Squarto update 2026-02-07
For readers unfamiliar with this thread, Squarto is my Python application that is designed to permit writing in Scrivener, outputting the appropriate folders and files for a Quarto project, and then exporting the final products such as PDF. Quarto itself is a system for scientific and technical writing that integrates Markdown, LaTeX or Typst, and executable code (R, Python, Julia, etc.).
Squarto has evolved quite a lot, most significantly in architectural design, but also in approach. While I do use it for some “real work,” Squarto remains a work-in-progress and hobby project.
Here’s an update to the workflow in early 2026:
Squarto has a CLI and TUI
The main way to run Squarto is via the command line, such as squarto new and squarto build. When installed by uv as a tool, Squarto can be run anywhere and its dependencies are taken care of for the user (no virtual requirement need be created).
I also created a text user interface (TUI) using the excellent Textual library to facilitate visualization of certain features.
A Squarto project has a standardized structure
Inspired by Cookiecutter/Copier and even Scrivener itself, I designed the squarto new command to create a new Squarto project as a hierarchy of nested folders and files:
📁/squarto_project_title/
│
├── 📁/_squarto_settings/
├── 📁/scrivener/
│
├── 📁/quarto_project/
│
├── 📁/products/
│
└── 📁/temp/
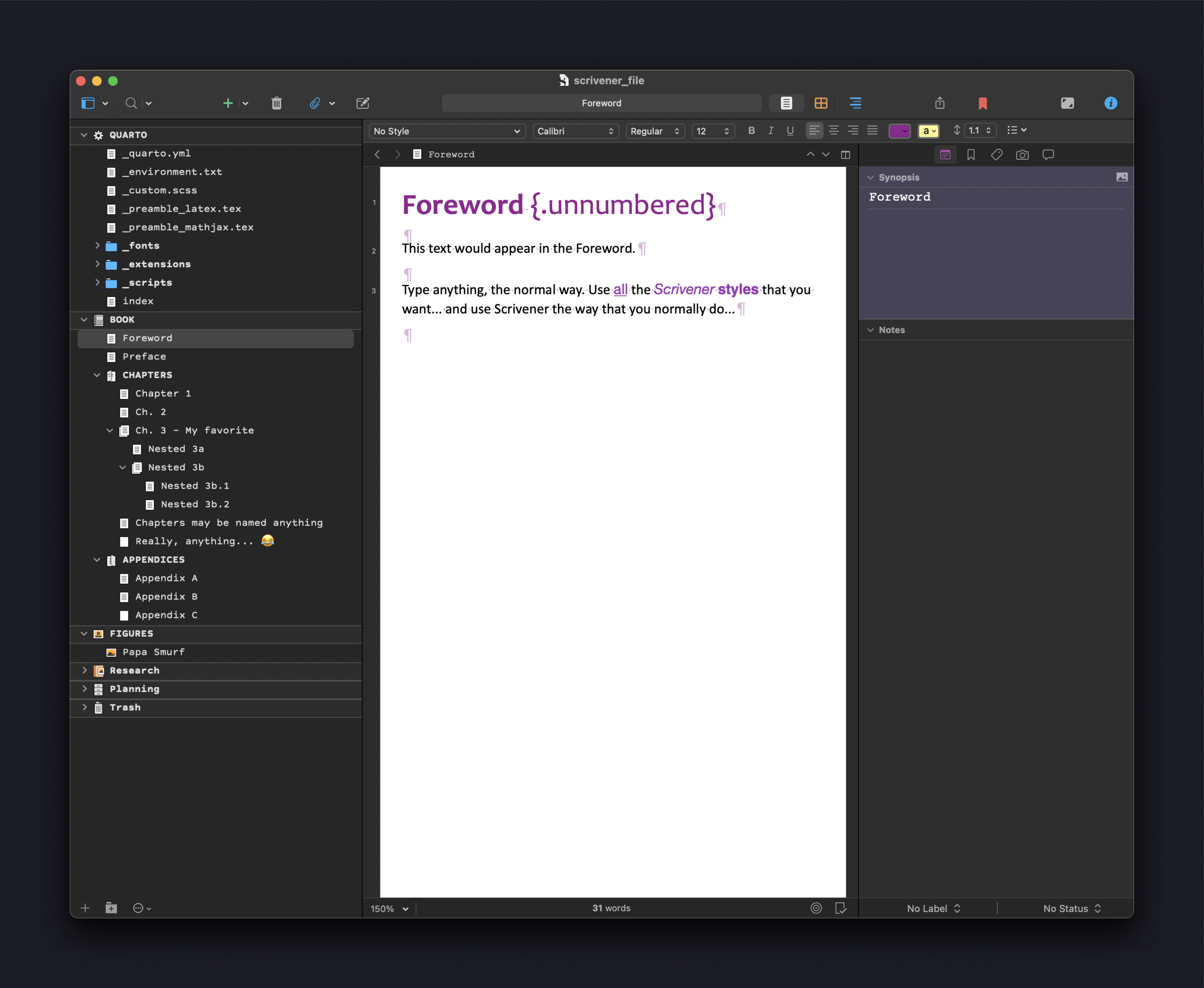
Writing takes place in Scrivener
All writing takes place in Scrivener, i.e. in my_project_title.scriv in the file listing below.
📁/squarto_project_title/
│
├── 📁/scrivener/
│ ├── 📁/my_project_title.scriv/
│ └── 📁/compiled/
The Scrivener implementation is a custom template (with Styles, metadata, and compile format).
I’ll describe the Scrivener template itself in another post. It is similar to what I posted previously and also similar to (inspired by) the approach taken by others, such as @nontroppo.
Because all writing is done in Scrivener, you can use all of its tools that help you write. Squarto doesn’t change any of that. It is only used when it comes time to compile.
Important settings are stored outside of Scrivener
In an earlier iteration of Squarto, I was trying to store everything in the Binder and then extract it all at compilation time. This had several downsides: (1) the size of the Scrivener package would balloon if you were storing fonts and Quarto extensions in there; (2) it was rather frustrating to edit some plaintext documents in Scrivener (such as YAML or JSON files). It made sense to store these assets outside of the Scrivener package itself. This is the main reason that I transitioned to making a “Squarto project” have a dependable structure.
Now, the /squarto_settings/directory contains the important bits, which includes Squarto’s settings, Quarto extensions, “presets” (which includes Quarto YAML configuration, LaTeX or Typst partials, CSS, font files, etc.), and templates (like DOCX templates).
