I’ve been trying to figure out the MMD->LaTeX workflow, and am running into this problem.
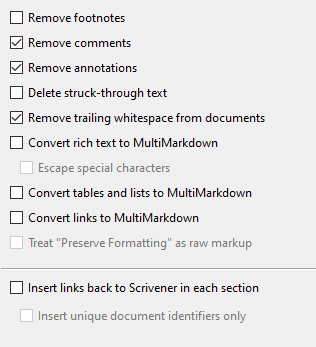
When “Convert rich text to MultiMarkdown” is turned on, various types of MMD no longer work.
E.g., with “Convert rich text to MultiMarkdown” off,
# My big topic 2 #
converts as expected to
\section{My big topic 2 }
but with “Convert rich text to MultiMarkdown” on, we instead get:
\# My big topic 2 \#
Similarly, MMD citations work fine without the rich text conversion, but break with it turned on. LaTeX math works fine without rich text conversion, but breaks when it’s turned on.
Am I missing something dumb? I like the idea of formatting my document using rich text and letting Scrivener translate it into MMD. But obviously it’s still necessary to sprinkle in real MMD here and there. Any ideas how I fix this?
If you have a look at the documentation, §21.5, Markdown and Scrivener, the approach you are describing is best encapsulated by the “Incidental” technique, on page 524. With that approach one isn’t really technically using Markdown to write, and is asking the compiler to convert rich text to it internally with that setting.
If you choose to work that way then you will need to mark what text you use that is intended to be markup, with Scrivener’s styles feature or Preserve Formatting (in the Format menu). Although part of a longer conversation, this post provides some insight into how one might use the Styles system to generate markup, with the idea being that it would be in the context of a project otherwise converting RTF to Markdown.
Here is another post that could be generally useful (skip down to the “Using Embedded HTML” section). Again in terms of specifics, we’re talking about how to create an HTML file (from an RTF conversion as well) while having the ability to pass through raw HTML—but the idea is exactly the same only here we want to pass through raw Markdown. Scrivener uses the exact same set of tools for both workflows (which can be convenient if you’re using several of its compile file types from one project).
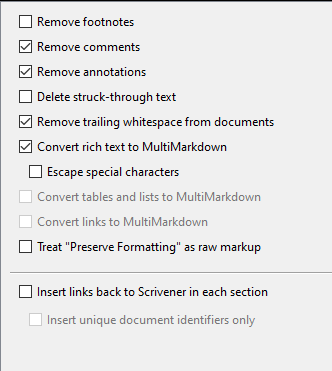
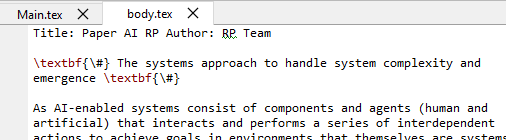
I have a similar problem. When enabling “Convert rich text to MultiMarkdown”, the heading converts to **# My heading #** in the md-file. Then, using Pandoc from .md to .tex, I get: \textbf{# My heading #}, which is not what I want.
However, I also have a bullet point list in the manuscript which converts correctly all the way to Latex (via Pandoc).
Turning off the “Convert rich text to MultiMarkdown”, the heading converts correctly all the way to Latex, but now the bullet point list converts to plain text in Latex (using begin {verbatim}).
How can I get both right at the same time?
