This template tries to integrate Quarto into the Scrivener writing environment. It includes new Section Types , Paragraph Styles , Character Styles , Custom Meta Fields , YAML Parameters for Quarto, new icons, and more. If you already have Quarto and R, it introduces zero new dependencies and you should be able to compile it immediately. All the auxiliary files – bibliographies, lua filters, project metadata – will automatically be created in the export folder each time it compiles (if already present, they will be overwritten).
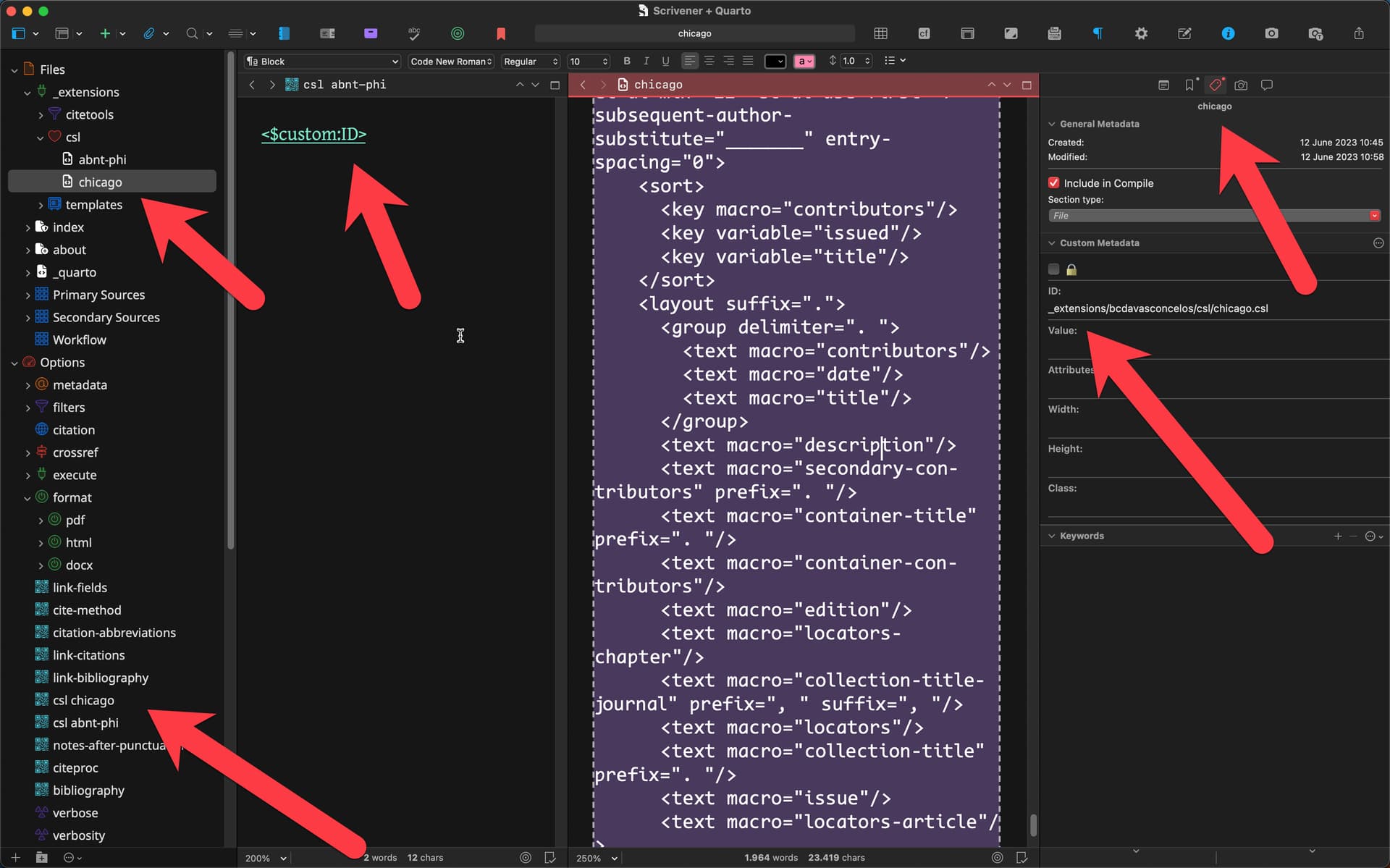
The template’s first notable difference is the way the YAML Front matter is written and the size it is. Instead of using a single binder text item for all the options, as is common practice, we are using one binder item for each YAML parameter with the idea of having all the options properly set up and available to be included or excluded from compiling by simply ticking a box. The YAML structure is automatically (WIP) formed by using the correct Section Type from whence the sub-items will inherit their own type (there is a digit between parenthesis next to the Section Type name indicating the number of empty spaces used as a prefix). This strategy can be used to control a high number of variables, as we are doing here, and to control the behavior of Quarto websites.
