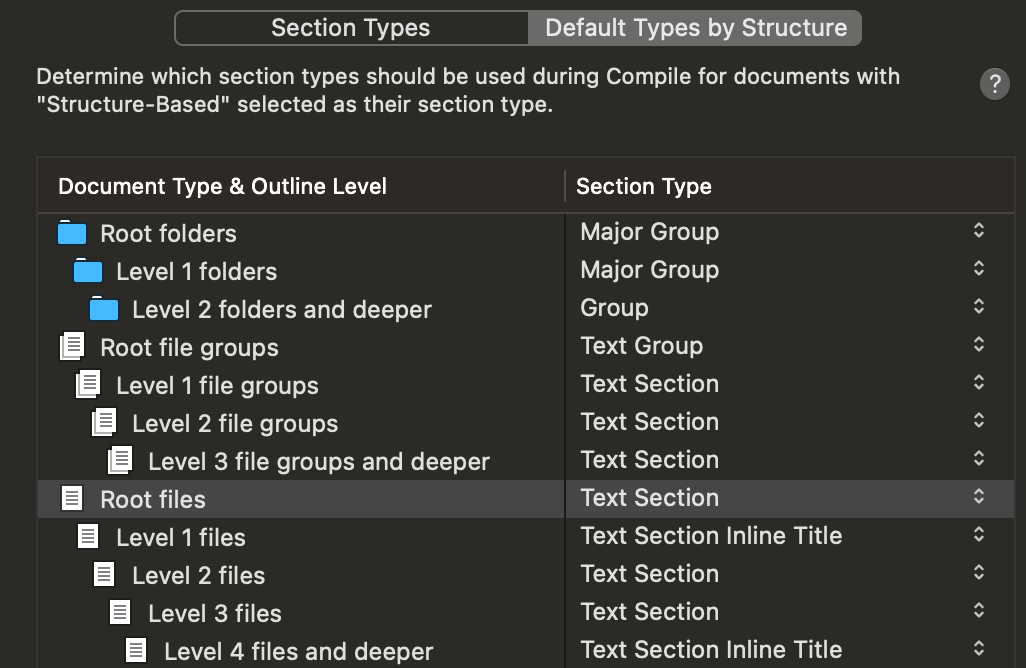
UPDATE 2024-09-23:
It took me awhile, but I figured out how to add a feature to Squarto so that it would extract the Style info from the .scriv package – specifically, from three sources,
.scriv/Files/styles.xml.scriv/Settings/Compile Formats/Squarto.scrformat.scriv/Files/Data/⟨UUID⟩/content.styles– each .rtf file will have a corresponding one