📁/squarto_project_title/
│
├── 📁/_squarto_settings/
│ ├── 📄_squarto_settings.toml
│ ├── 📁/quarto_presets/
│ ├── 📁/quarto_extensions/
│ └── 📁/templates/
Presently, all these files need to be locally stored, but my plan is to allow for linking to external assets.
Specifically, I think that Quarto extensions might simply be specified in the settings TOML file and installed during compilation (instead of storing them in each project’s folder). The inspiration for this comes from uv, which does a great job at dynamically installing dependencies when a tool is run.
So I will continue to streamline this.
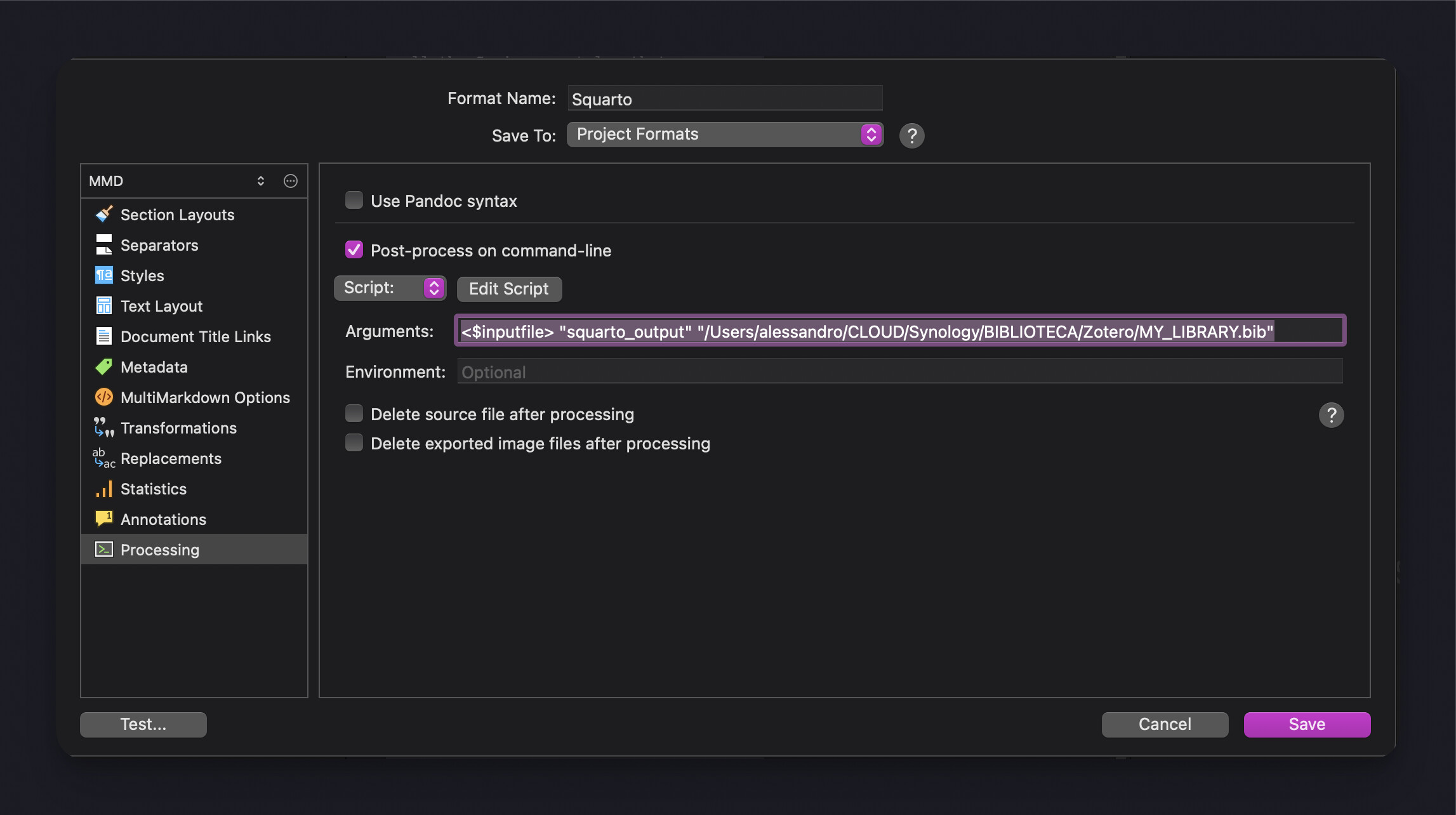
The Squarto settings TOML file is very powerful
A huge step forward for me was to bite the bullet and create a Squarto settings file that would be totally separate from the Quarto config. Quarto prefers using YAML, but I find it a bit annoying to write YAML; so I decided to use TOML instead. Here is what the _squarto_settings.toml file looks like:
[squarto]
squarto_project = "path/to/sample_squarto_project"
# Scrivener flags
build_from_scrivener_compiled_md = false
check_scrivener_includeincompile = true
exclude_scrivener_folders = [
"PLANNING",
"RESEARCH",
]
# Squarto flags
empty_quarto_project_dir_if_already_exists = true
empty_products_dir_if_already_exists = true
enable_citation_and_bibliography = true
copy_bib_file_locally = true
copy_csl_file_locally = tru
logging = true
verbose = true
# Quarto flags
quarto_preset = "default"
quarto_project_type = "book"
autorun_quarto_render = true
[processors]
quarto = "/usr/local/bin/quarto"
pandoc = "/opt/homebrew/bin/pandoc"
tex = "/Library/TeX/texbin/tex"
latex = "/Library/TeX/texbin/latex"
xetex = "/Library/TeX/texbin/xetex"
lualatex = "/Library/TeX/texbin/lualatex"
pdflatex = "/Library/TeX/texbin/pdflatex"
[bibliography]
bib_file = "/path/to/Zotero/MY_LIBRARY.bib"
csl_file = "/path/to/Zotero/styles/apa.csl"
In the [squarto] section, there are flags related to Scrivener, Squarto itself, and Quarto. For example, build_from_scrivener_compiled_md = false means that Squarto will not depend on a previously compiled Markdown document that Scrivener created; rather, Squarto will compile the Scrivener document from scratch (on its own). But the flag check_scrivener_includeincompile = true means that Squarto will still respect the Binder/DraftFolder items that were designated (within Scrivener) to be included at compile time.