Quarto Options
Apart from being able to export the content of the project into multiple files, it already features nearly every parameter there is for Quarto Books (PDF, DOCX, HTML) and Websites (HTML), which amounts to some 600 options. (Yes, it was an insane amount of work). Each parameter contains the description offered at the Quarto website with further links under Document Links.
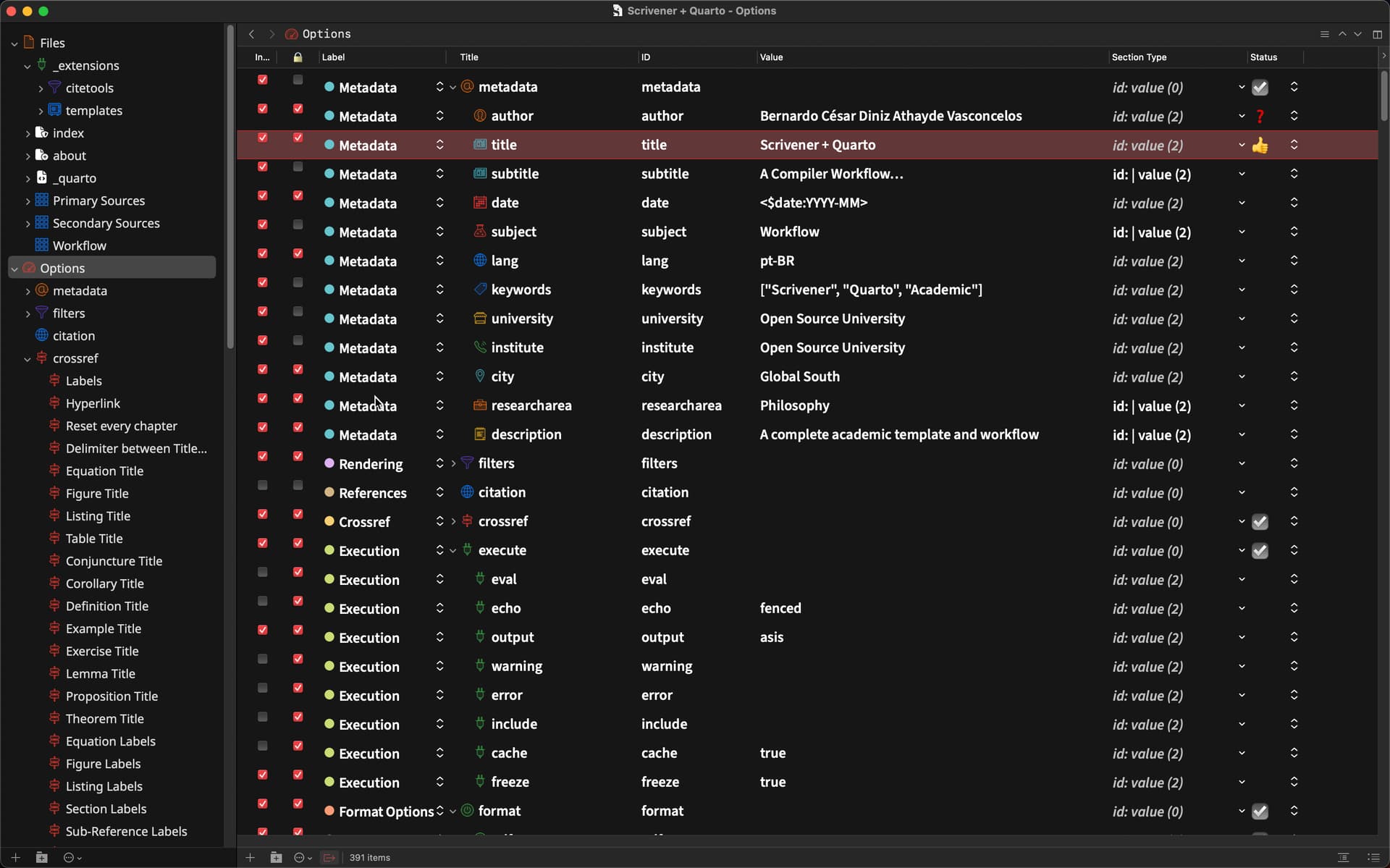