if any Styles were applied to this document via Scrivener’s editor.
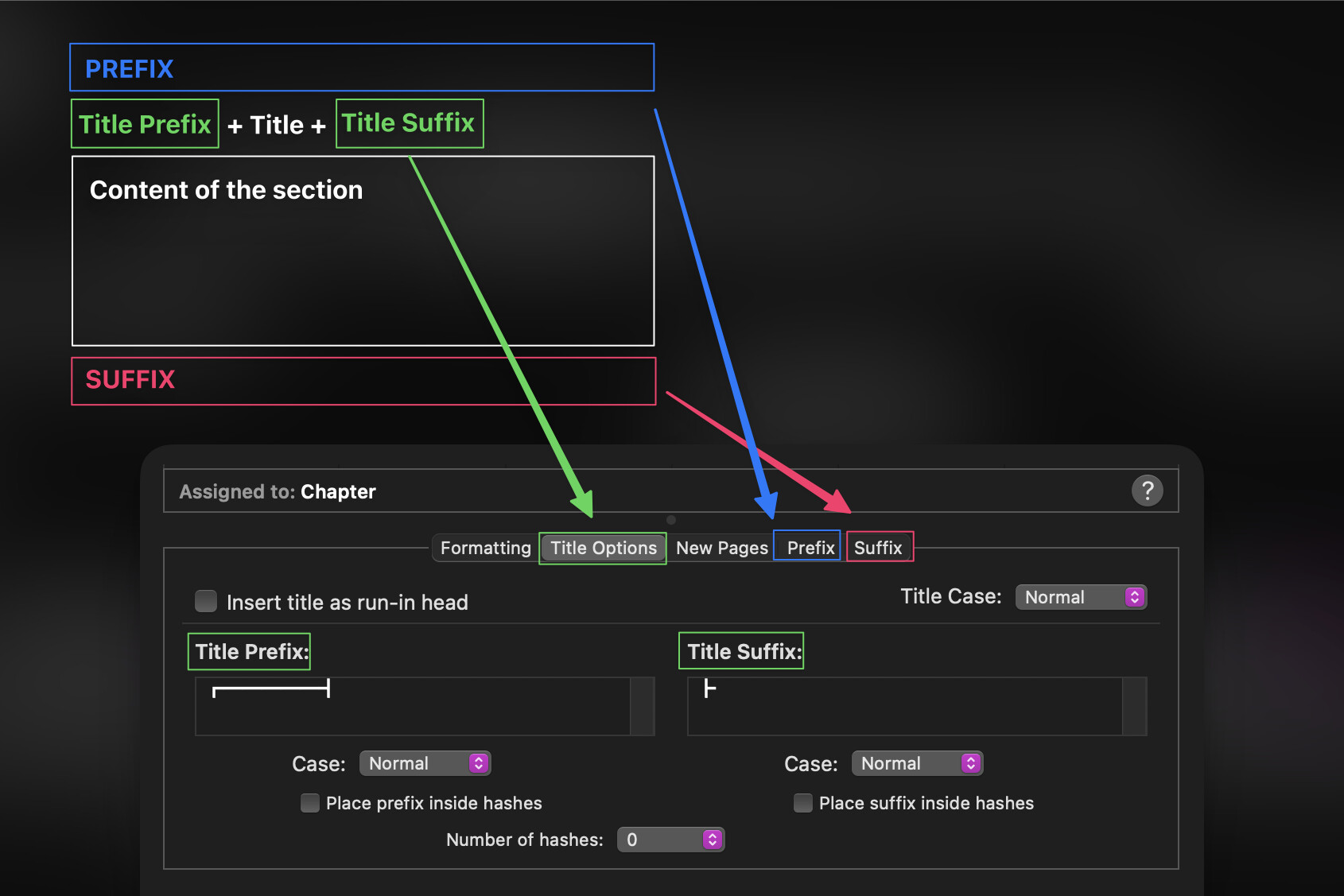
It involves a bunch of juggling to create the proper data structure because the styles.xml file encodes the style UUIDs, the .scrformat file encodes which prefix/suffix to use in replacement of each style (set up within Scrivener’s Compile settings when editing the compile format), and