The parameter exclude_scrivener_folders is a nice one. I was frustrated that Scrivener would only include DraftFolder in compilation, allowing at most Frontmatter and Backmatter to be added. Any other root-level 0 folders could not be included in the compilation. For example, if you wanted to store folders ‘Appendices’ alongside ‘Draft’, this couldn’t be included in compile in an easy way. Now, Squarto includes everything in the Binder unless it is excluded explicitly in the exclude_scrivener_folders parameter. In the example above, I listed ‘Planning’ and ‘Research’ to be excluded.
The Squarto settings file also allows specification of paths to any processor that you want. This gets stored internally as a key:value dictionary in the format { command: path }. So if you want to refer to different tools from the usual, you can.
Similarly, this is the location where you can specify the location to the bibliography .BIB file and .CSL file that you want to use. If the flag copy_bib_file_locally is set to true, then Squarto will copy the .bib file into the Quarto project directory later; if set to false, then a symlink alias is created instead.
I think the TOML settings file was critical in development of Squarto. It makes Squarto very, very extensible.
In the future, I think I will also list Quarto extension dependencies here, so they can be installed at compilation time.
Any necessary virtual environments might be specified here as well – A virtual environment is not necessary for Squarto anymore, but if Quarto needs to execute any R or Python code in a virtual environment, this may be the mechanism to specify that. Quite simply, Squarto will finish the compilation, activate the virtual environment, and then handoff to Quarto (which will continue to run within the virtual environment).
Squarto compiles the Scrivener package directly
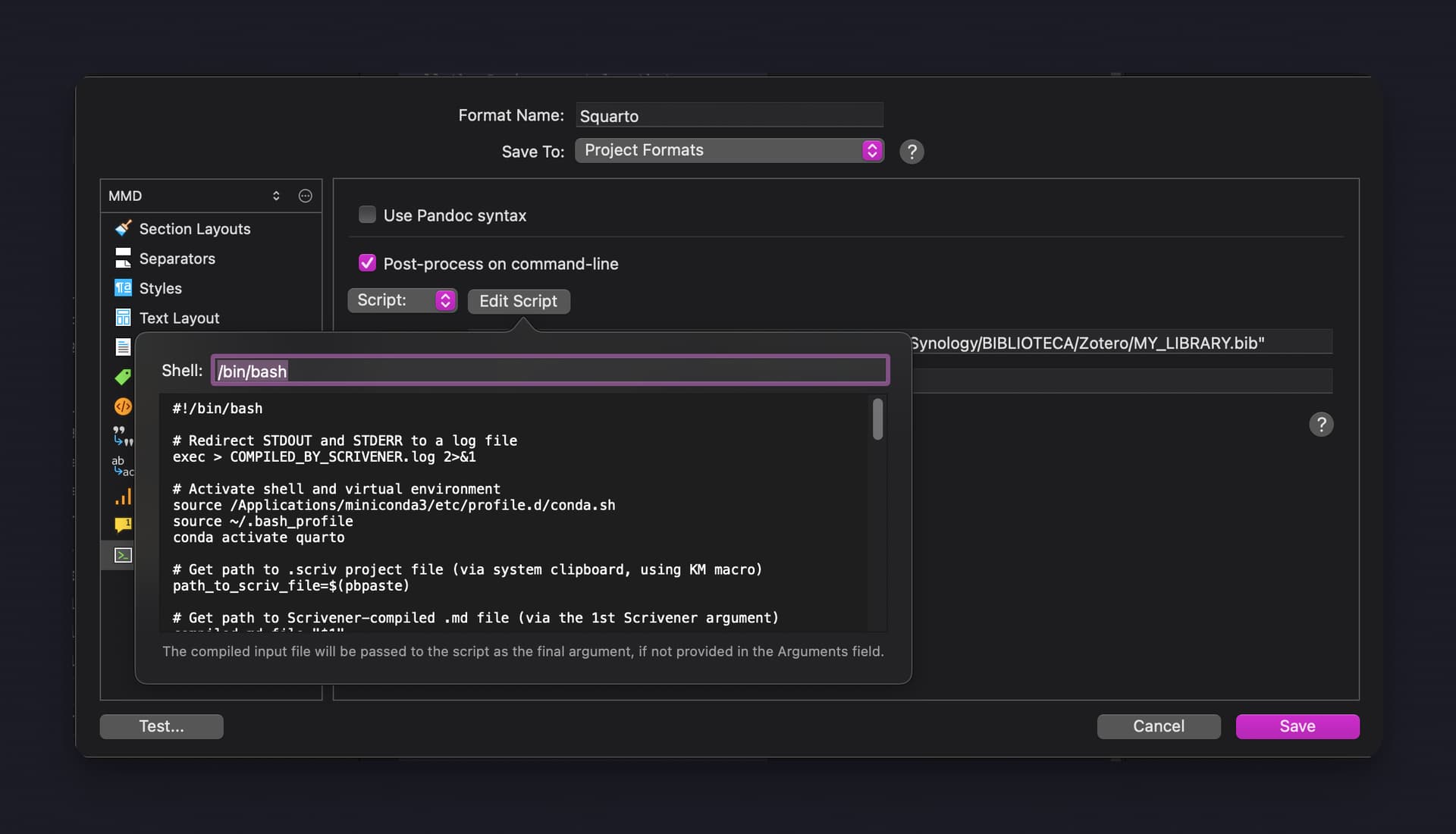
In its past iteration, Squarto relied on Scrivener to compile the items in the Binder, outputting a singular compiled.md file that Squarto would then chop up again into pieces. (This is actually the reason for the name squarto, a pun from the Italian squartare, meaning to dismember or to rip into pieces.) This approach still works, but it relied on a few hacks to pass the proper file paths and other parameters to Squarto. That story is too long to reiterate but may still be present in the posts above or other threads.
