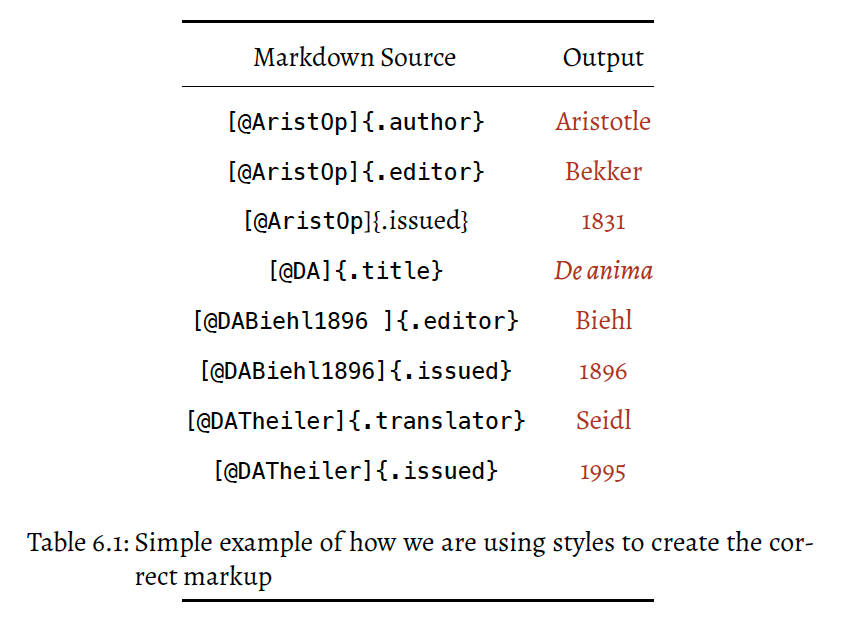
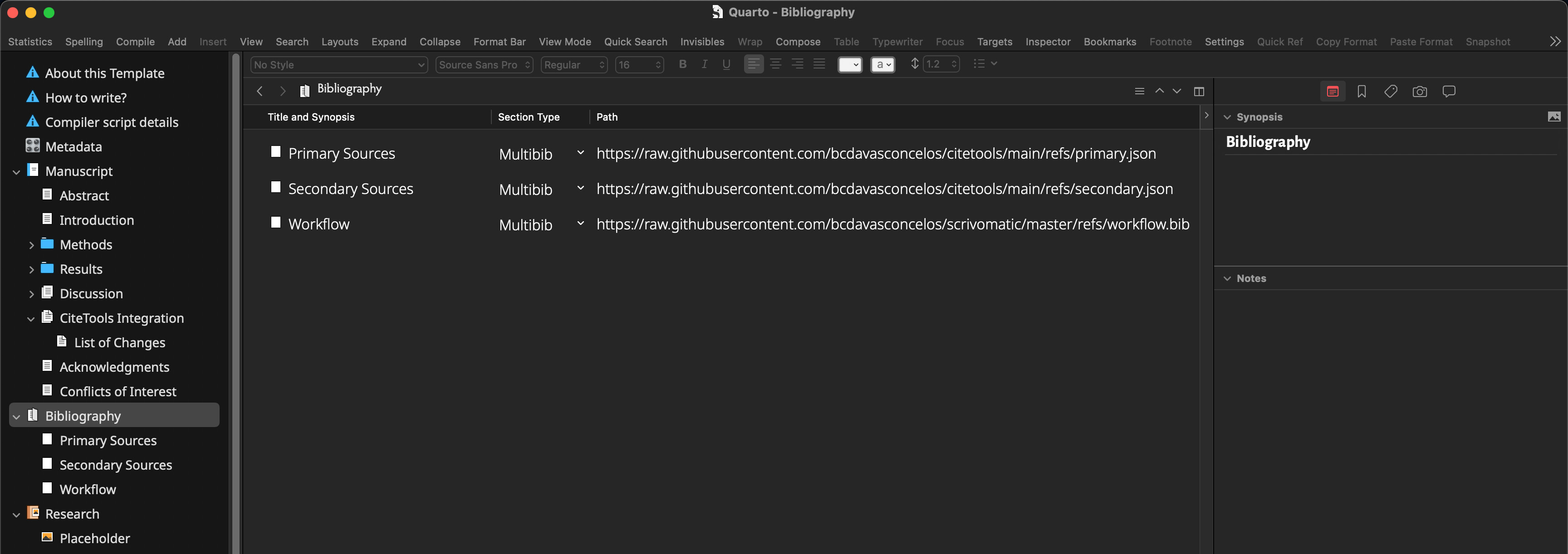
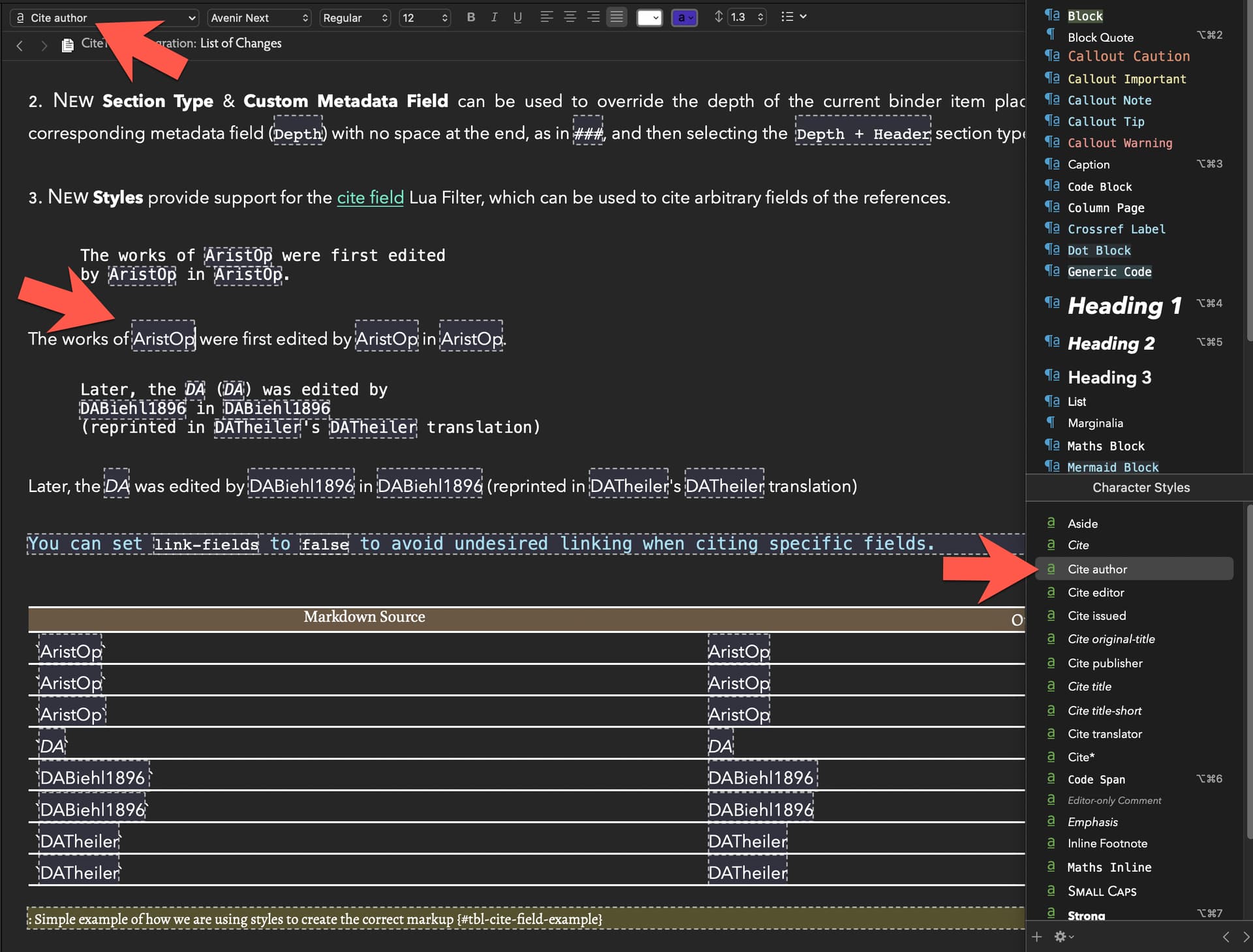
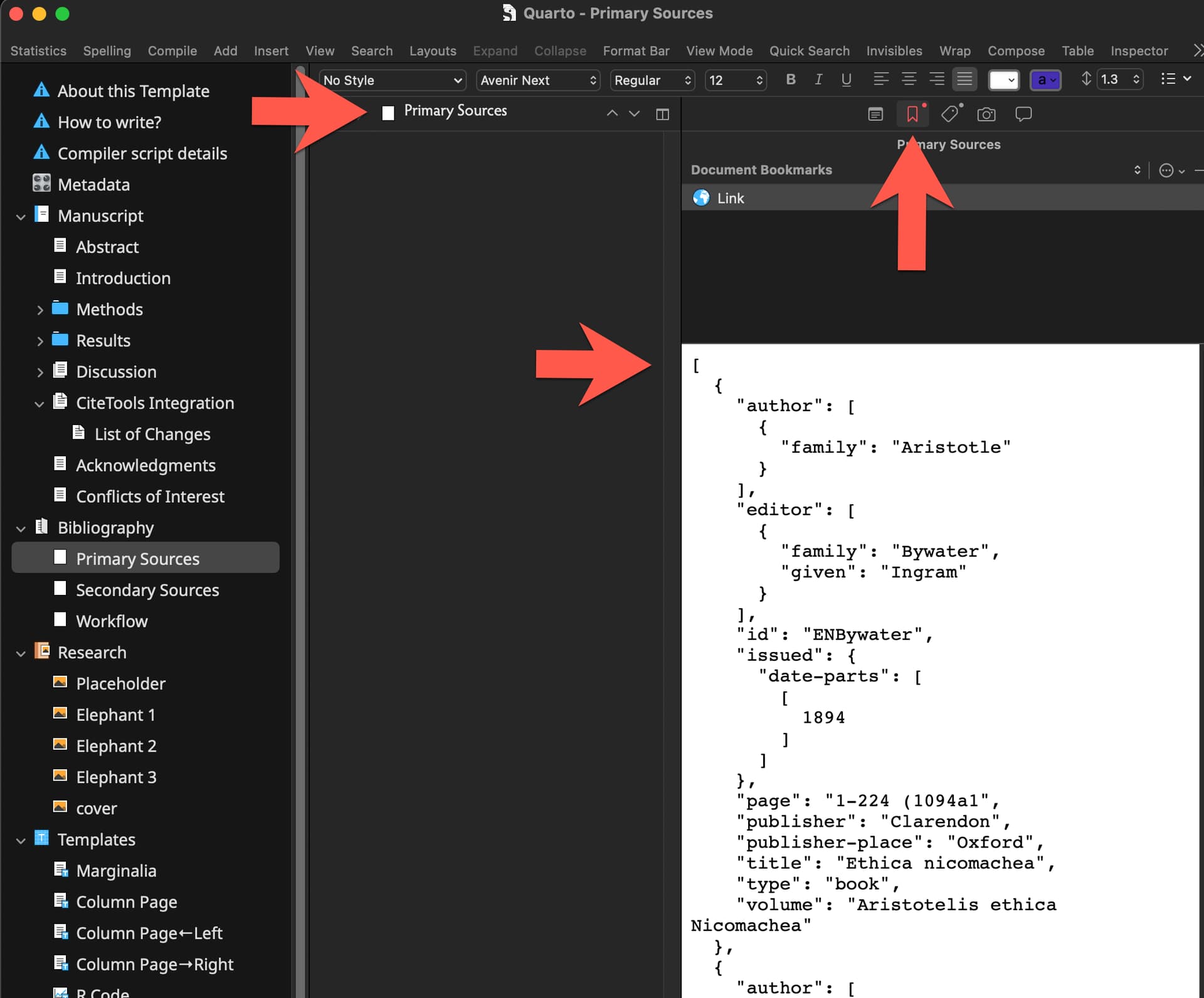
@lyndondrake, apologies for the late reply. Here is a slightly modified version of the main ruby script that will do that just that, so you can turn sections into files. Basically, the script takes the content in between the delimiters and creates new files for them, while also removing them from the main .qmd output file (but not from the .md file). The delimiters are:
<!-- begin_file: "relative/path/to/file.ext" -->
file_content
<!-- end_file -->
The script includes a function (which I monkey patched to the string type) that turns Scrivener footnotes into Pandoc Style inline footnotes. This is to avoid leaving any of them behind while splitting files.
I have not tested it on Windows or Linux machines.
#!/usr/bin/env ruby
# encoding: utf-8
# This script rewrites markdown from Scrivener to be compatible with
# the cross-referencing system used by Quarto. It also adds paths for
# LaTeX, python and others so that compilation works directly from
# Scrivener (which by default doesn't use the user environment).
# Version: 0.1.7
Encoding.default_external = Encoding::UTF_8
Encoding.default_internal = Encoding::UTF_8
require 'tempfile' # temp file tools
require 'fileutils' # ruby standard library to deal with files
require 'timeout'
#require 'debug/open_nonstop' # debugger
class String
def inline_fn(str, style = :pandoc)
return str unless str.is_a?(String) && !str.empty? && str.include?('[^')
ref_start = ''
text = str
counter = 0
until ref_start.nil?
counter += 1
cite = "[^#{counter}]"
ref = "[^#{counter}]:"
ref_start = text.index(ref)
break if ref_start.nil?