the individual content.styles files are essentially a comma-separated value (CSV) file of the UUIDs utilized in a corresponding content.rtf, with the index position of that UUID being the number that appears in Scrivener’s style markup tags – e.g., <$Scr_Cs::0> refers to the UUID in the 0th position.
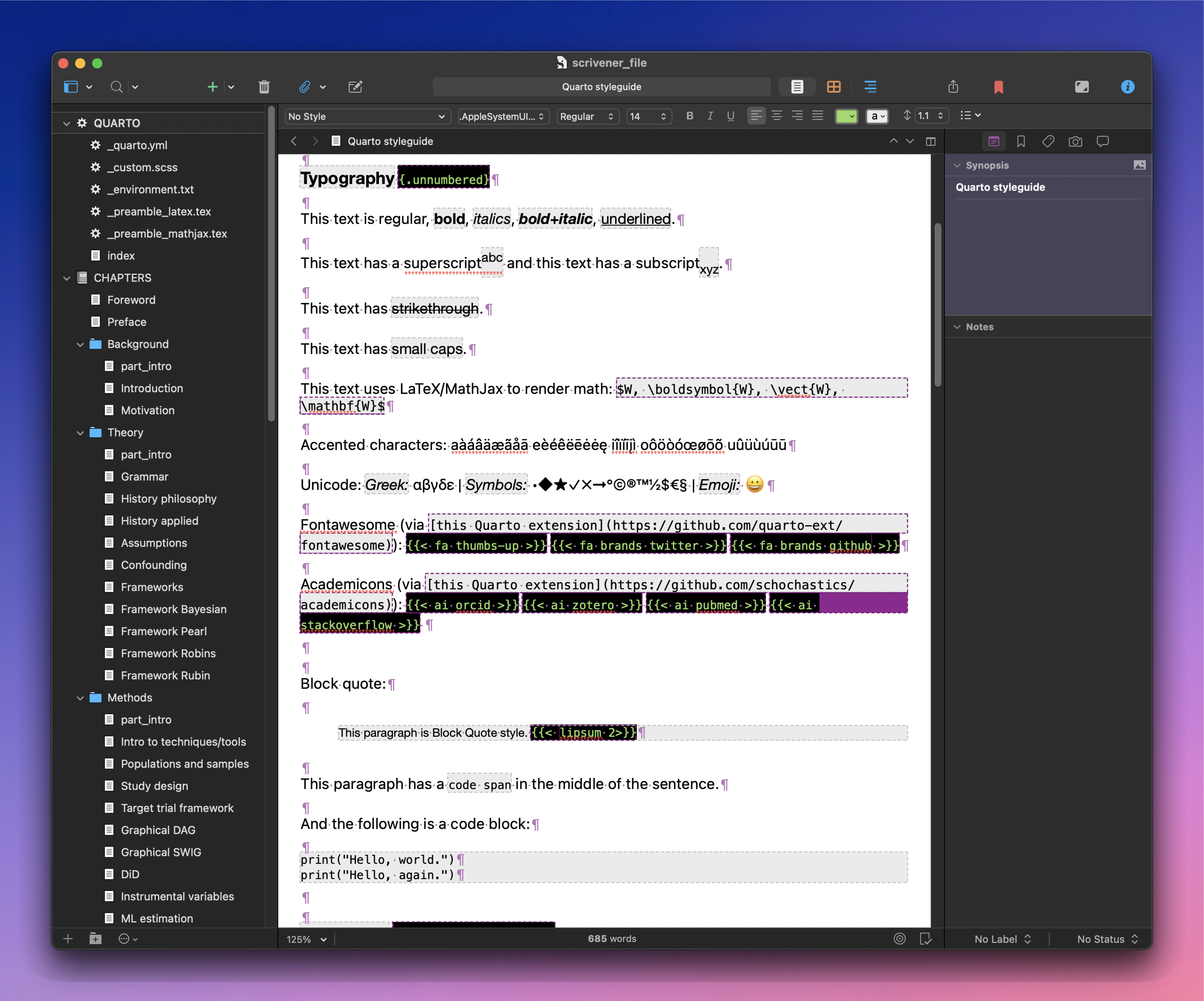
