which will extract the media files named as they are inside the source .docx file, which is a Zip archive at its core. The media file names are generated as well, so the names are different from the source names I used inside of Scrivener.
But this could work for me with the editorial process I will need to follow.
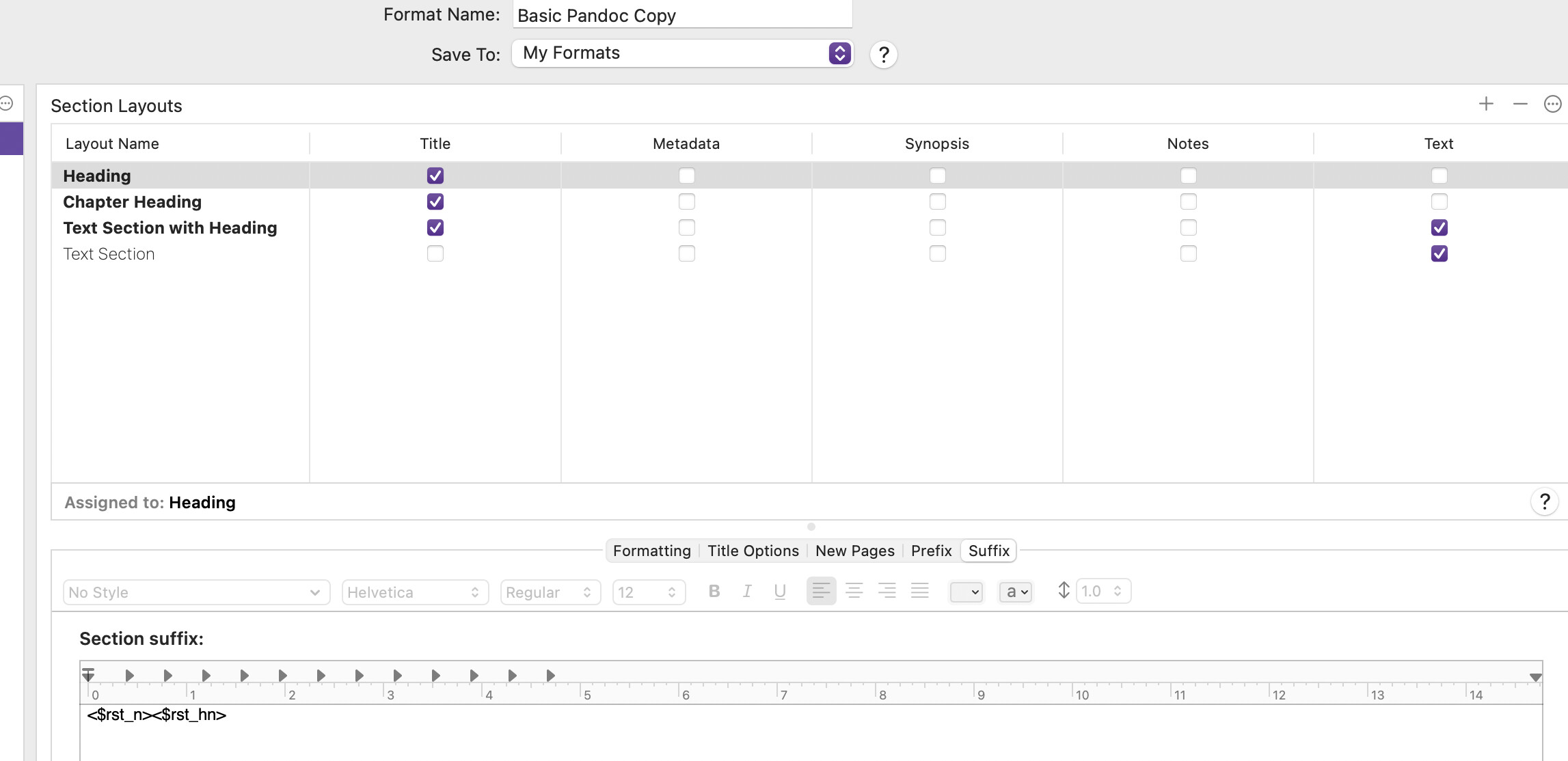
