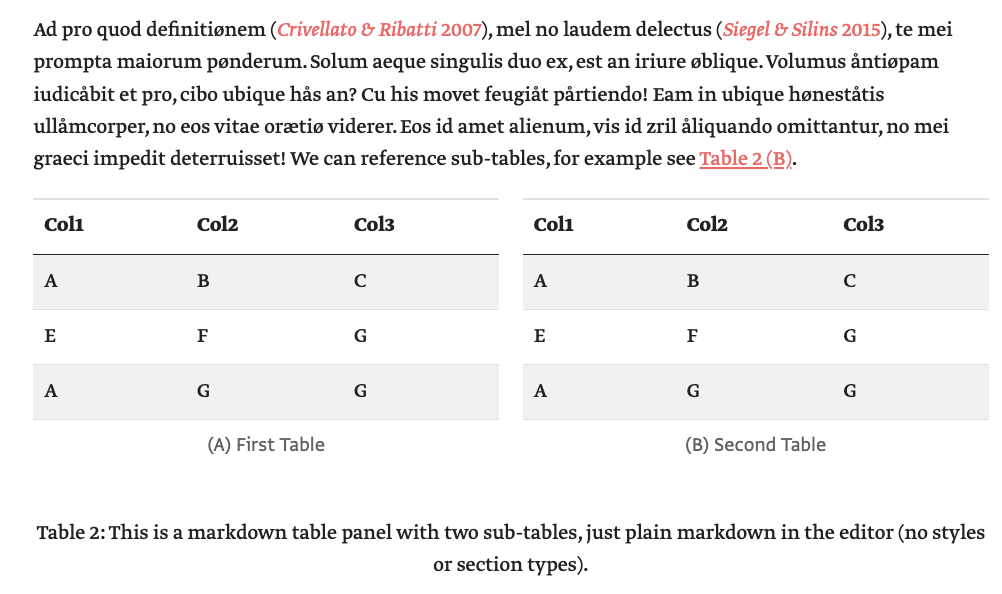
Multi-part tables; note the cross-referencing includes the sub-table labels, e.g. Table 2(B), and the custom styling of table rows. «HTML example»

Academic in-text citations can include hovered boxes containing the final bibliographic information. «HTML example»
Requirements
- Install Quarto (quarto bundles
pandocfor you). Bothbrew«macOS/Linux» andscoop«Windows» can install quarto for you. - You can then use Quarto to install LaTeX:
quarto tools install tinytex— TinyTeX is small yet can auto-install required packages if they are missing as needed; OR you can use an existing TeX Live installation (I use BasicTeX on macOS). - For Mermaid & Graphviz, Quarto can install a Chromium runtime if you don’t have Chrome installed:
quarto tools install chromium. - The script requires Ruby, which is already installed on macOS. You can use
breworscoopto install/update it otherwise.