Long story short, what this means is that Squarto will now compile Scrivener Styles, so I can now use Scrivener’s Styles to eliminate the need to write routine Markdown tags. But Squarto also allows me to write in raw Markdown (it is respected by default).
The best part is that the styles are not “hardcoded” – rather, the style info is extracted from the .scriv package at the time that Squarto is run, so if you add/delete/edit a Style via Scrivener, or if you change the prefix/suffix in the compile format settings, the next run of Squarto will detect and implement the updated info automatically.

I’m pretty excited about the progress so far. Now that this is working, I am going to fine-tune my Styles so that they look better within Scrivener.
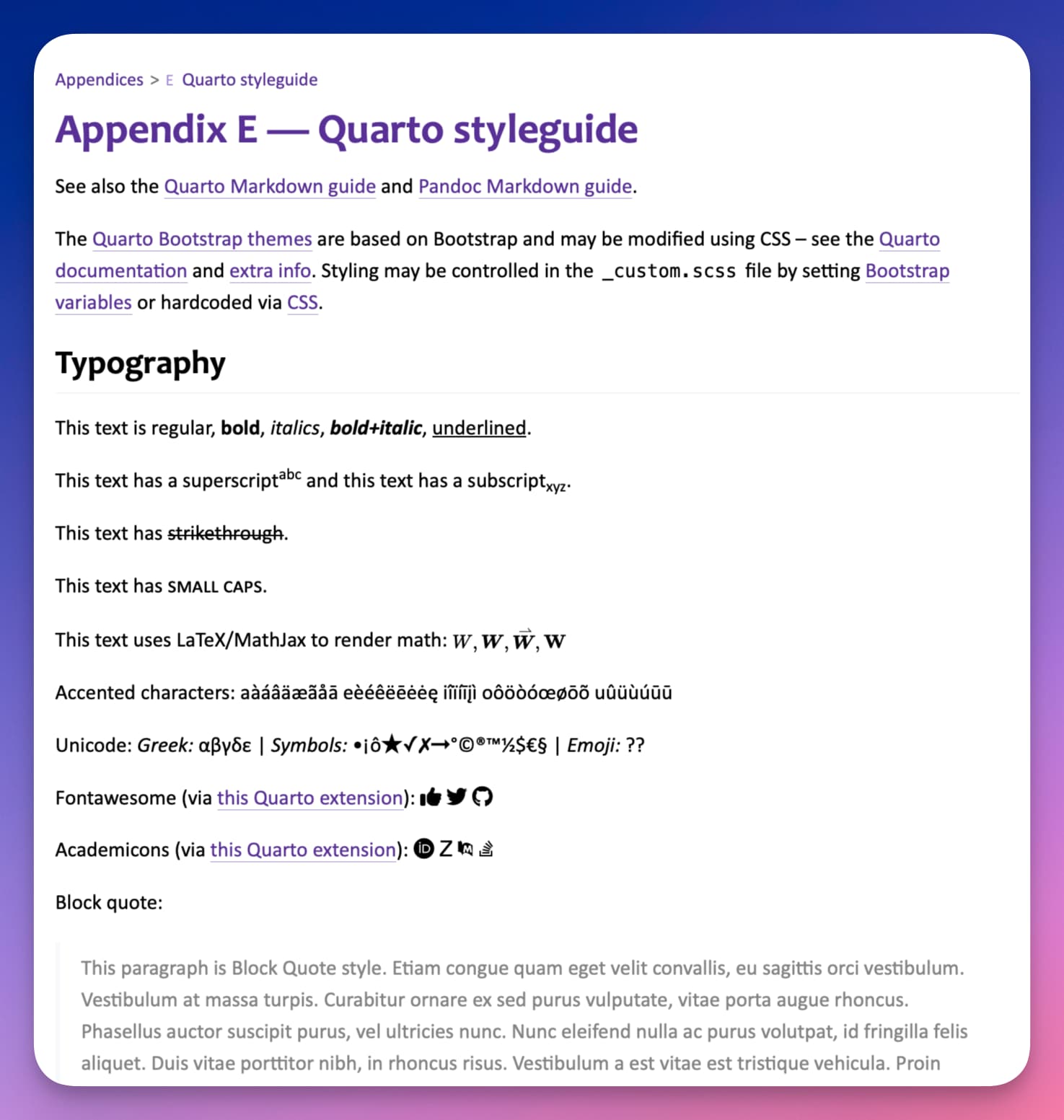
