As a hyper-avid fan of Scrivener Styles, I have come to understand the need to document openly the code that is currently residing in my LaTeX (Memoir Book) > Styles Project Format.
Scrivener provides a powerful, structured format to enter the many options that Scrivener so carefully provides that facilitate the writing experience. With well over a hundred custom Styles that I have created to expand on the utility of using Scrivener+LaTeX, I am finding it cumbersome to create a summary of the code I’ve entered for those Styles.
My initial idea to create an open document to store Style codes and data has now expanded to eventually include ALL Project Format user-input data (as near-impossible as that might seem to me right now).

My first objective was to select a system, database or spreadsheet to store the user-defined data. Strangely enough (or perhaps not) I realized that a Scrivener project could provide the structure and flexibility that I’d need to hold the user-defined data, with an exceptional ability to process and output that data in whatever format I will need.
That brings me to my question (sorry that took so long).
With the help of the Forklift and Oxygen XML apps, I have been able to locate the Scrivener .scrivx file, and eventually open styles.xml that appears to contain most, if not all, of the used-defined Styles data in my project.
For reference, I have essentially zero knowledge or experience with XML.
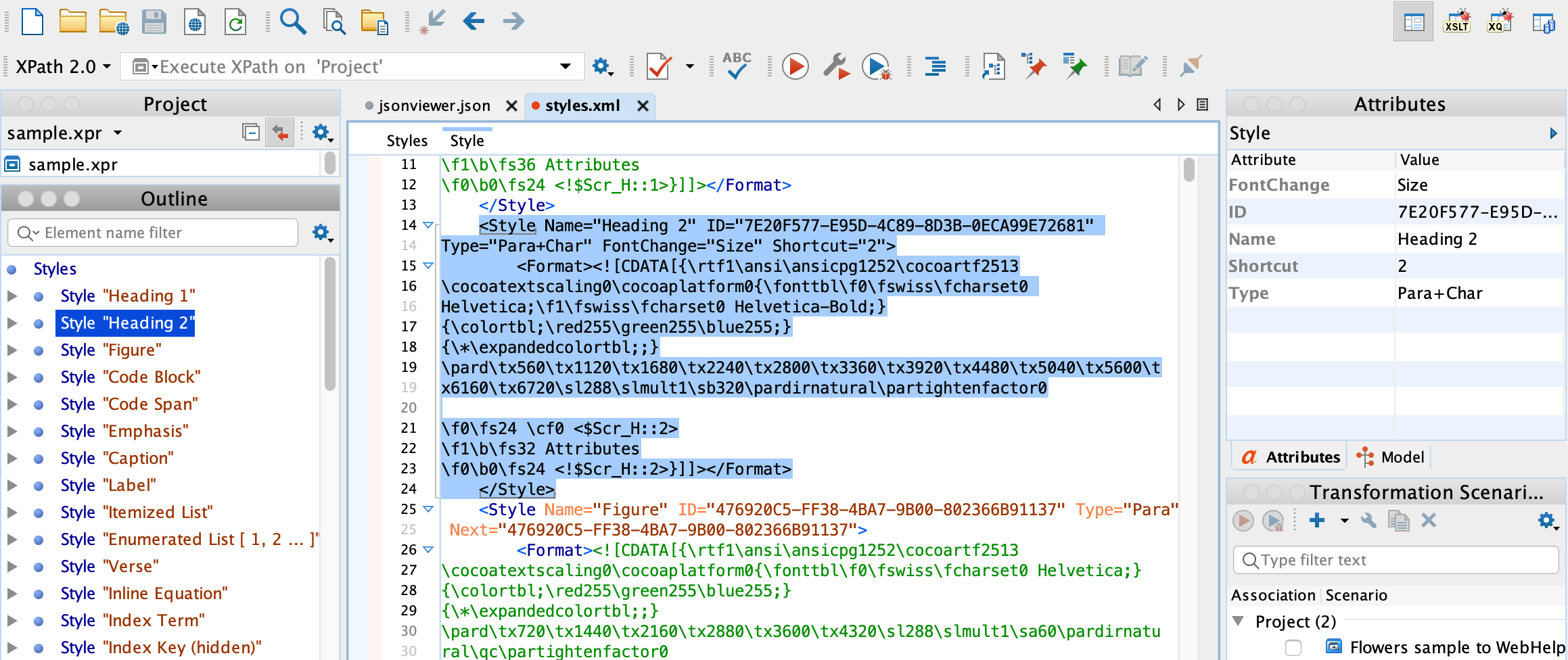
I’ve been able to peek into the styles.xml file using the Oxygen app. I identified the entries I created in my own project’s Styles, along with the Styles that were included in the original General Non-Fiction (LaTeX) template. With zero XML knowledge, however, that is as far as I can go at the moment.
From this point, if anyone has any suggestion as to how I might extract the Styles user-defined data for eventual output as text, I would greatly appreciate it.
I realize that I will need some sort of an XML definition that lays out how the data is structured, which I do not currently have. It would appear, however, that at least part of that structure is defined on the right-side of the above screen as Attributes.
Any tidbits of insight to move me along to the next step would be welcome.
scrive




