I’m following the instructions given in a different posting about how to create an alphabetical index after compiling a test text into an OpenOffice document.
It seems to be working for the most part: All of the words I mark in the Scrivener text show up in the alphabetical index, both the “Index Keys” and the “Index Terms”. However some of the marked index keys have extra text inserted: “}}” or “strip{{”. When playing around with the system yesterday I believe I was able to get rid of these unwanted additions, but I don’t remember how I did that.
Has anybody here seen this behavior or know how to remedy the problem?
Do you have an example of the source text that causes the strip text to appear with brackets? It could be I need to make the regular expression replacement, that is working with that, a little more robust. A little one-paragraph demo project that demonstrates it should suffice. You can attached zipped projects to a respons; DM me if you can’t get it to work with generic text and don’t want to post it public.
To explain what is going on here, the style you are using to mark text is in fact inserting that around the text you mark. There is then a regular expression that looks for stuff like strip{{purus}} or strip{{ purus}} or strip{{purus }} and removes the whitespace. Reason being, one might be inclined to include a space within the style so it doesn’t bump up directly adjacent to a nearby word and mess up the spell checker, but for the purposes of generating syntax, we wouldn’t want something like <element attribute=" purus"/> in the XML.
P.S. I’ve fixed the link in your post. That happens to me sometimes as well, if I’m not paying attention. The forum will attempt to be helpful and paste a fully formed Markdown link depending on your clipboard—without regard for whether you’ve already typed in part of the link markup yourself. You can avoid this by pasting with ⇧⌘V / Shift+Ctrl+V, which forces raw plain-text pasting (though that might be a Chromium-base thing rather than the site itself).
P.P.S. I’ve moved this to Mac bug reporting for now. The problem and solution may in fact be applicable to both Mac and Windows though, so I might move it to general Scrivener discussion if that proves to be the case.
Thanks for the explanation. I’m attaching a zip file of the Scrivener file along with the ODT file I get from it.
I also noticed in the ODT file that there’s a visible artifact in front of the word that follows the words in the Scrivener file that I’ve marked as “Index Key”. Is that maybe also somehow a by-product of the regex replacement?
Ah! Simple mistake on my part. The problem is that I used the “greedy” form of capturing the string between the strip markers, meaning if there is more than one invisible indexing key on a line, it starts capturing from the first key, and then proceeds to scan back from the end of the line until it encounters the last key, thus considering everything between the two keys as part of the replacement. It doesn’t break the syntax, but it does mean any fragments for }} or strip{{ found within the paragraph get left in.
What it should do instead is continue scanning forward from the initial match point, until locating the conclusion of the strip marker that started it.
So to fix this in your project:
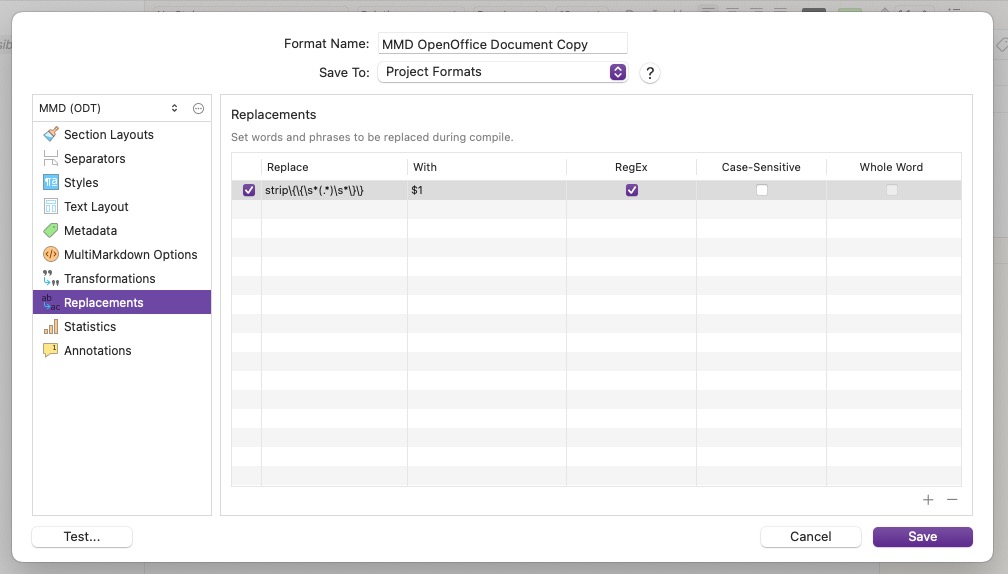
Open the compiler, and double-click on the “MMD OpenOffice Document” format to edit it, duplicating when asked.
Click on the Replacements pane. You’ll see one replacement in here, delete it, and then copy and paste the following text into the Replacements table:
I’ll get this corrected for the official builds as well.
I also noticed in the ODT file that there’s a visible artifact in front of the word that follows the words in the Scrivener file that I’ve marked as “Index Key”. Is that maybe also somehow a by-product of the regex replacement?
That is an editing mark for your benefit, so you can know that a “zero width” formatting code of some kind exists there. If you right-click on it, you’ll get an option to edit the index entry, in the contextual menu.
OK, I answered my own question. CDATA is an XML thing, so that doesn’t get copied. The new “Replace” field is supposed to contain the text within “CDATA[…]” including all the backslashes, and the “With” field remains unchanged as:
$1
And the compile procedure produces the desired text without the inserts.
Oh yes you could do it that way too, and copy and paste just parts out. But that full XML can be pasted directly into the table (not the fields) to insert any number of fully configured rows. So it is a way of sharing settings by copying and pasting between projects directly, or indirectly like here.