One thing I’m having trouble with: Converting Emoji. Interestingly, other Unicode symbols work, but Emoji cause an error (so Squarto catches the error and replaces the Emoji with a ? symbol). It would be nice to get Emojis to work though. Luckily, Quarto does have extensions for fancy icons, like Fontawesome and Academicons.
Next on my to-do list:
To work on processing of figures/images that are stored in the Binder or embedded (cut-n-pasted) into one of the text documents.
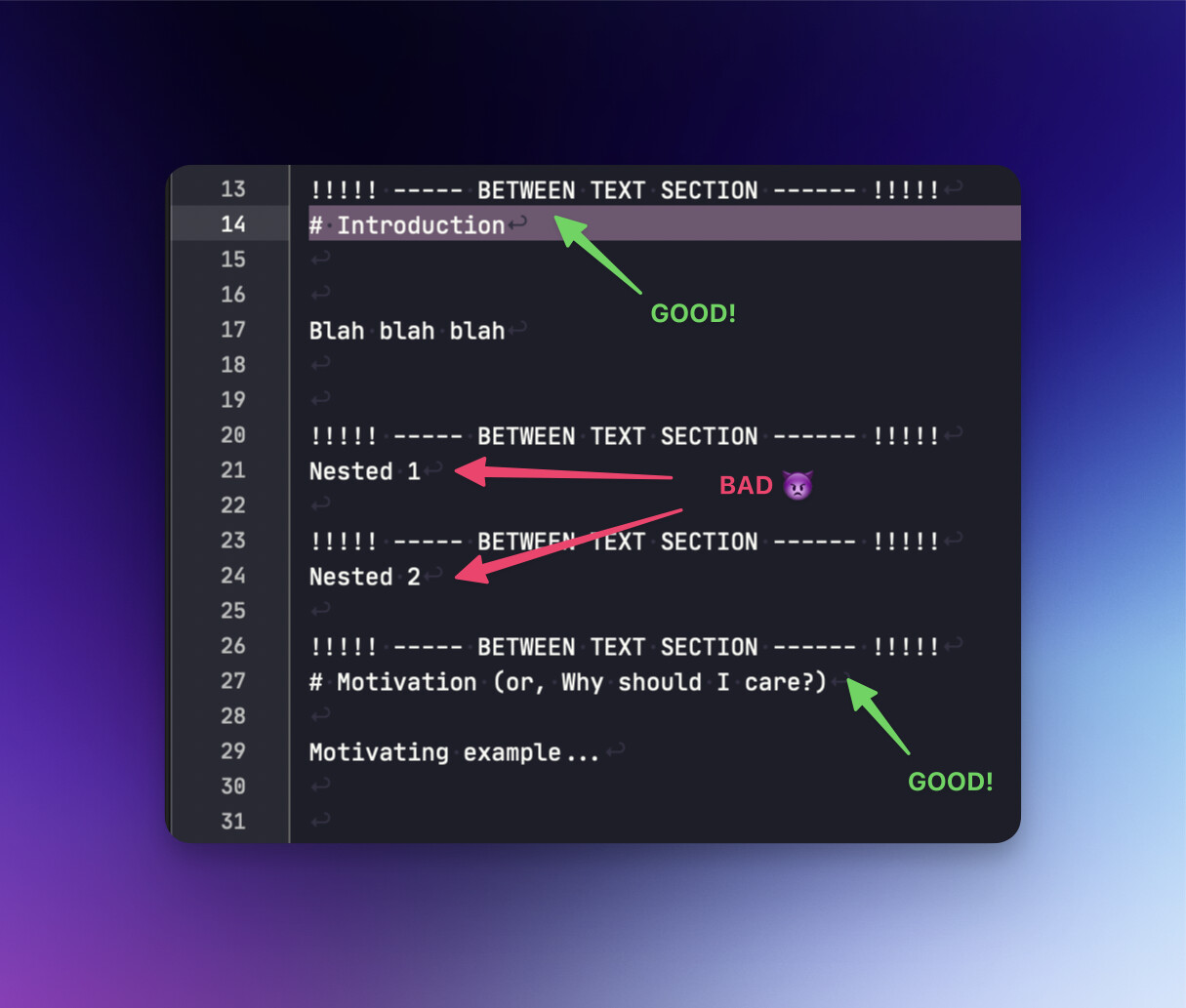
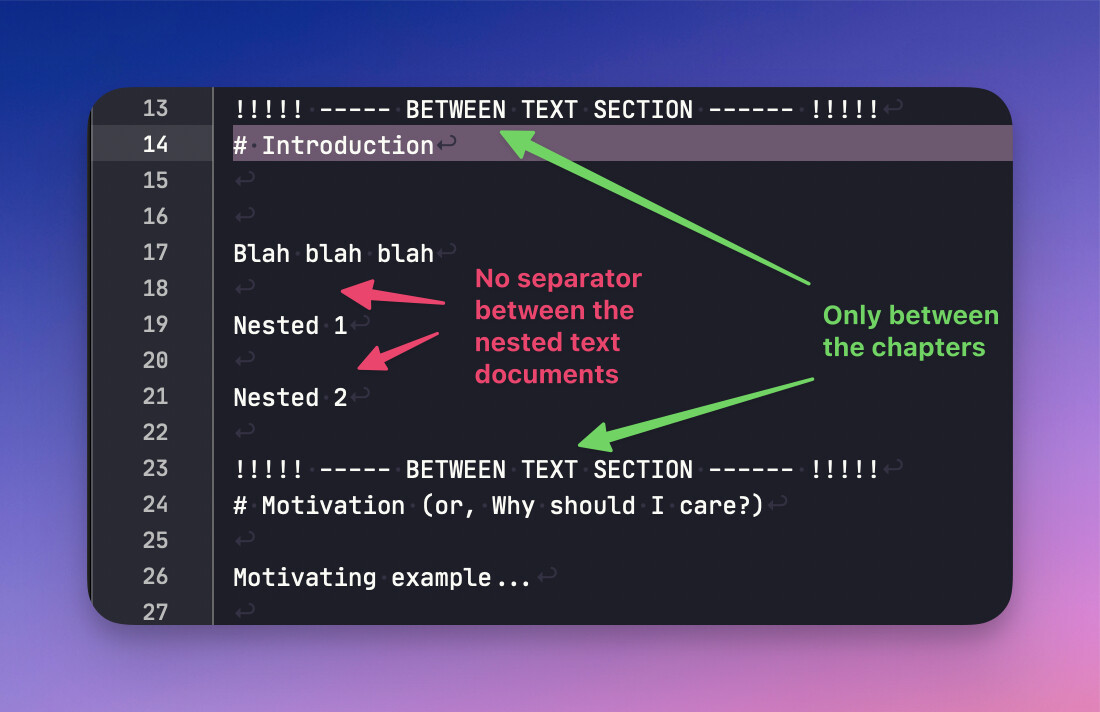
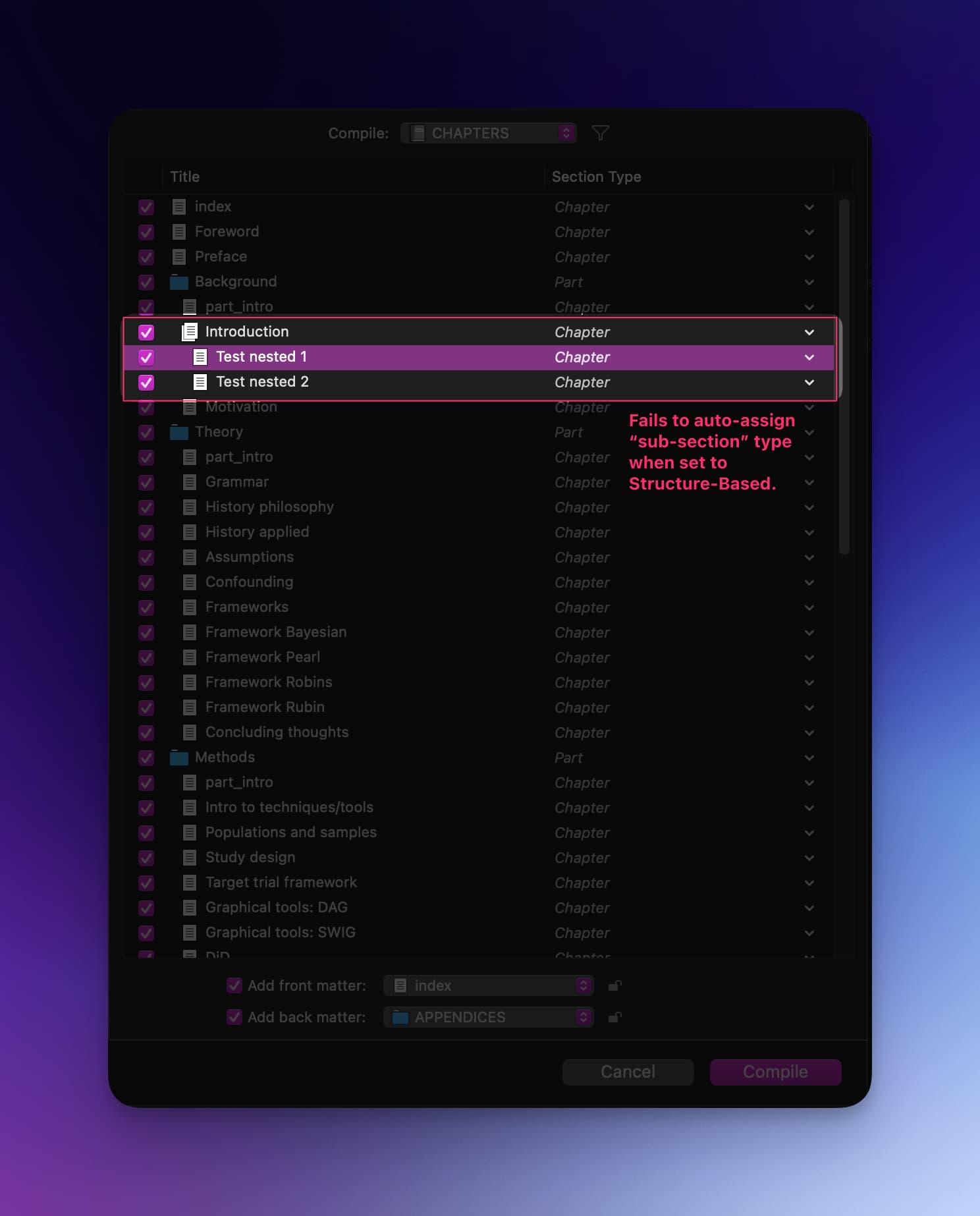
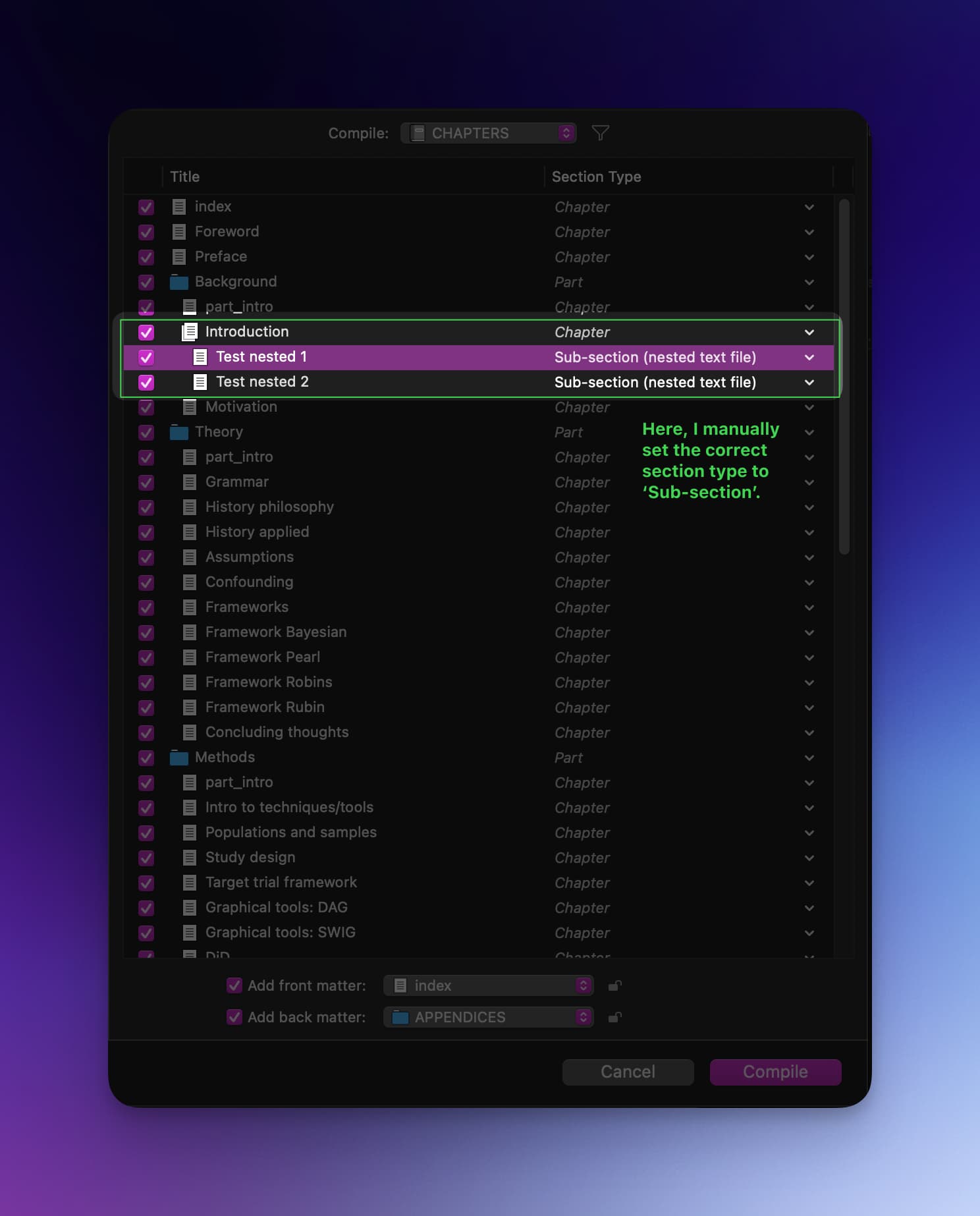
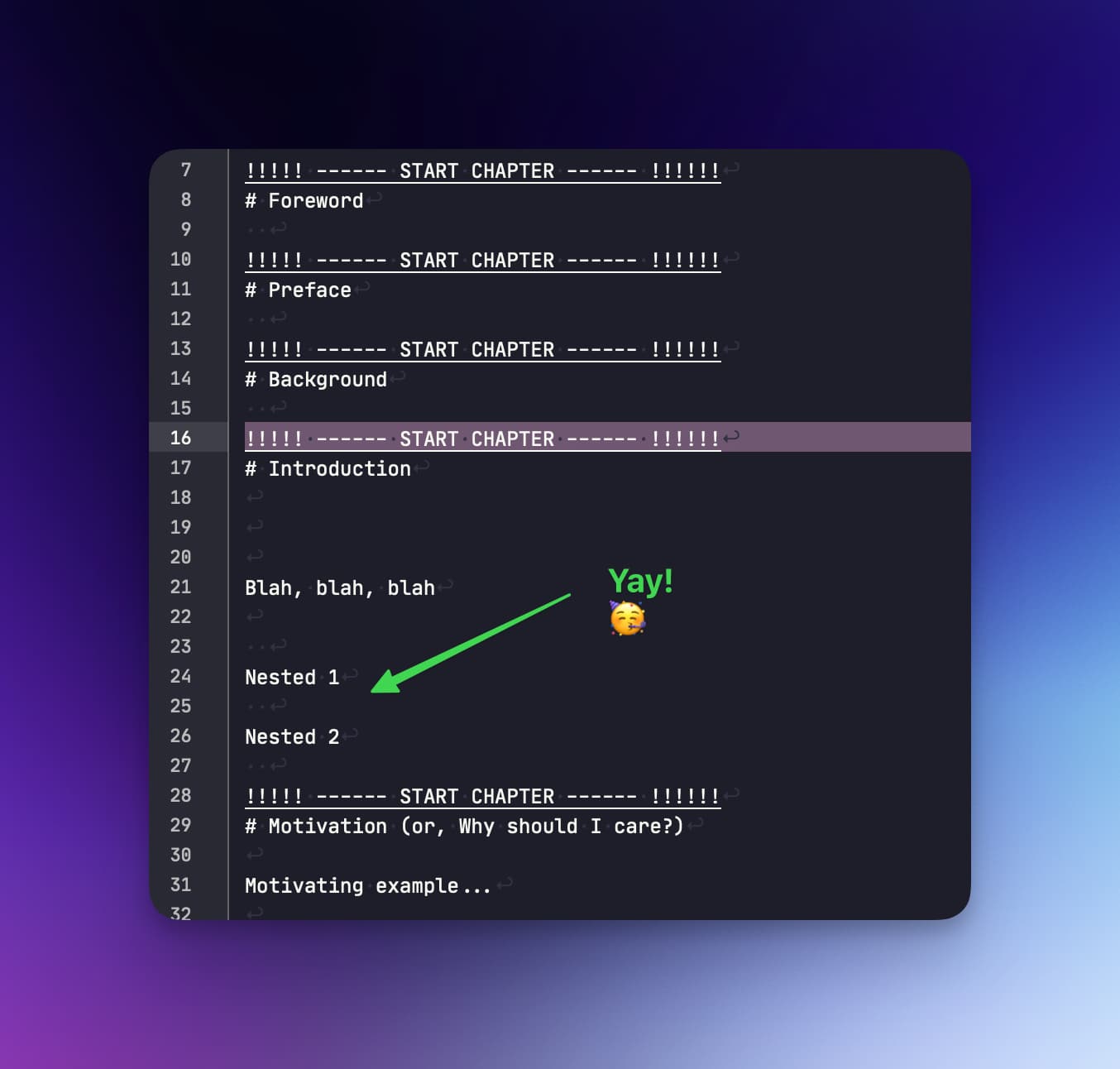
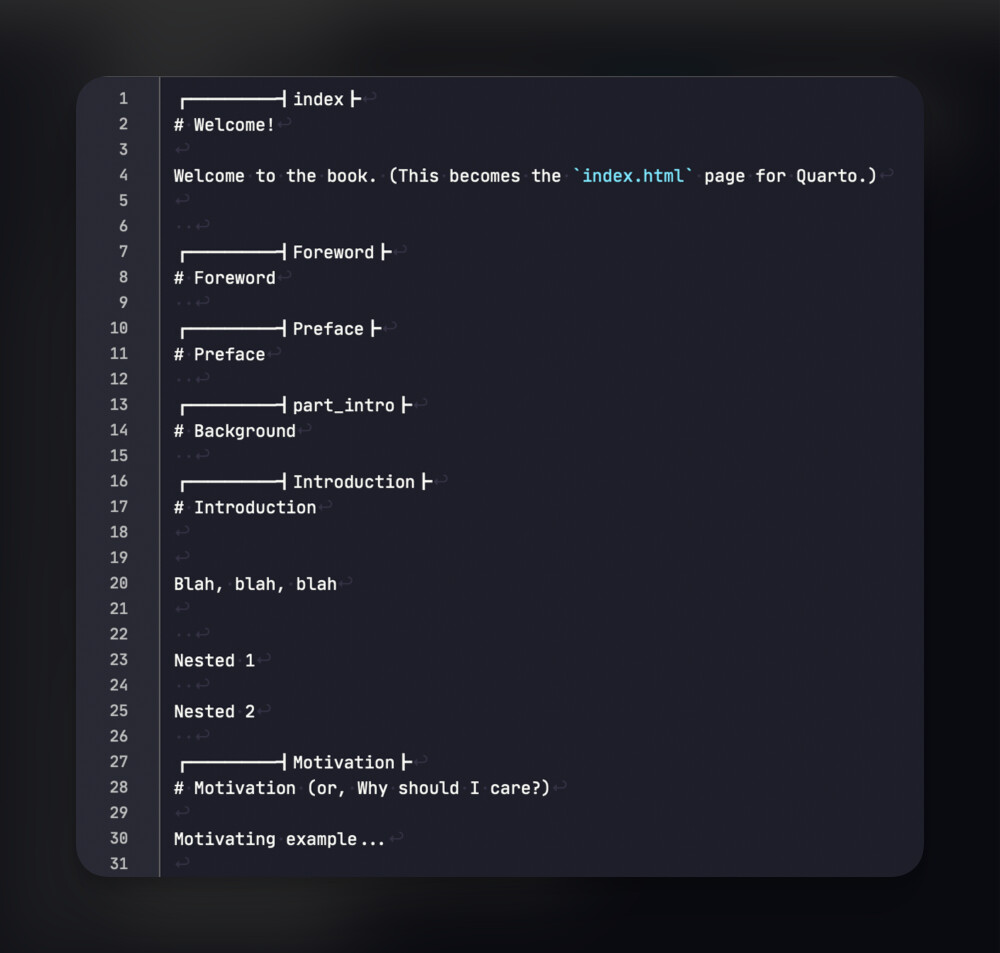
To get nested text documents to be collated into the parent as a single chapter.
To refactor Squarto into a CLI that accepts the .scriv package filename as an argument
To set up Squarto to run via the File > Compile command (so I don’t have to run it separately at the command line).
Again, a big THANK YOU to Keith Blount and the rest of the Scrivener development team for making the .scriv file so parsable. It is creative, effective, and very forward-thinking.