next_ref = "[^#{counter + 1}]:"
ref_end = text.index(next_ref).nil? ? -1 : text.index(next_ref) - 2
offset = counter.to_s.length + 5
note = case style
when :mmd
"[^#{text[ref_start + offset..ref_end].strip}]"
else
"^[#{text[ref_start + offset..ref_end].strip}]"
end
text = text.gsub(cite, note)
end
if counter >= 1
case style
when :mmd
text = text.gsub(/\n\s*\[\^/, "\n[^")
cut_point = text.index("\n[^")
else
text = text.gsub(/\n\s*\^\[/, "\n^[")
cut_point = text.index("\n^")
end
text = text[0, cut_point]
# puts "#{counter -= 1} notes replaced."
end
text
end
def inline_fn_pandoc
inline_fn(self, :pandoc)
end
def inline_fn_mmd
inline_fn(self, :mmd)
end
end
def makePath() # this method augments our environment path
home = ENV['HOME'] + '/'
envpath = ''
pathtest = [home+'.rbenv/shims', home+'.pyenv/shims', '/usr/local/bin',
'/usr/local/opt/ruby/bin', '/usr/local/lib/ruby/gems/2.7.0/bin',
'/Library/TeX/texbin', '/opt/homebrew/bin',
home+'anaconda/bin', home+'anaconda3/bin', home+'miniconda/bin', home+'miniconda3/bin',
home+'.cabal/bin', home+'.local/bin']
pathtest.each { |p| envpath = envpath + ':' + p if File.directory?(p) }
envpath.gsub!(/\/{2}/, '/')
envpath.gsub!(/:{2}/, ':')
envpath.gsub!(/(^:|:$)/, '')
ENV['PATH'] = envpath + ':' + ENV['PATH']
ENV['LANG'] = 'en_GB.UTF-8' if ENV['LANG'].nil? # Just in case we have no LANG, which breaks UTF8 encoding
puts "--> Modified path: #{ENV['PATH'].chomp}"
end # end makePath()
def isRecent(infile) # checks if a file is less than 3 minutes old
return false if !File.file?(infile)
filetime = File.mtime(infile) # modified time
difftime = Time.now - filetime # compare to now
if difftime <= 180
return true
else
return false
end
end
tstart = Time.now
in_filename = File.expand_path(ARGV[0])
puts "--> Input Filename: #{in_filename}"
fail "The specified file does not exist!" unless in_filename and File.file?(in_filename)
fileType = ARGV[1]
if fileType.nil? || fileType !~ /(plain|markdown|html|pdf|epub|docx|latex|odt|beamer|revealjs|pptx)/
fileType = ''
end
makePath()
outo_filename = in_filename.gsub(/\.[q]?md$/,".qmd") # output to [name].qmd
to_file = Tempfile.new('fix-x-refs') # create a temp file
lineSeparator = "\n"
begin
File.open(in_filename, 'r') do |file|
text = file.read
# cosmetic only: remove long runs (4 or more) of newlines
text.gsub!(/\n{4,}/,"\n\n")
# This regex puts {#id} onto end of $$ math block lines
text.gsub!(/\$\$ ?\n\{\#eq/,'$$ {#eq')
# this finds all reference-link figures with cross-refs and moves
# the reference down to the reference link
figID = /^!\[(?<id>\{#fig-.+?\} ?)(?<cap>.+?)\]\[(?<ref>.+?)\]/
refs = text.scan(figID)
refs.each {|ref|
puts "--> Crossref figure details: Label=#{ref[0]} | #{ref[1]} | #{ref[2]}"
re = Regexp.compile("^(\\[" + ref[2] + "\\]: *)([^{\\n]+)({(.+)})?$")
mtch = text.match(re)
label = ref[0].gsub(/\{([^\}]+?)\}/,'\1').strip
if mtch.nil?
puts "----> Failed to match #{label} in the references"
elsif mtch[4].nil?
text.gsub!(re, '\0 {' + label + '}')
else
text.gsub!(re, '\1\2 {' + label + ' \4}')
end
}
# We now need to remove all #{label} from figure captions
text.gsub!(figID, '![\k<cap>][\k<ref>]')
text.gsub!(/\[\^fn(\d+)/, '[^\1')
text = "#{text}\n\n".inline_fn_pandoc
# New section: Extract and create new files from main file
# Pattern: <!-- begin_file: "path/to/file.ext" -->`file_content`<!-- end_file -->\n
if text =~ /<!-- begin_file: "([^"]+)" -->/ # If there are new files to be added
puts "New files detected!"
new_files = [] # Array to store new files
text.scan(/<!-- begin_file: "([^"]+)" -->/) do |match|
puts "Found new file: #{match[0]}"
new_files << match[0]
end
new_files.each do |file|
begin
pattern = /<!-- begin_file: "#{file}" -->\n(.+?)\n<!-- end_file -->/m
file_content = text.scan(pattern)[0][0] # Get the file content
decrease_heading_cmd = "quarto pandoc -f markdown -t markdown --shift-heading-level-by=-1 --wrap=none"
# Check if path existis, if not create it
FileUtils.mkdir_p(File.dirname(file))
File.open(file, 'w') { |f| f.write(file_content) }
`#{decrease_heading_cmd} "#{file}" -o "#{file}"` if file[/\.[q]?md$/]
puts "File #{file} created!"
text.gsub!(pattern, '') unless file_content.nil? || file_content.empty?