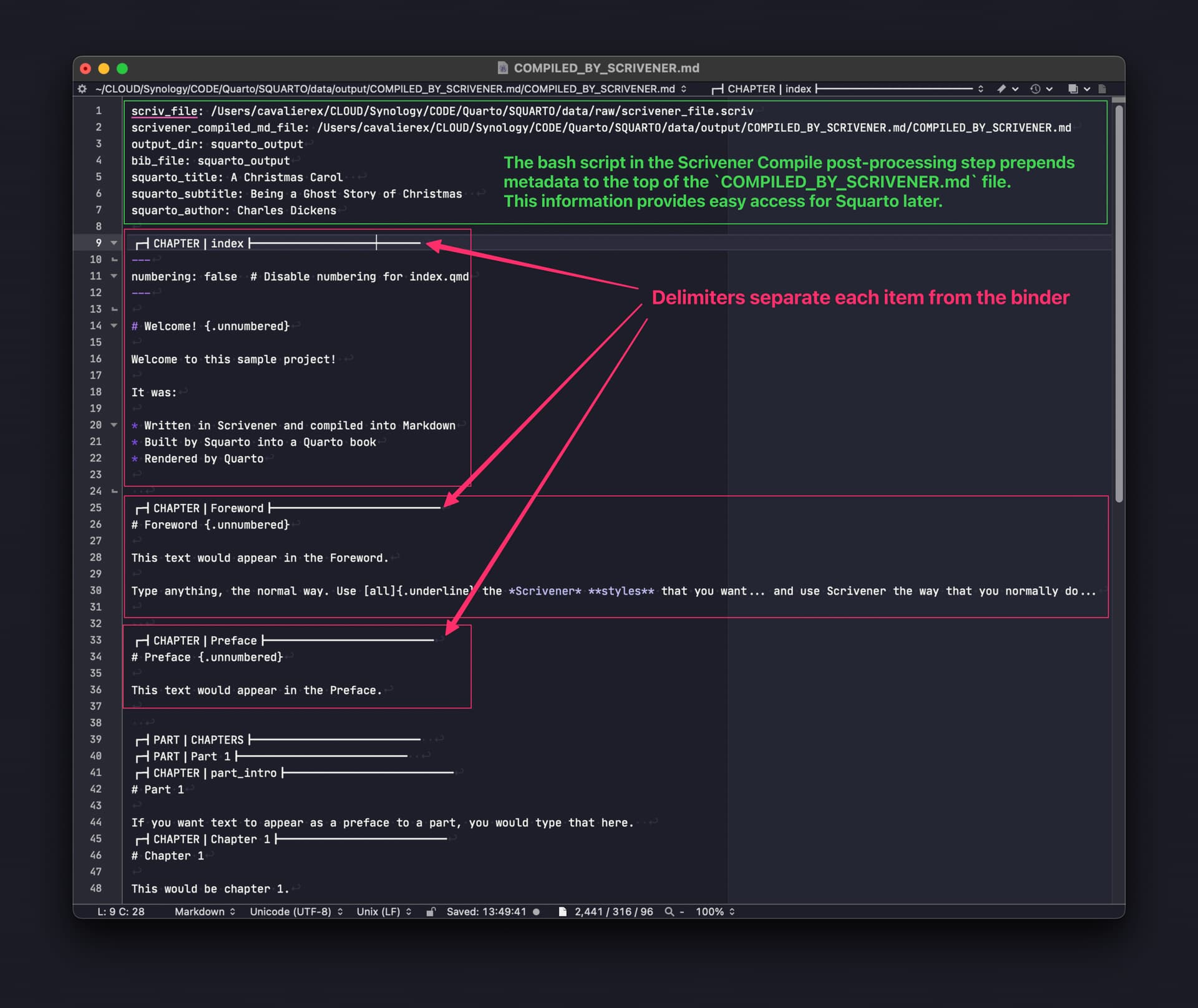
Presently, Squarto is capable of doing the compilation independently. It does this by introspecting the .scriv package, which is itself a standardized hierarchy of folders and files. Thankfully, KB and the Scrivener designers based everything on plain text, so things were straightforward once I got used to it. The main .scrivx file is an XML document that specifies the ordering of the items in the Binder (among a few other things). Each binder item has a unique identifier (UUID) that is used to locate the data files related to what you type in the Editor. This includes the writing itself (content.rtf) but also information about Styles, Notes, Synopsis, etc.
📁/squarto_project_title/
│
└── 📁/scrivener/
│
└── 📁/my_project_title.scriv/
│
├── 📄my_project_title.scrivx
│
├── 📁/Files/
│ ├── 📁/Data/
│ │ └── 📁/<UUID>/
│ │ ├── 📄content.rtf
│ │ ├── 📄content.comments
│ │ ├── 📄content.styles
│ │ ├── 📄notes.rtf
│ │ ├── 📄synopsis.txt
│ │ └── ...
│ ├── 📄binder.autosave
│ ├── 📄binder.backup
│ └── 📄styles.xml
│
└── 📁/Settings/
│
├── 📁/Compile Formats/
│ └── 📄Squarto.scrformat
├── 📄compile.xml
├── 📄projectpreferences.xml
└── ...
Squarto basically performs a big ETL (extract-transform-load) process:
- Extract raw data from Scrivener
- Convert raw RTF to raw Markdown using an async Pandoc subprocess.
- Extract embedded images (storing files in
/Figures/) and substitute with Markdown link
- Transform Style information into standard Markdown
- Transform myriad other details into clean Quarto Markdown format
- Load everything into a temporary SQLite database
This process is done asynchronously, and it is satisfyingly very fast!
Being its own compiler allows Squarto to do cool things
Before, when I relied on a Scrivener > Scrivener Compiler > compiled.md > Squarto workflow, there were many friction points where I wished that I could “preprocess” something before Scrivener compiled it, then “postprocess” it in a certain way before handing off to Squarto. Somethings were possible with workarounds, but other things were not possible.
Now that Squarto does the compilation instead of Scrivener, it opens up the door to many cool features. For example, now Squarto can differentiate between Scrivener Styles and regular RTF styles. That allows me to use regular command-B (bold), command-I (italic), command-U (underline), superscript, subscript, strikeout, etc. while I am writing, and it will be converted correctly to Markdown. I no longer need to create an alternative Scrivener style like strong or emphasis and then key-bind it to command-B and command-I. I only use Scrivener styles for the markup features like heading levels, marginalia, raw Markdown or LaTeX, citations/crossrefs, etc.
