@kewms, Thank you for that suggestion! I had placed the prefix/suffix in the tabs named “Prefix” and “Suffix” – not in the “Title Options” tab, where another prefix/suffix option exists.
For other Scrivener users who may be confused, the prefix/suffix in the “Title Options” tab will only append something before/after the title, and this will appear at the top of a section.
In contrast, the “Prefix” tab will allow you to place arbitrary text at the very top, before the section content – and also before the title (with its own prefix/suffix that was set up in Title Options). The “Suffix” tab allows you to place arbitrary text at the very bottom, after the section content.
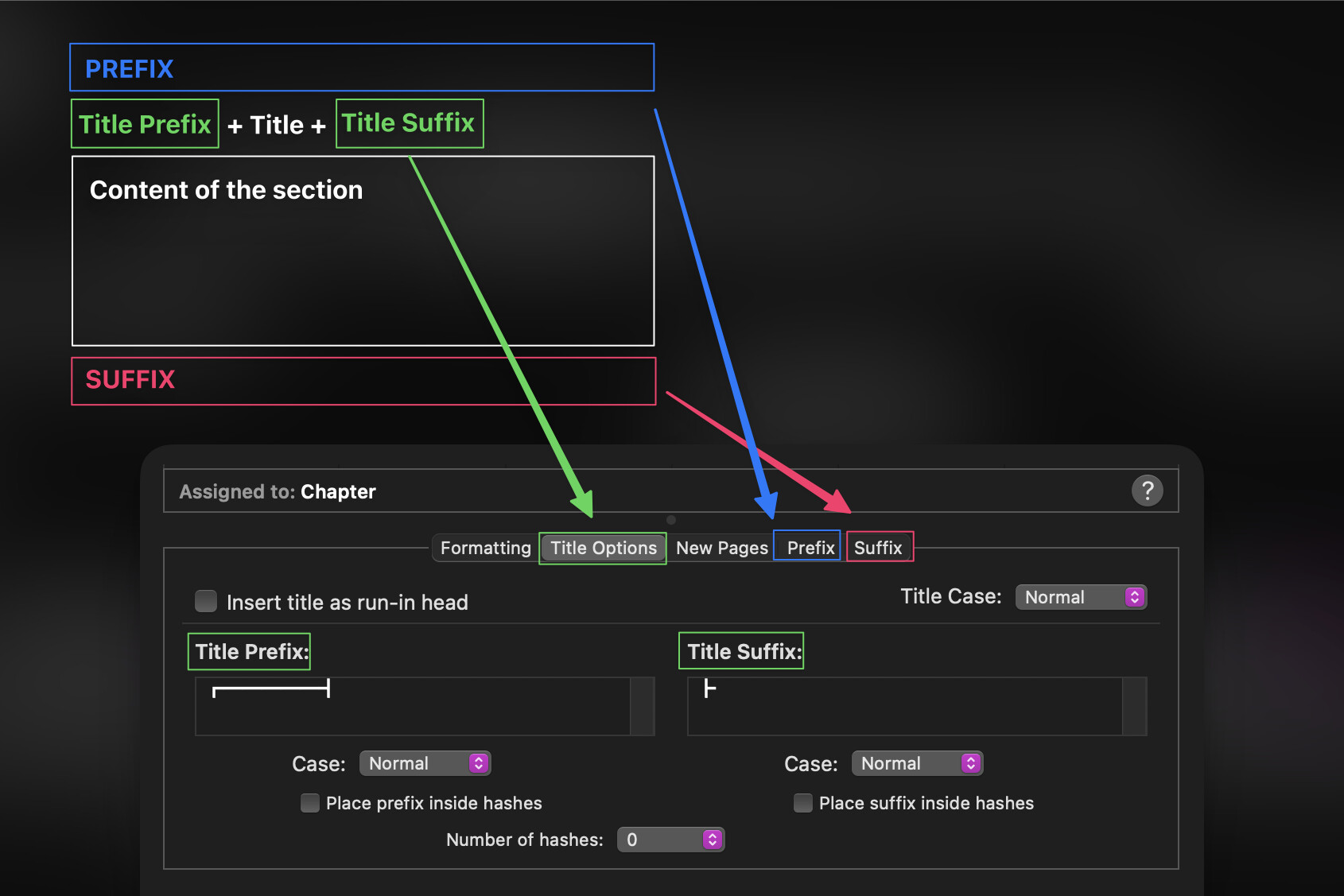
So now, I entered the “Title Prefix” and “Title Suffix” as seen in the screenshot, and I deleted the “Prefix” and “Suffix”. I only wanted a delimiter above each text section that included the title from the Binder. So it appears as ┏━━━━━┫Title┣ in the compiled .md file, as seen below.