Bibliography
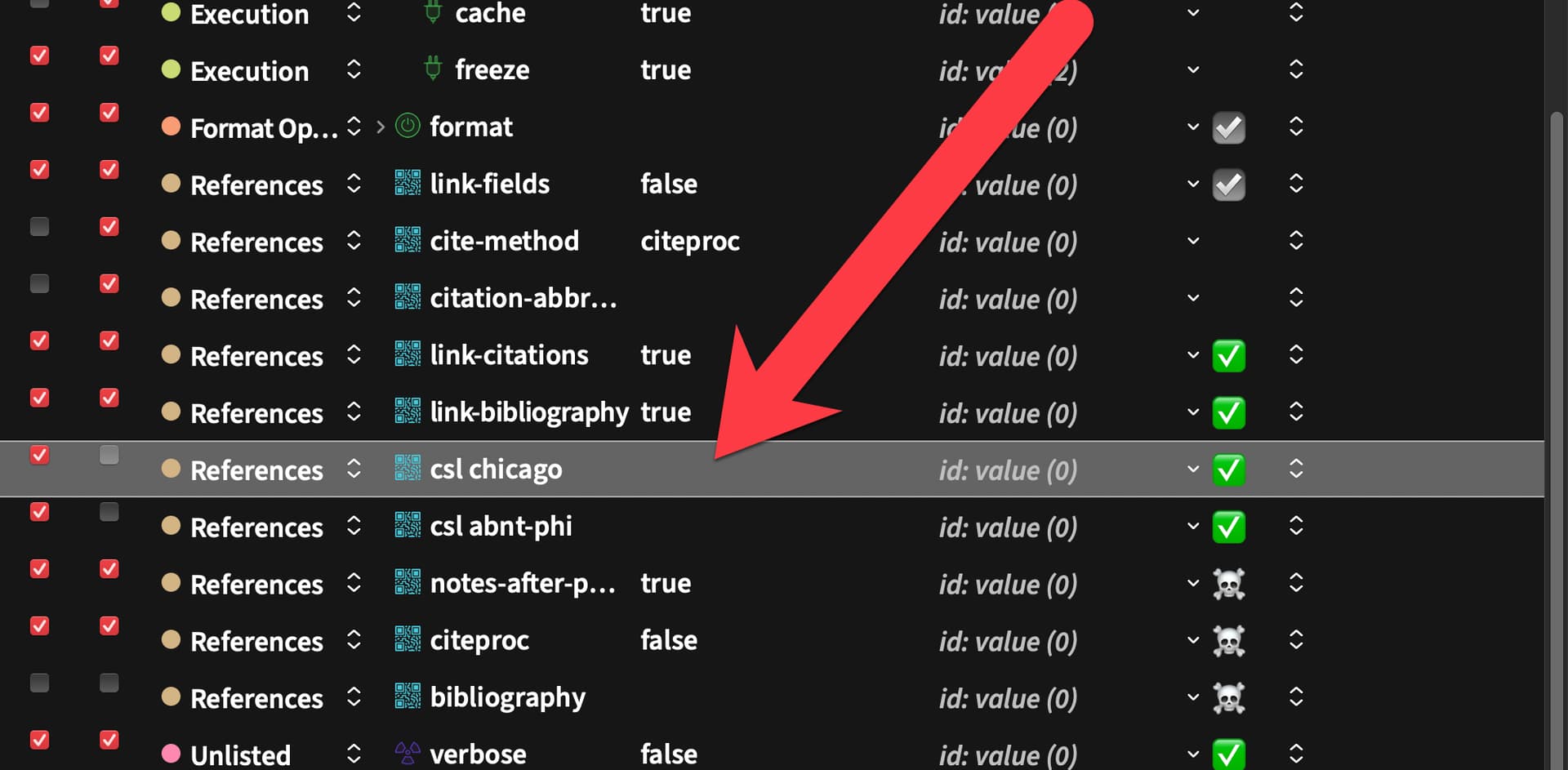
This means that it can output any combination of these parameters in any file it creates, which makes it ideal for maintaining complex projects. Or you can ignore all of that and simply use it as it is. It already demonstrates how to keep a simple CSL-YAML bibliography in the project itself (which is not to say that you can’t simply paste and keep a BibTeX bibliography).