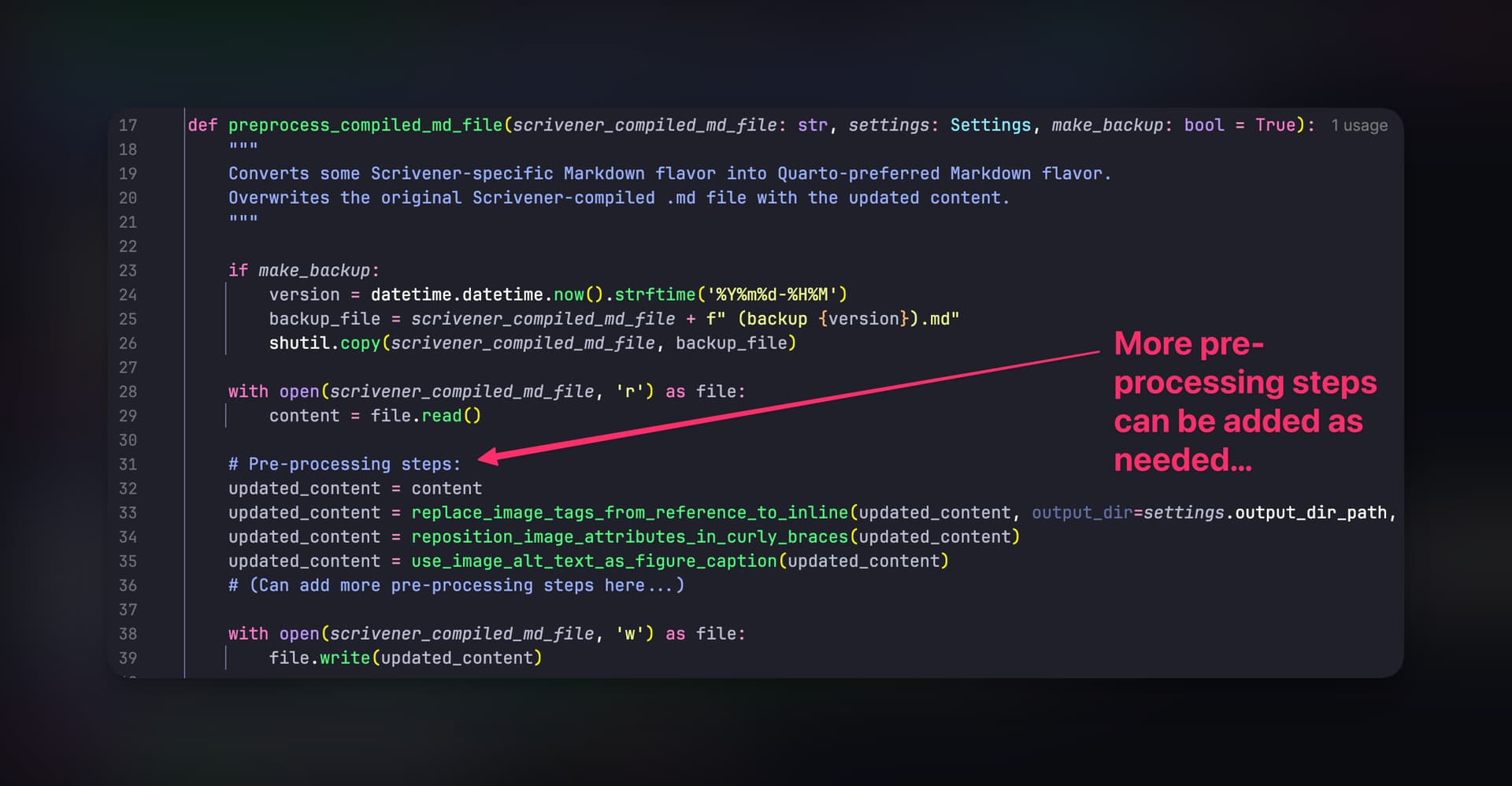
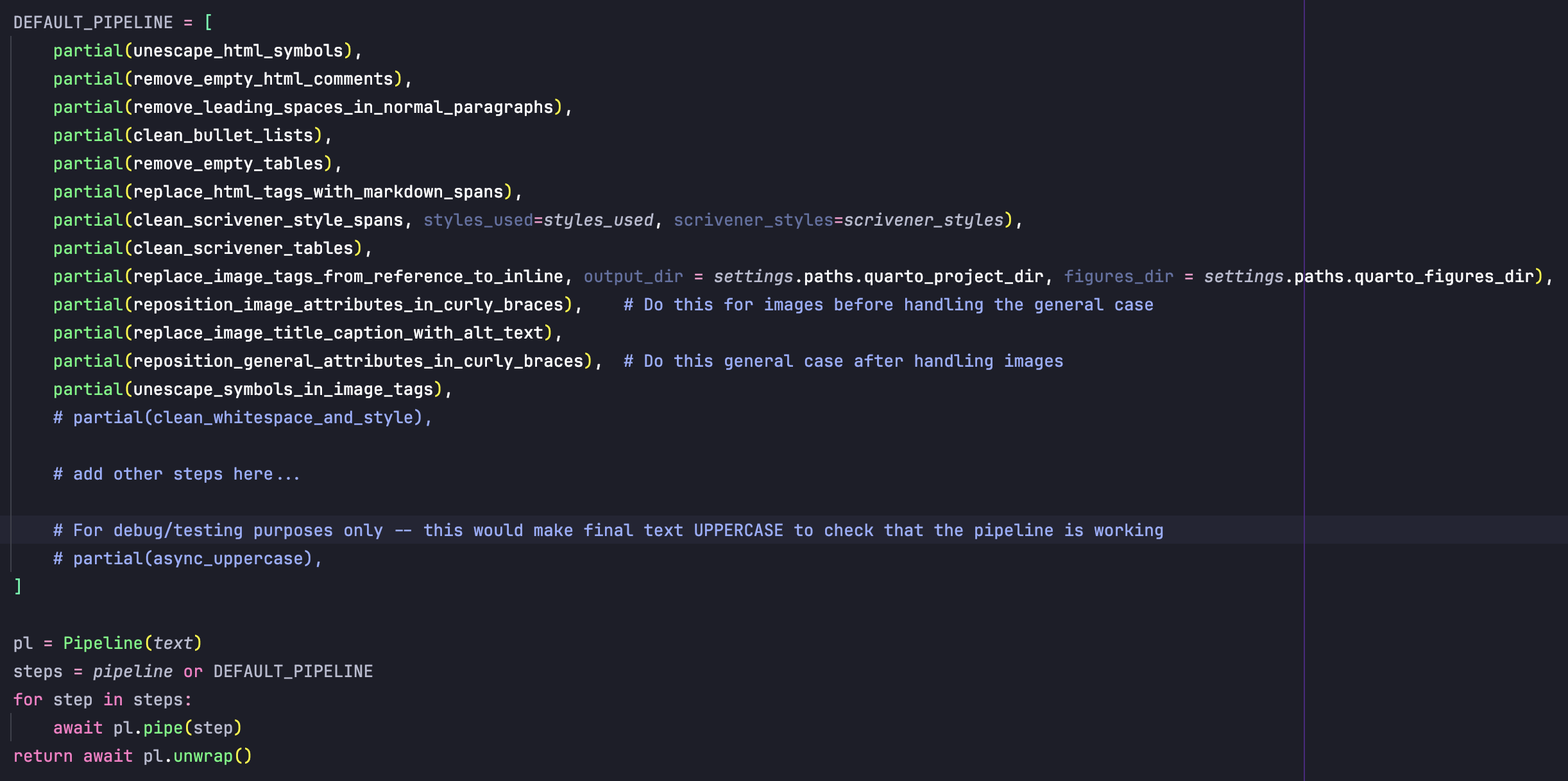
Another thing that being its own compiler enables is specifying the order of processing steps in a pipeline. For example, my default pipeline unescapes symbols, removes comments, optimizes bullets and tables and figure Markdown, etc. Specific pipelines could be specified per file (per item in the Binder), although I have found the default pipeline to work for most everything. The one exception is something marked ‘data’ or ‘raw’, in which case minimal processing occurs.