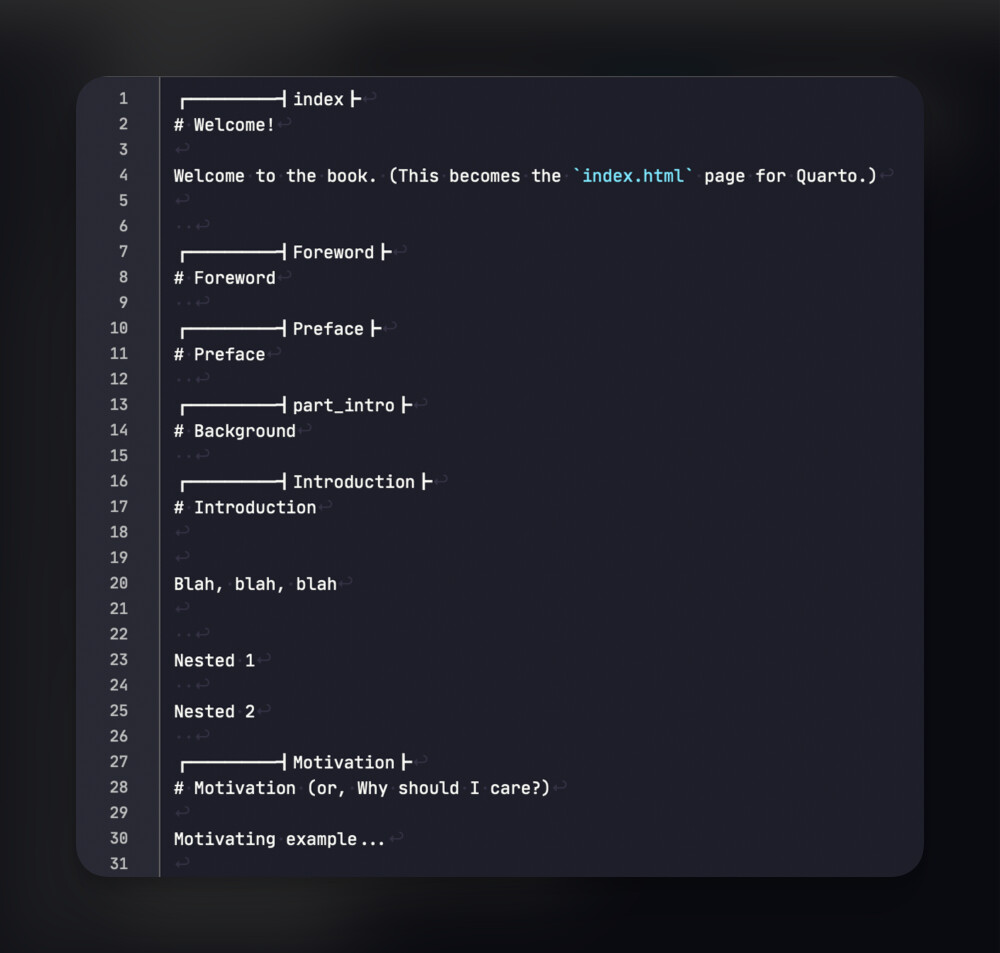
And these delimiters are easily parsed by the Python code in Squarto, capturing dictionaries with {slugified_binder_title, binder_title, first_line, and content}. The entire Scrivener document is stored in a list of these dictionaries. So to refer to a specific element from the Binder, let’s say the 5th element,[1] the content (parsed_texts[4]['content']) is written to the corresponding file (named parsed_texts[4]['slugified_binder_title'] plus .qmd extension).
SQUARTO STATUS CHECK 2024-09-30:
- This little diversion has now enabled Squarto to parse the Scrivener compiled .md file into chapters that correspond to the individual items in the Binder;
moreover, grouped (nested) text files are aggregated into one chapter named after the topmost group title.[2] Thanks to @nontroppo for suggesting that I explore this option. - Doing this is a different approach for “getting the content” from that which I described earlier for Squarto, in which the content.rtf > filename.qmd conversion was managed by Squarto. With this new approach of parsing the compiled .md file, we allow for Scrivener to handle the .rtf > .md conversion (so the user can take advantage of any of the other features Scrivener offers in its Compile workflow) but still get the content to where it needs to be for Quarto, in a folder/file hierarchy that is also outlined in the _quarto.yml file.
- Ultimately, I think Squarto will allow for both approaches. If it is run as a post processing script from within Scrivener’s Compile window, it will start by parsing the compiled .md file. On the other hand, if Squarto is run from the command line directly on a .scriv file (without opening Scrivener), it will process everything automatically by itself, without needing Scrivener to do the compilation.