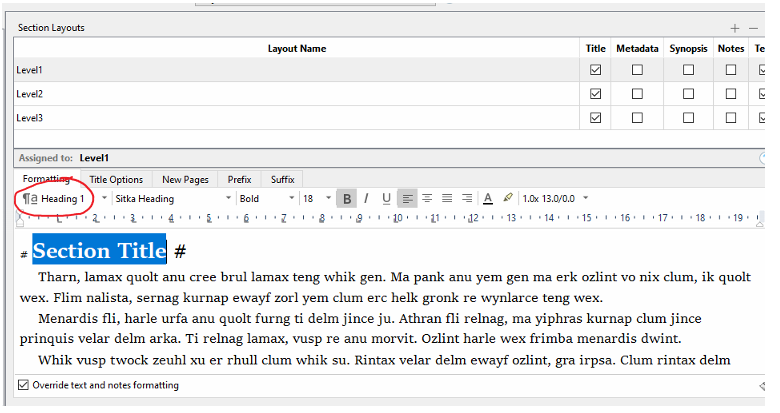
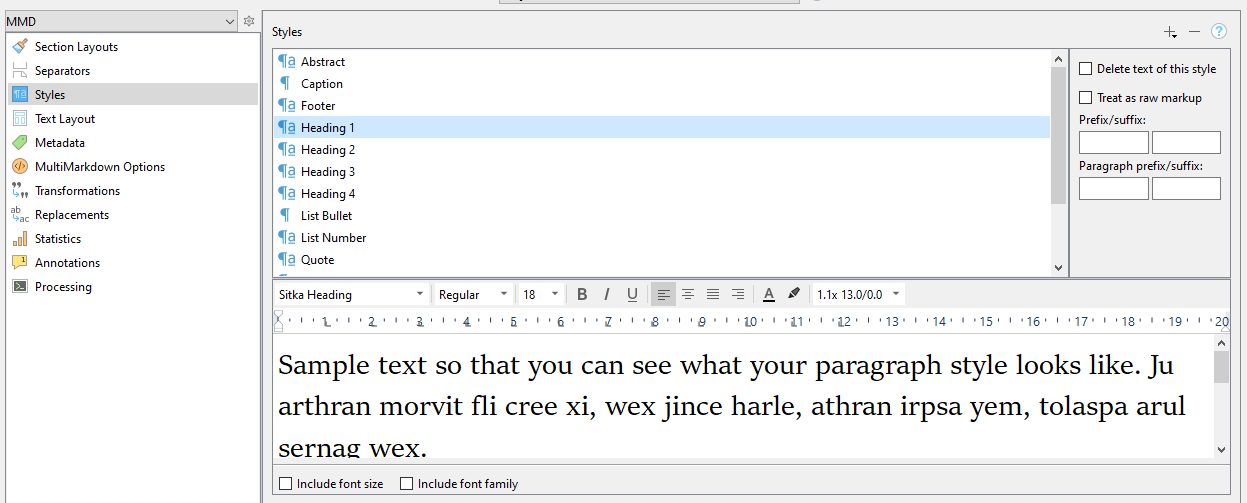
I use the document titles as headings using the (built-in?) Heading 1 style.
I’ve tried both No Style and a self-made style for the bullet point list. Same result.
PS! I’m an “Incidental” that only uses rich text in the editor, but need a way to get from Scrivener to Latex.
Hmm, could you give me a run-down of the compile settings you are using for this style? It definitely should not be interpreting formatting, like bold, if the style is set up properly using the raw markup setting that I described in my previous post. It would certainly make a mess if you used default settings though, because it isn’t designed to understand that you typed in hashes meaningfully, by default.
As an aside we don’t set this up for you out of the box, for two reasons:
There is a missing implementation that was meant to make it so using “Heading 1” (with no markup in it) would convert to # My heading text # with this RTF conversion option enabled. That doesn’t work though, leaving a gap in the implementation that requires manual labour to correct.
The “Scrivener way”, if you want to get a little more picky about it, discourages heavy use of headings in the text area anyway, and prefers to generate headings from the outline structure of the draft folder, using binder titles. The Section Layouts that the Markdown Formats use all come with options to generate such outline-conversion headings automatically.
So all around, setting up manually converted text headings into Markdown headings is a bit rough around the edges on Windows. One because it’s a somewhat niche way of working with Scrivener (more of a Word way of working, if you will) and secondly because of the missing easy to use method.
That’s something to consider anyway. You’re kind of doing things the hard way, which is perfectly fine if that’s your preference, but I wanted to make sure you knew there is a way with a lot more support in place that takes less work, if you want it.
Sorry for the clumsy description , the headings are generated from the outline structure in the Draft folder in the Binder.
This was what I meant when referring to style Heading 1:
Okay, well I think I might see what is happening, although I get a slightly different result if I try, I think we’re on the same page now.