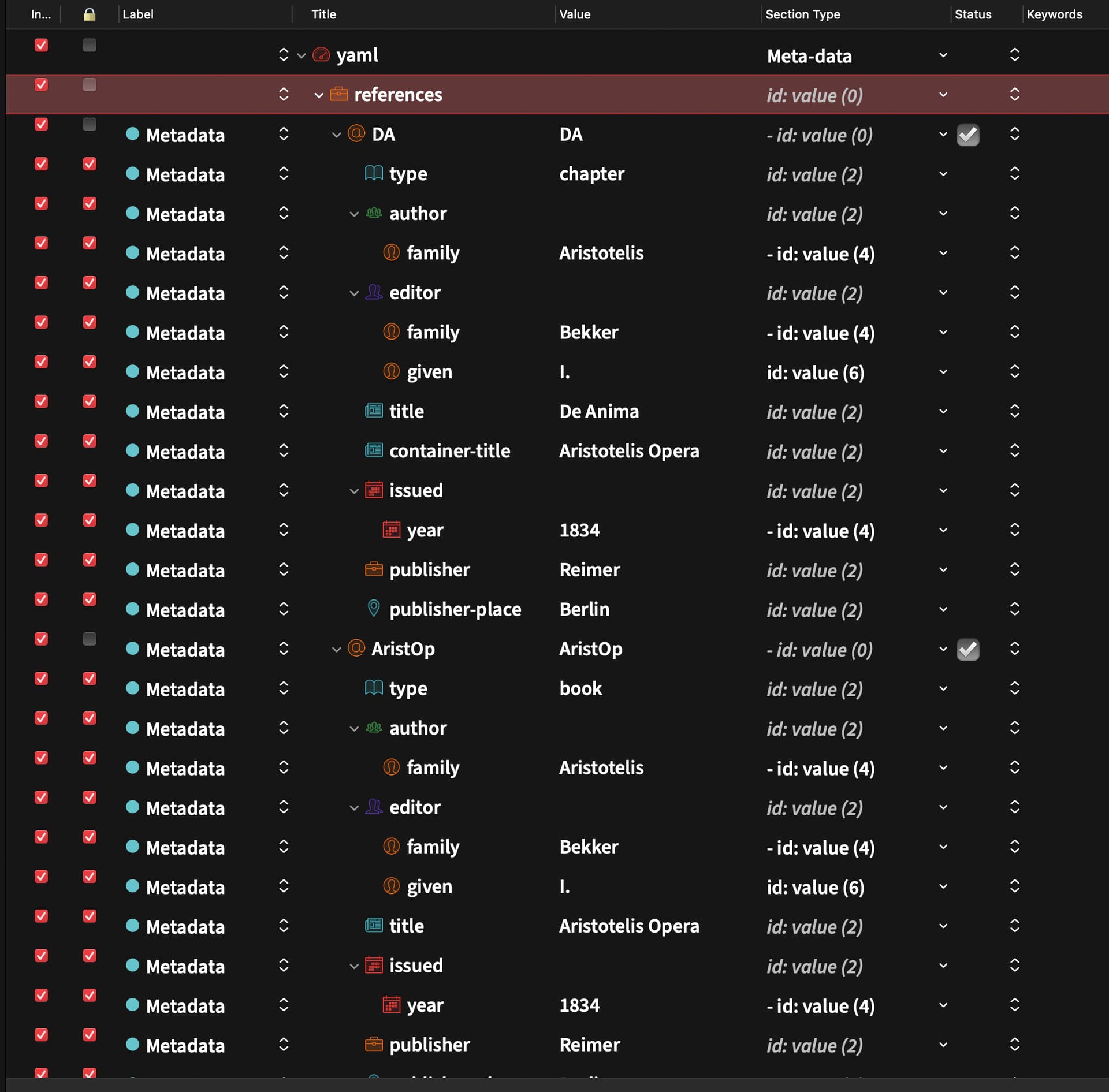
It includes all the advanced bibliography features from my previous template, including the Cite Tools integration; but now we have the option of keeping everything within the Scrivener project. You can check right there in Scrivener the author name that will come up if you apply the style Cite Author to a given reference. This is all optional, of course. I don’t keep my bibliography files inside the project, but it is very useful for creating self-containing examples.
