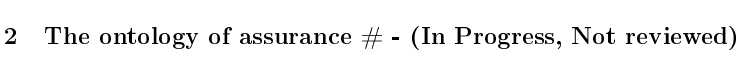I’m a novice using Markdown, Pandoc and Latex, however, Latex is the preferred template for scientific papers at conferences. (MS Word is used in addition by some, but these templates are in general just bad)
As I want to use Rich Text in Scrivener, I compile to MMD and then use Pandoc from MMD to Latex (TeXstudio for Latex). I use Zotero with the add-on “Better BibTex” for citations and bibliography.
First, a general tip is needed:
I use character styles to tag words so that I can add commands when compiling. One example is citations:
This is what it looks like in Scrivener (Character style - “Cite”):
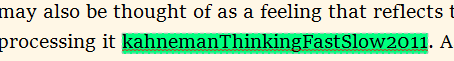
![]()
Defined like this:

And it turns out like this is Latex (after first compiling to MMD and then using Pandoc to Latex):

Question: Would it, in general, be better to use Pandoc’s Markdown instead of Latex commands directly?
Two concrete reason for my question (help needed):
- Concerning citations - I got into problems when adding a page number to the citation. How to get the page number through to correct Latex code?
- Reference to another section. How to? Tried same strategy as with citations:

However, Latex uses a label as the reference mechanism. This label is automatically added by Pandac and my strategy of just adding \ref{} is too simplistic. Would it be better to: 1) add a label to the headings in Scrivener, 2) marks this using Pandoc’s Markdown. Then, hopefully, Pandoc is capable of getting this correctly into Latex code.
I tried this by manually editing the MMD file:
I added the label at the end of the heading text using Pandoc’s Markup.
That seems to work (Latex):
Also manually adding a reference to this heading in MMD:
Works just fine in Latex:
How to achieve this in Scrivener?
-
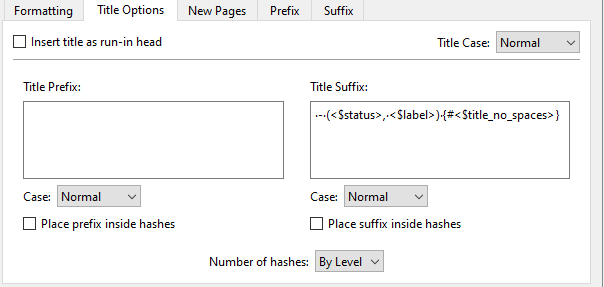
Add a label to each heading (I’m using the document name in the binder as the heading name):
(Temporarily, I also add Label and Status at the end of each heading at compile time - this is of course not the same “label” I would like to add to each heading )

-
refer to this heading in the text using character style and add a command (Latex, MMD, or Pandoc’s Markup) at compile time.
Returning to citations; I use a paragraph style in image captions. However, when adding a citation within this caption, Pandoc does recognize it as an image caption and messes up the Latex code. The only workaround I’ve found is to use Latex code directly in Scrivener. However, I would like to avoid such code within the manuscript in Scrivener.