Squarto’s main output is the Quarto project
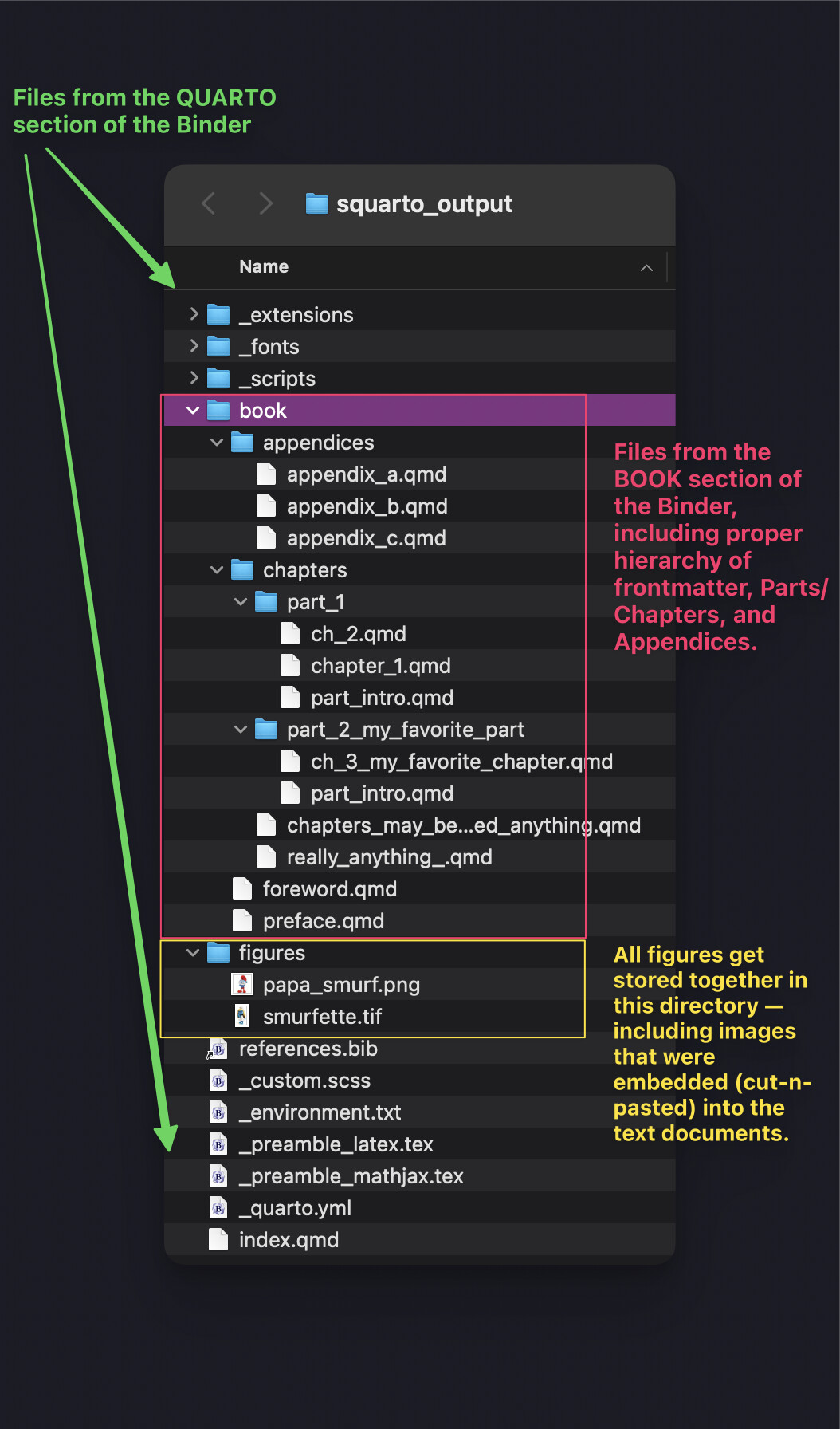
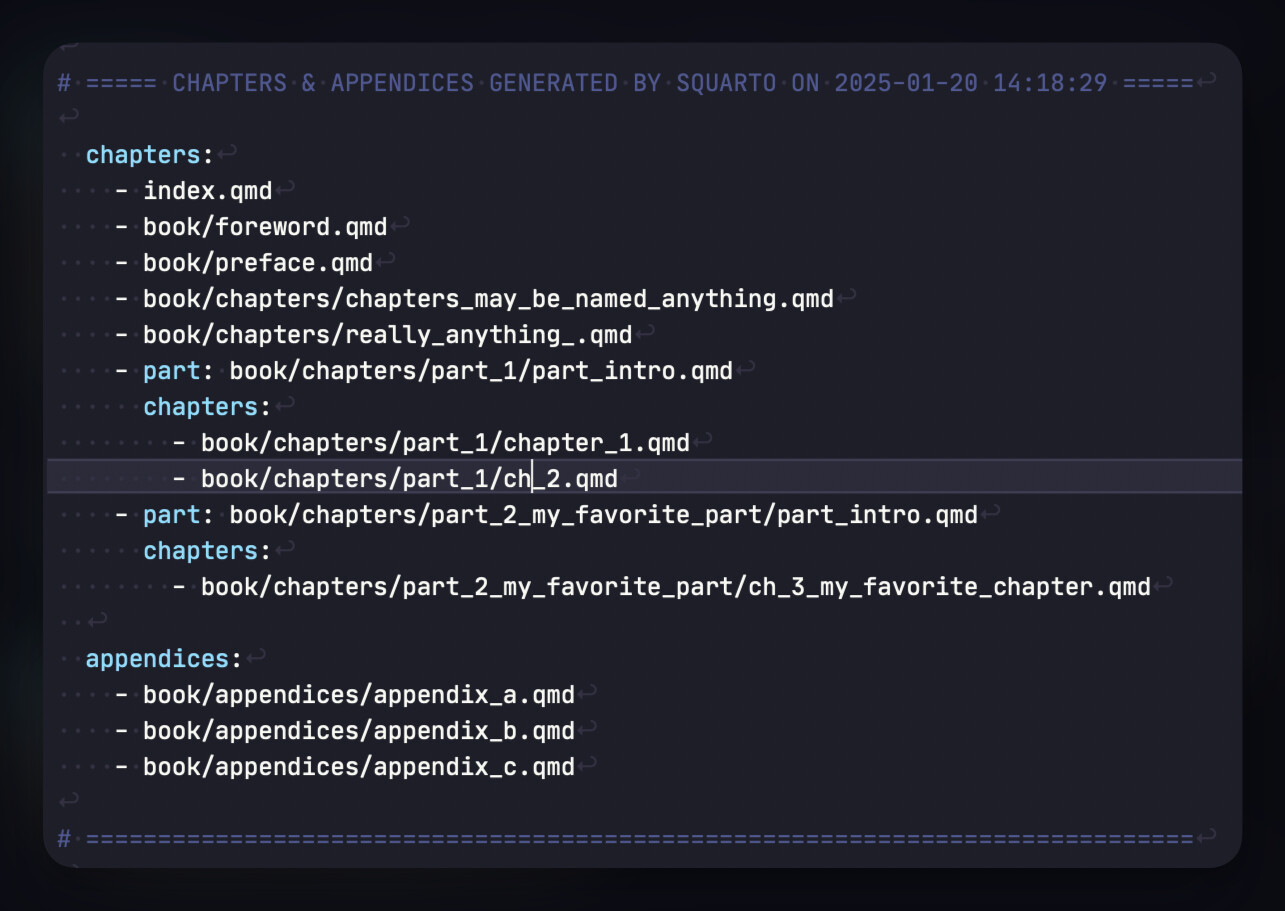
From the converted data, Squarto then creates the canonical structure of the Quarto project. A Quarto Book project might look like this:
📁/squarto_project_title/
│
└── 📁/quarto_project/
│
├── 📄_quarto.yml
│
├── 📄index.qmd
│
├── 📁/draft/
│ ├── 📁/frontmatter/
│ │ ├── foreword.qmd
│ │ └── preface.qmd
│ ├── 📁/chapters/
│ │ ├── chapter_1.qmd
│ │ ├── chapter_2.qmd
│ │ └── chapter_3.qmd
│ ├── 📁/backmatter/
│ │ ├── glossary.qmd
│ │ └── references.qmd
│ ├── 📁/appendices/
│ └── ...
│
├── 📁/figures/
├── 📁/tables/
├── 📁/data/
├── 📁/code/
│
├── 📄references.bib
│
├── 📁/.venv/
├── 📁/_extensions/
└── 📁/_fonts/
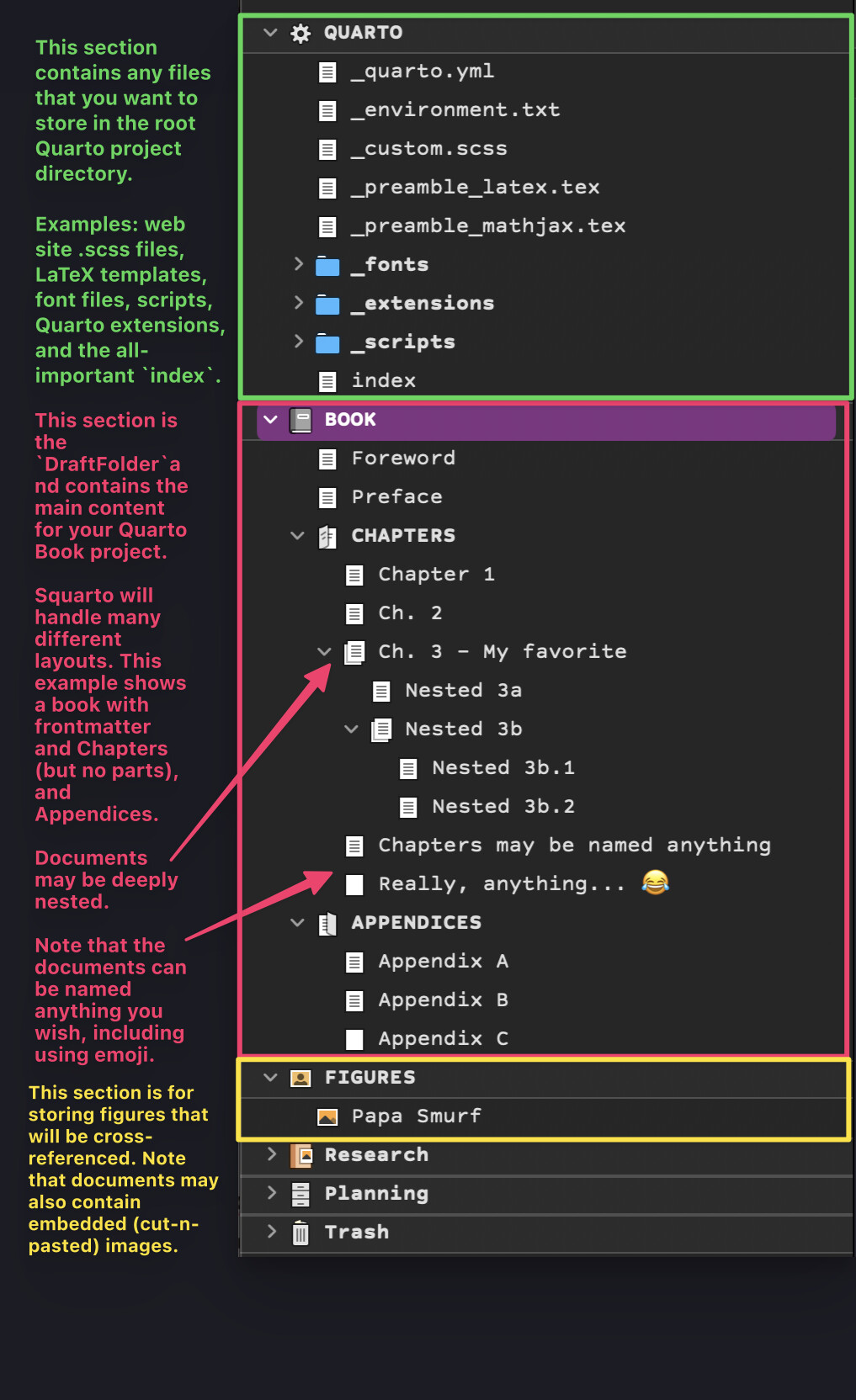
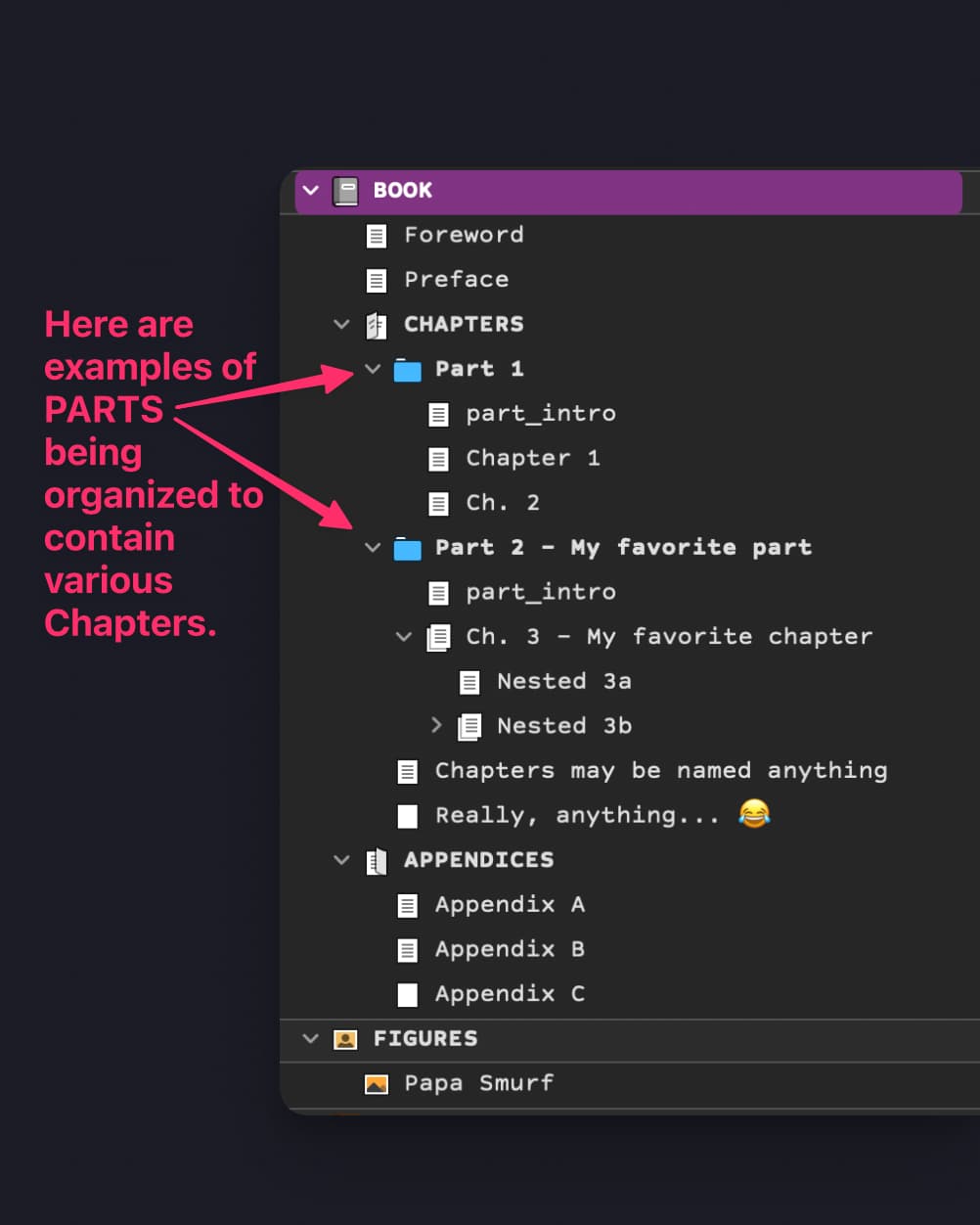
The structure of the Quarto Book is a direct translation of the structure of folders and documents contained in the Scrivener Binder. (From the ‘Draft’, folders become Parts, documents become Chapters, and nested subdocuments are aggregated into the parent Chapter. ‘Frontmatter,’ ‘Backmatter,’ ‘Appendices,’ ‘Figures,’ ‘Tables,’ etc., are other root-level folders parallel to ‘Draft’.)