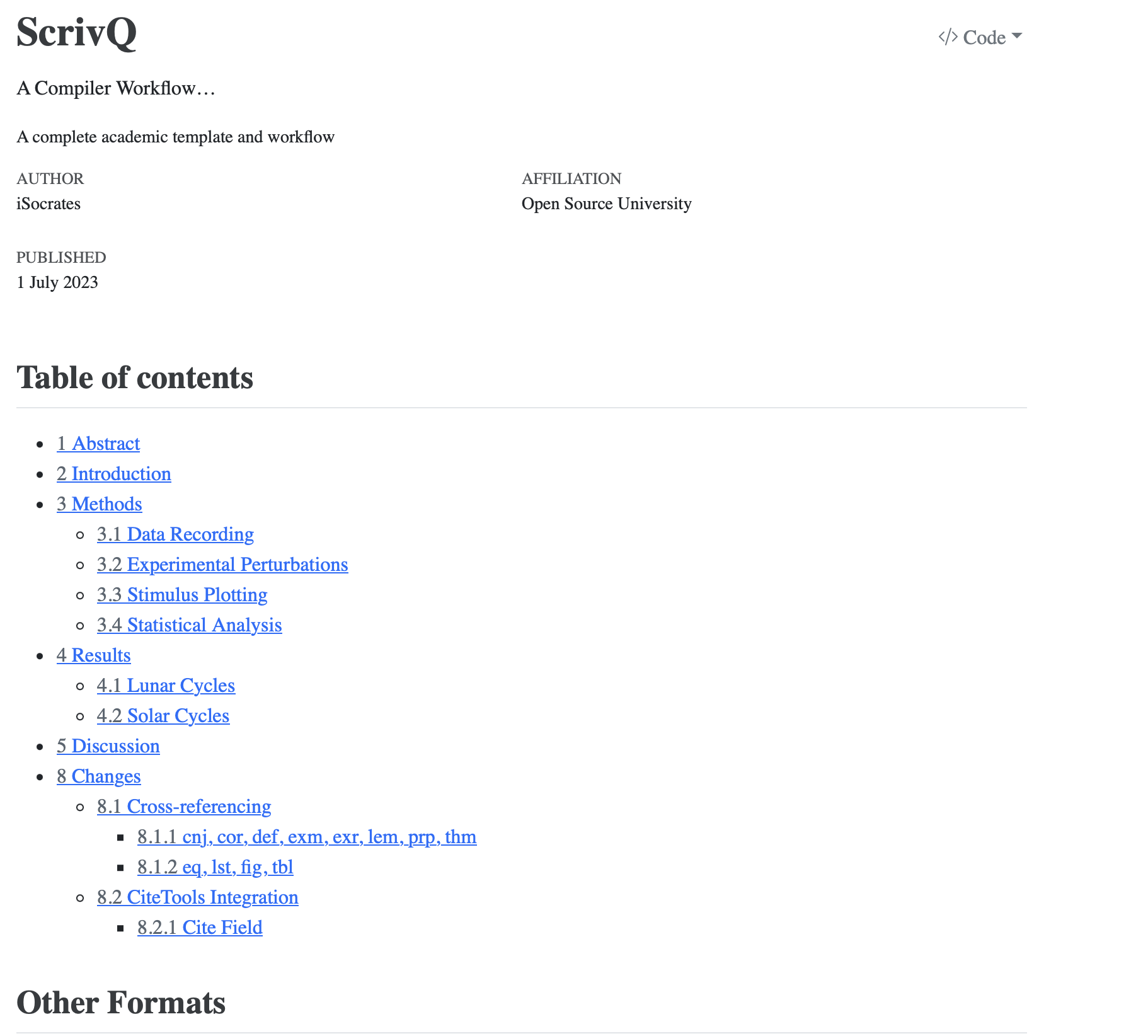
Cross-references
The cross-reference mechanism received special attention. Any element that can be referenced will automatically receive a label, so all we need to do is create a link and apply the character style corresponding to the element (figure, equation, table, listing, etc). And did I mention that we have all of the main amsthm environments already set up (Conjecture, Corollary, Definition, Example, Exercice, Lemma, Proposition, Theorem)?

There are several other important features and elements that I will skip mentioning for lack of time. With this, I noticed better than ever that documenting stuff you come up with is so much more work than getting it done in the first place. I try to explore everything in the template itself. Explore, enjoy. I am pretty satisfied with it and I hope you will be, as well.
Sidenote: with 34MB, it is a bit on the heavy side. This is mainly due to the icons and the elevated number of parameters. I suggest keeping this version and making another slimmed-down template version for your daily needs. You won’t need all the options all of the time.