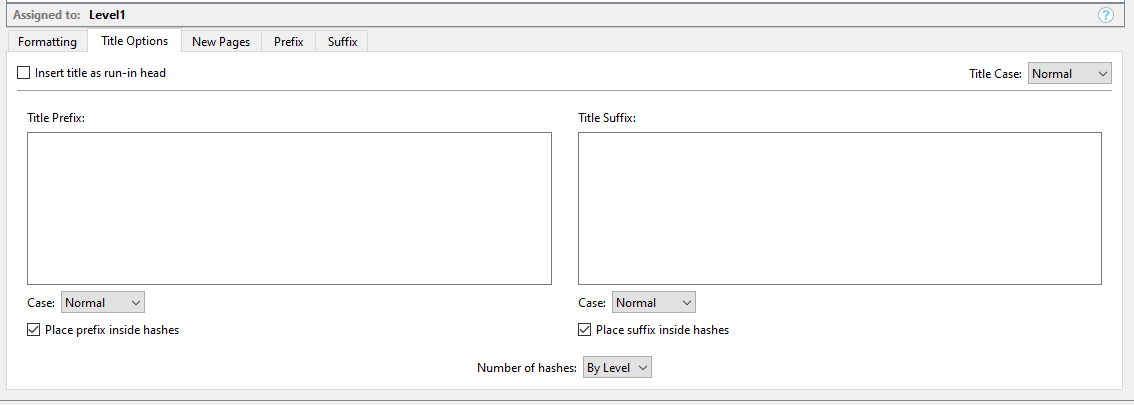
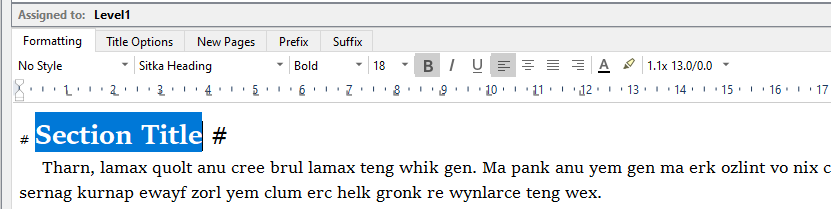
The main thing to consider here is whether you need any of these styles at all. In the Section Layouts pane, click on the Title Options tab, and look toward the bottom. You should see a setting that probably states, Number of hashes: “By Level”.
It is that which is generating your hashes, not the style. The style is completely unnecessary here, and is only getting in the way because it is applying bold to the text, which is being converted by the engine.
So that would be my advice, if that is how the setting reads, just try setting your titles to “No Style”. That’s all you need for Markdown. All it needs are the hashes to know what this text means, it doesn’t need a “Heading 1” style, and wouldn’t know what to do with it. The most we can do with that is inform Scrivener to turn that into raw hashes, but we don’t need to do that if the Section Layout is already doing it.
Let me know if that is still a bit off the mark, but if I’m right, you don’t even need these “level” based section layouts because indents in the binder become how many hashes it generates. Something beneath Draft gets “#”, something nested beneath it gets “##” and so on. We can make much simpler compile Formats with Markdown, than with rich text, because we aren’t having to spell out the levels with formatting and styles. We’re leaving that up to MultiMarkdown in this case, to turn “#” into \part or “##” into \chapter, and it is LaTeX that takes that and makes it look right.
Result:
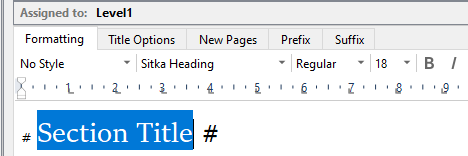
Tried removing bold from No Style (Only for Level 1) :
Result:
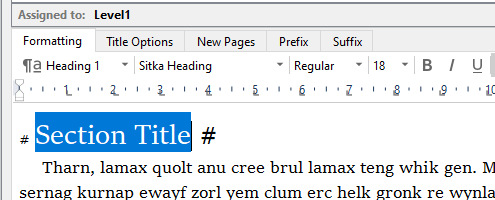
Tried Heading 1 without bold:
Result:
Result after Pandoc converted to Latex:
Result after compiling to PDF
All right, that’s a way of going about it I guess (and the very setting I was documenting at the top of this thread). I just hope that it is clear that at this point these styles have no purpose at all in your settings. They are 100% useless. They were undesirable before, which is why I advised deleting them in my previous post, but now with this checkbox enabled and them not being used to generate markup (which is why you’d use the checkbox), it’s entirely setting-bloat at this point. Bunches of things to keep track of, and to remember why you did this or that in two years, that do nothing.
If you are unsure and want to experiment, you can always right-click on the compile Format to duplicate and edit it. If it doesn’t work out or it turns out you really do need these for some purpose I am not seeing in your settings, then you can just remove the duplicate and go back to what you were doing.