Thank you both @xiamenese and @narrsd for your hints.
But both of you miss my point re language: compiling my whole draft (written totally in German) to ODT gives me a document with the language code “English (USA)”, while compiling to RTF there seems to be no language code at all, therefore the whole document adapts to my local installation in LibreOffice. Which BTW is “German (Switzerland)”.
This happens, because there is no “Language Chooser” in the project settings. In Scrivener, one can only choose the language of the installation, but not of an individual project. Which makes Scrivener not really international.
1 Like
Late here, so not trying anything, but if you are fully correct here, this seems an excellent point, and one that might be able to be easily addressed in an update.
…might… ![]()
And thanks for letting me think of Basel, once a very valued home…
1 Like
I can only say—as a Mac user—that my perception is that the problem is not that RTF cannot be marked for language, but that the Apple TextKit, on which both Scrivener and NWP are built, doesn’t include the necessary code for assigning languages to text.
Nisus, the developers of NWP (Nisus Writer Pro) have modified the TextKit enormously. I’ve been using Nisus Writer through all its versions ever since it was launched, somewhere around 2002/3, and I don’t remember at what point in the development language marking was introduced. However, Nisus have a team dedicated to modifying the basic TextKit, because they are developing a somewhat traditional word processor.
Things are different for KB. What he has developed is not a traditional word processor, but must have millions of lines of code creating everything that Scrivener does that traditional word processors don’t—which is why we love it—so providing language marking, integrating it with both the editor and the compiler including all its ramifications seems to me to be no easy task for him.
And so I imagine the same scenario exists for the Qt text engine and LAP and Tiho_D. I would think there are other things much higher on their priority list than language marking.
But Scrivener 4? Who knows! ![]()
To respond more directly to @grac, for me using NWP, marking a whole document as being in a particular language, would be Cmd-A (Find All) followed by two mouse clicks on an interface element or keyboard shortcut*; or probably a four-line macro with a shortcut set. A more complex macro could provide one with a list of languages to choose from, but it would be beyond my capabilities.
LibreOffice?
![]()
Mark
- P.S. One of the other terrific developments in NWP is their own shortcut engine giving the ability to use multi-symbol shortcuts: German, for instance could be Cmd-GE, English Cmd-EN and so on.
2 Likes
While I strongly disagree with both the opinion on Scrivener’s styles and the tone expressed in parts of this thread I do second the request for language settings in Compile.
Most software (at least from the Western part of the world) handling text that holds no language information assumes that the language is (US) English. Which means every Scrivener user who does not write in English has to take extra steps after Compile.
And that does not only apply to those who compile for word processors but for all formats that need language information like HTML, e-books, and LaTeX. For example, I find it highly impressive how good the output with Scrivener’s out of the box LaTeX templates is. So even someone with little to no knowledge of this very technical typesetting system can get high quality results. As long as they don’t write in any other language than English because then the wrong hyphenation ruins it all.
At best there was a general language setting for the whole draft and a language setting for paragraph styles which allows block quote in others than the main document language.
2 Likes
I too agree that it would be good to have language marking—even UK English!—but as I said, I think it to be no easy matter for the team. But when you say:
I would point you to @nontroppo’s post above, where he says:
Although, in that instance he’s talking about markdown → ODT, compiling to HTML, ePub and LaTeX all go through markdown so I think his suggestion would equally apply to those. If you used Pandoc/Quarto, I presume it would carry through to DOCX .
But for compiling to RTF and DOCX, yes, you need to open the compiled document in your editor of choice and add the necessary marking there. As I said, for me it would hardly be onerous, especially as I always compile to RTF automatically opened in NWP anyway. I immediately run a macro converting the styles to NWPs cascading styles (including assigning UK English), language marking any Chinese, re-formatting footnotes the way I want, and running spell-check. If what I want is a PDF, for example, I print to PDF from NWP.
![]()
Mark
Oh, Mark, do you not realise that my züper-düper pandoc-power can semantically label elements down to single electrons flowing in your CPU? Well, um, OK, not electrons, but as we make use of Scrivener’s styles then character (aka inline) styles can “tag” at least down to the single letter!