The content of the _quarto.yml file is automatically updated with the appropriate metadata, such as paths to the various .qmd files.
All embedded images are extracted into /figures/ automatically. In addition, the Scrivener template has Binder folders named ‘Figures’, ‘Tables’, ‘Data’, and ‘Code’ where the user could choose to store files directly, and anything in those Binder folders would be extracted into the respective folders in the Quarto project directory.
Once the Quarto Project is created, it is processed as usual
Once the folder/file hierarchy for the Quarto project is created, it is simple to run quarto render on that project to create any output you want; e.g, quarto render --to=pdf' will produce a PDF document.
If the autorun_quarto_render = true flag is set in Squarto’s settings (TOML file), then squarto build will hand off to quarto render automatically.
Quarto products are moved to a dedicated directory
One annoying thing about Quarto is that it wants to do everything inside the same Quarto project directory – mixing temporary files and output files right there alongside your source (input .qmd) files. It makes for a big mess. Quarto allows you to rename some things, but not to move things outside of the main Quarto project directory.
Therefore, Squarto looks for the Quarto output products and moves everything to a nice clean directory:
📁/squarto_project_title/
│
├── 📁/quarto_project/
│
├── 📁/products/
│ ├── 📁/docx/
│ ├── 📁/md/
│ ├── 📁/html/
│ └── 📁/pdf/
│ └── 📄my_project_title.pdf
The Quarto project can be versioned using git
Since the canonical Quarto project is just a hierarchy of folders/files, it can be versioned via git commit. This allows tracking changes (via file diff), undoing changes, etc.
What I’m working on now…
Now that I have this pipeline working nicely, it would be really cool to improve the preset functionality so that I can use LaTeX or Typst classes/partials. I might also like to generalize beyond Quarto so that I could use a Pandoc-only workflow when I don’t need to have code be executed. There are certain limitations in the existing Quarto ecosystem that I may be able to work around – for example, using Typst (and its nice templates) in a Quarto Book project is not presently feasible.
Well, that’s enough of an update for now. I look forward to hearing your thoughts or suggestions for features to improve/add.