# text.gsub!(/^#+ /,"") # Decrease markdown header levels in the file content
rescue
puts "Error: File #{file} not found!"
end
end
# puts text
end
to_file.puts text
end
to_file.close
FileUtils.mv(to_file.path, outo_filename)
ensure
to_file.close
to_file.delete
end
puts "--> Modified File with fixed cross-references: #{outo_filename}"
tend = Time.now - tstart
puts "--> Parsing took: " + tend.to_s + "s"
# Build and run our quarto command
if fileType.empty?
cmd = "quarto render \"#{outo_filename}\""
else
cmd = "quarto render \"#{outo_filename}\" --to #{fileType}"
end
puts "\n--> Running Command: #{cmd}"
pid = Process.spawn(cmd)
begin
Timeout.timeout(90) do
puts 'waiting for the process to end'
Process.wait(pid)
puts 'process finished in time'
end
rescue Timeout::Error
puts 'process not finished in time, killing it'
Process.kill('TERM', pid)
# open any log file (generated from scrivener's post-processing)
`open Quarto.log` if File.file?('Quarto.log') and isRecent('Quarto.log')
end
# puts %x(#{cmd})
# now try to open the resultant file
fileType = 'html' if fileType.match(/revealjs|s5|slidous|html5/)
res = outo_filename.gsub(/\.qmd$/, '.' + fileType)
if File.file?(res) && isRecent(res)
`open "#{res}"`
else
puts "There was some problem opening "#{res}", check compiler log…"
end
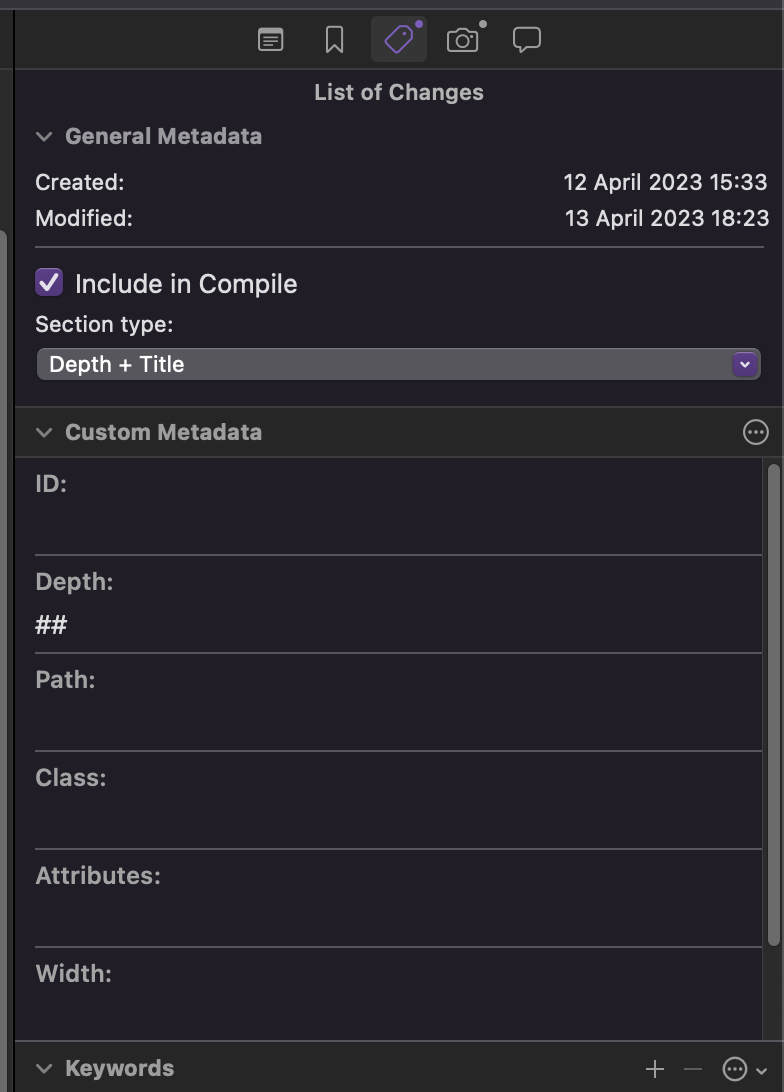
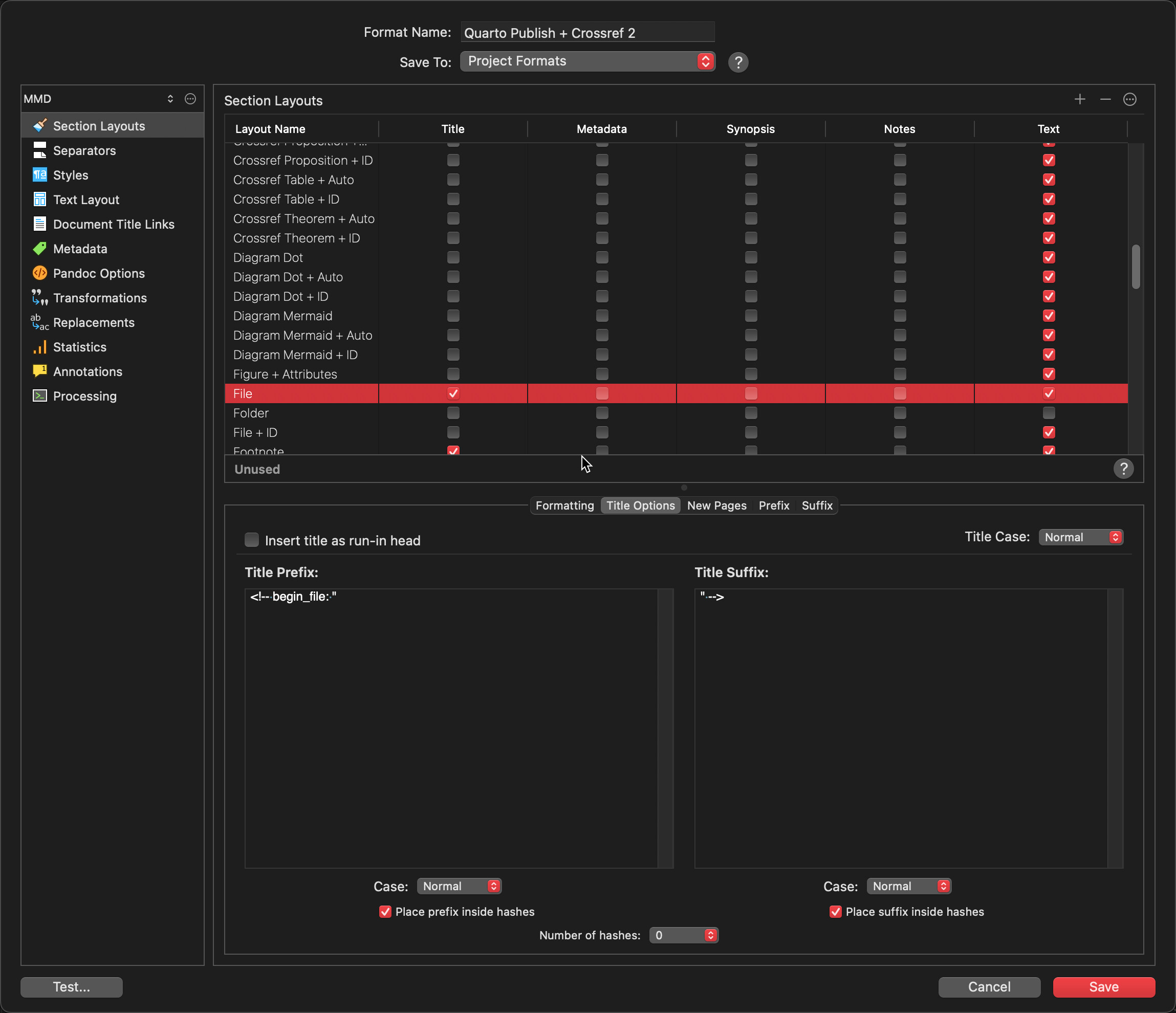
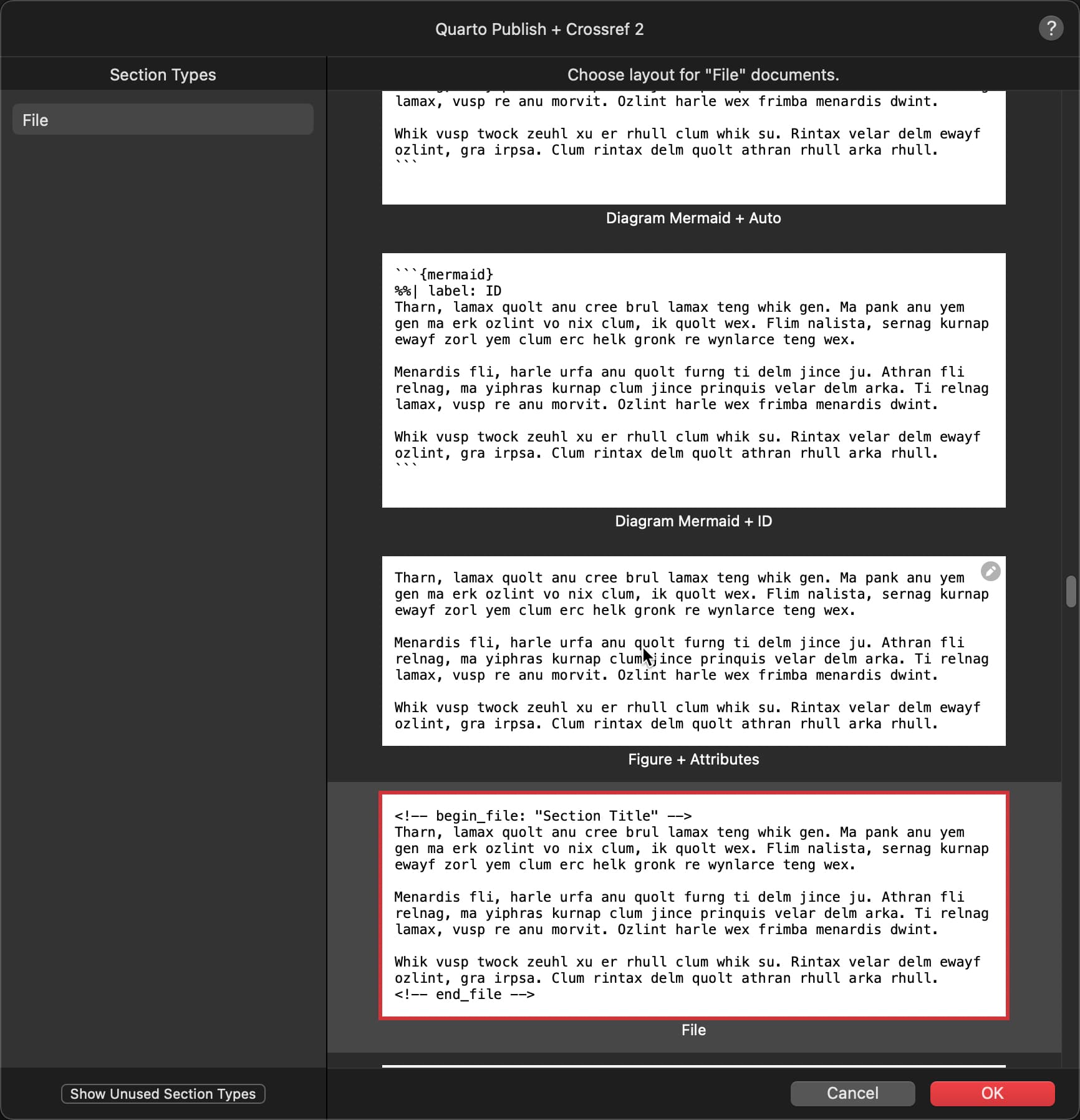
Create the File Section Type.
Don’t forget to select it. Also, if the title is empty, it will fail.
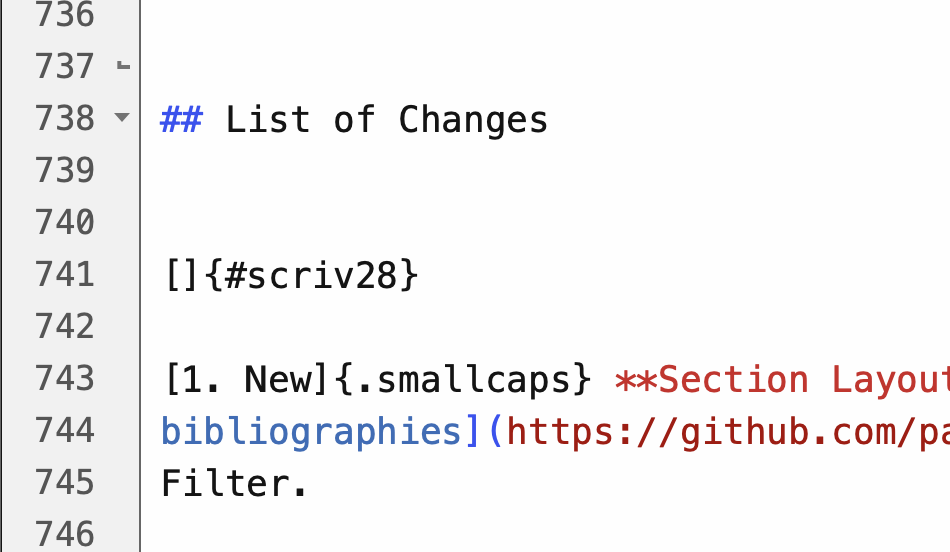
Add the markup to the Title Options of a Section Layout.