Now back to the task at hand. Here is an example ODT output and project where both the TOC and 2-level lists are well-formed. I used Scrivener’s editor styles as I usually do, then Pandoc>ODT at the backend (see the post-processing pane for the details):

ODT and template (Pandoc can use a template so your styles are all preset):
TOCTest-Pandoc.zip (29.3 KB)
Scrivener Project (includes compile formats for MMD>ODT and direct ODT/DOCX/PDF):
TOCTest.scriv.zip (81.2 KB)
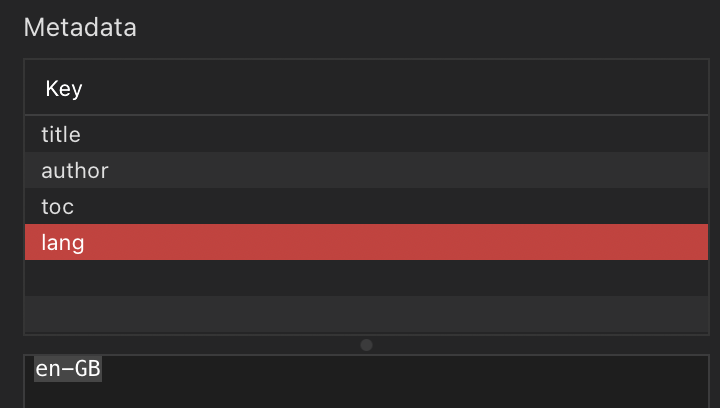
The TOC uses Pandoc’s ability to activate the native TOC system in LibreOffice/Word, it doesn’t use Scrivener’s workaround. The list is correctly formatted, and all styles from Scrivener are present in an otherwise clean ODT. I also added a lang=en-GB to the Scrivener metadata, and in LibreOffice UK English is set as expected (not US)…
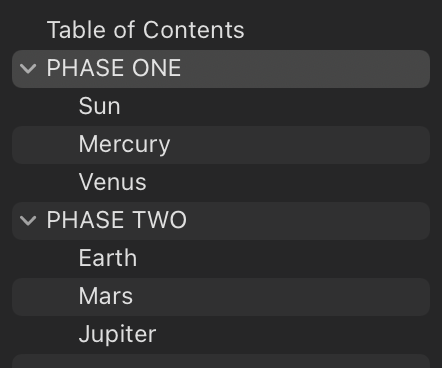
I also tried to compile the same project directly to ODT and hit a crashing bug (reported), so tried DOCX. This is using Scrivener’s TOC workaround:

The tabs don’t quite line up. I removed as much styling apart from the indents for heading 1 and 2 items. The two-level list seems OK. Note that the headings are all properly labelled with heading levels so it would be easy to replace the scrivener TOC with a Word TOC:
The styles mostly seem to apply across. Personally I much prefer the output via the markdown intermediary, where full control is enforced and much more flexibility in terms of styling is available (thanks to being able to pass a template.odt on which the compiled result is based)…
2 Likes
Actually, I do; basically, you’d do the same as me, but put the appropriate lang prefix and suffix codes in the compiler, whereas since I go the RTF route, I do that as part of a macro I invoke by a shortcut in NWP. In point of fact, since my alternate language is Chinese, my Scrivener character style in Chinese is there purely because I don’t like the default font; the macro searches for anything in the UTF-8 charsets for Chinese and language marks the found text and sets the font. The macro starts by asking which style collection I want to be applied; it then takes a couple of seconds to run on a 100 page document, resetting styles, footnotes, language marking and other tasks. I could get it to invoke Bookends and run the scan and create the bibliography if I wanted to, but I need that so little these days that I don’t bother.
In a sense it seems to me that, as my workflow has evolved, I’m doing something not that dissimilar to you, where I am essentially using Scrivener styles as a kind of mark-up… I always compile using the same standard .scrformat. The fundamental difference is that I apply the required formatting post-compile through the macro where you do it as part of the compile process.
About a year ago I did flirt with trying your Scrivener-scrivomatic-Pandoc route, and am still interested, and Quarto sounds v. interesting, though that is from an innate level of geekery. But I realised that (a) at my advanced age, I have too many priorities to be able to give the time and energy to it, and (b) that I have so much already invested in my Scrivener-NWP workflow, which works well for me, that it would be stupid to abandon it.
![]()
Mark
P.S. My original post was referring to your suggestion of using a meta-tag, rather than a character style; I presume meta-tags can only be added to documents.
2 Likes
Yes, exactly right. The magic power is the Scrivener semantic buckets (aka paragraph and character styles). I think using macros is really great, and it seems NWP is a wonderful tool! I’d definitely stick with it considering how well it works for you.
Yes, that is correct, the meta-data applies to the whole document. You can still use block and inline styles > markup to target down to the character level. To be honest your idea of using unicode is even easier, for any language that you can do that for auto-tagging would be completely hands-off… In Pandoc you could write a filter to do that for you, equivalent to your macro…
I am always surprised that so many Mac Scrivener users seem to prefer Word or LibreOffice over NWP as their word processor. I think KB uses it and I know of one other because through the Nisus forum, I provided him with my macro minus the Chinese and a couple of other personal elements… it is working well for him too.
If you’re not following the Markdown > Pandoc, route, one of the other great advantages of NWP is that its native format is RTF, based on the same TextKit as Scrivener, so when you compile there’s no format conversion going on. You can then export to DOCX if you want, using the same Aspose converters that LibreOffice uses to convert RTF, though I leave it to my recipients to just open the RTF in Word as that makes the most reliable conversion.
![]()
Mark
Nisus Writer Pro
1 Like
The tricks our minds play on us.
![]()
![]()
![]()
1 Like