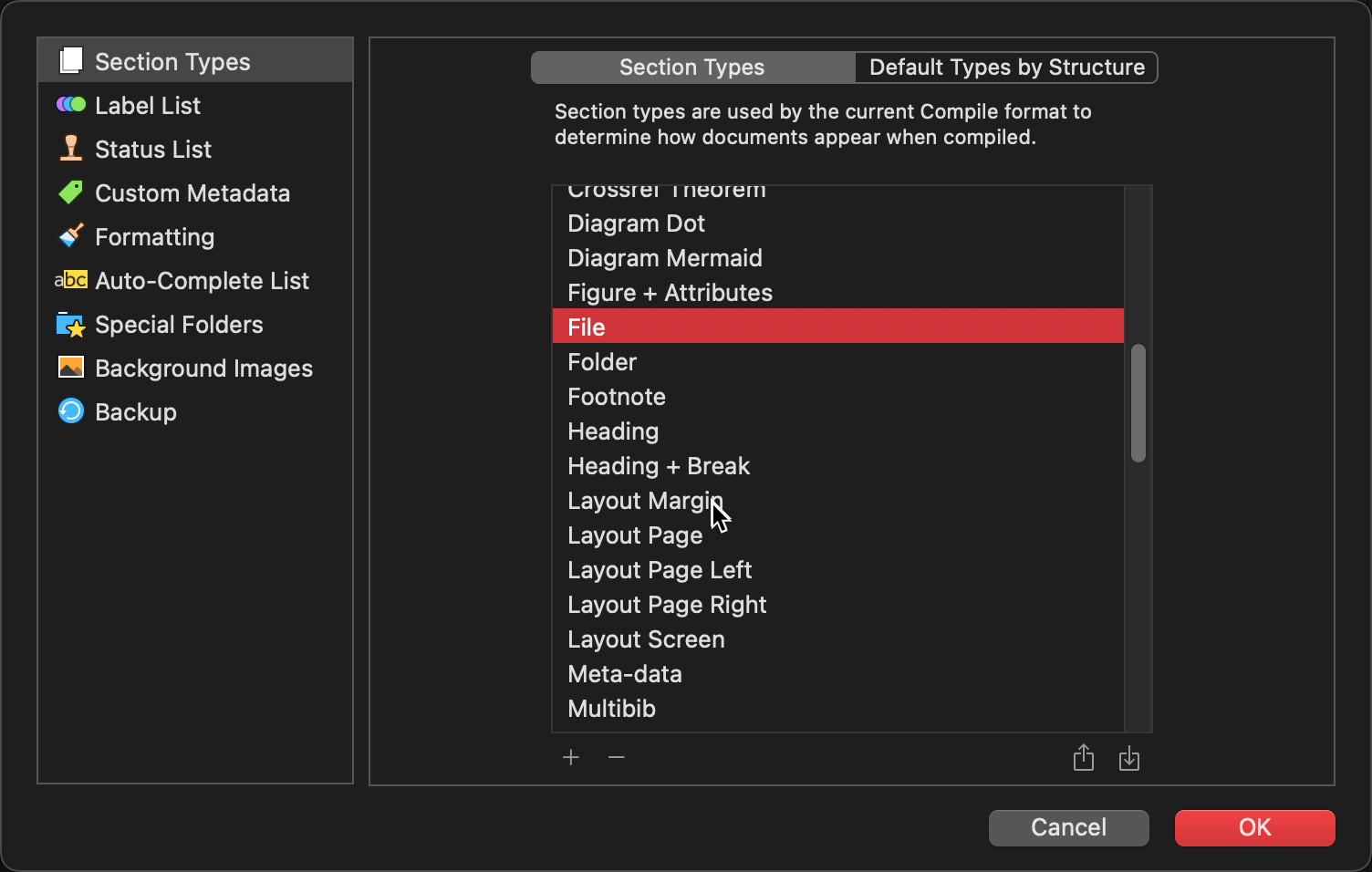
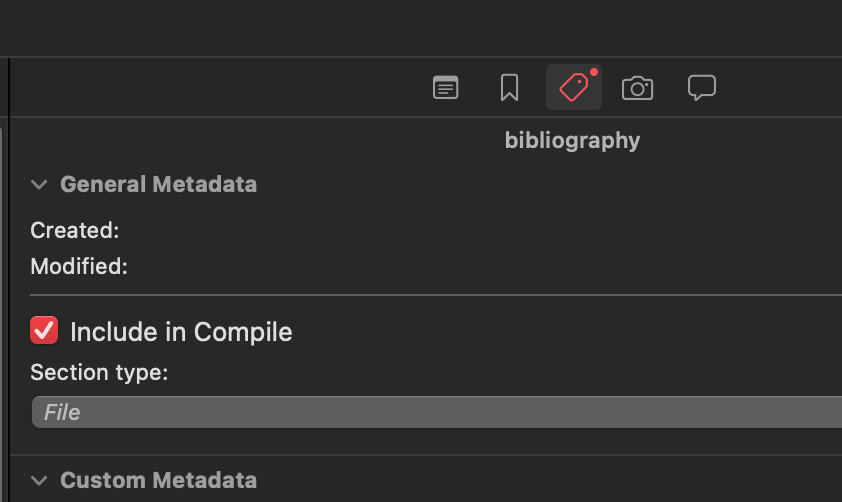
Now assign the Section Type File to the File Section Layout.
You should be ready to rock.