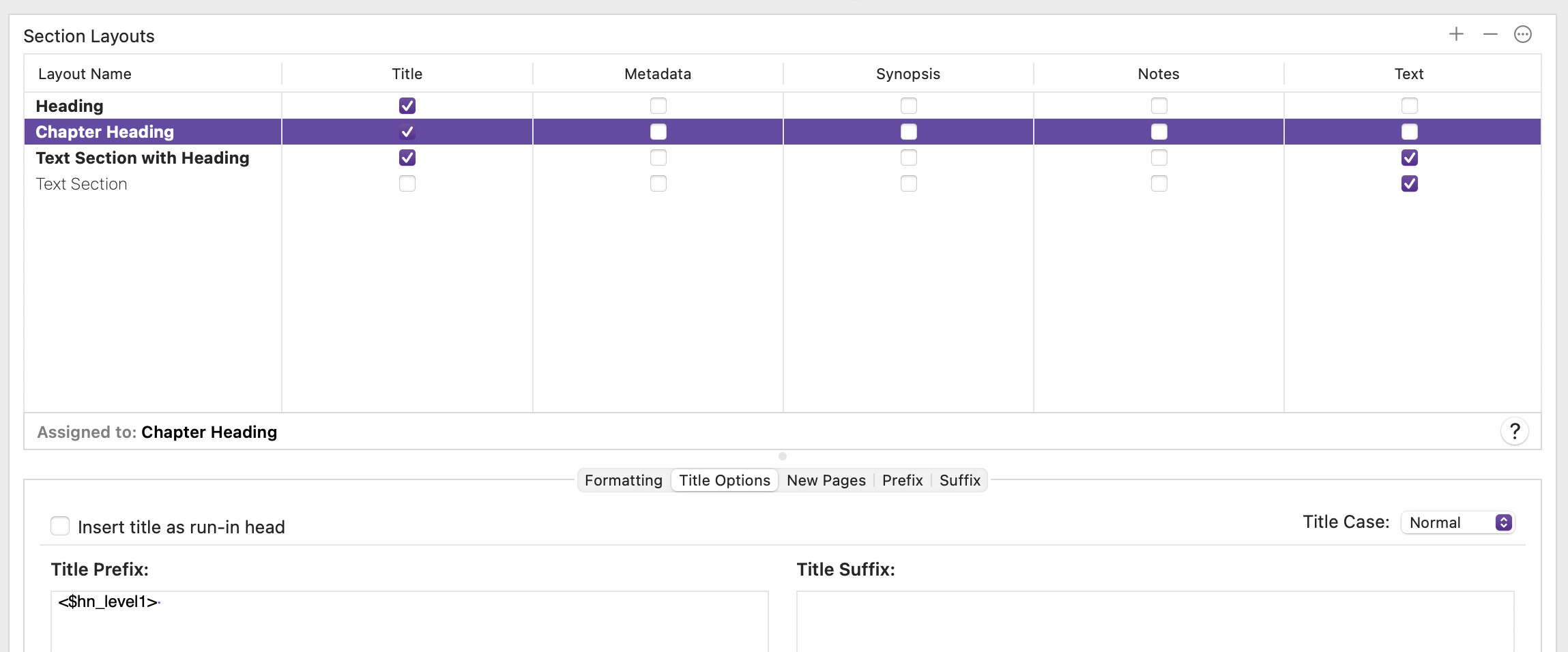
Thanks again for the reply. The Part Header type (Header) needs to be different from the Chapter Header where the Part is unnumbered. But when I start the compile sequence, the Header and Chapter Header are both connected to the same header style and I do not yet see how to change that connection.
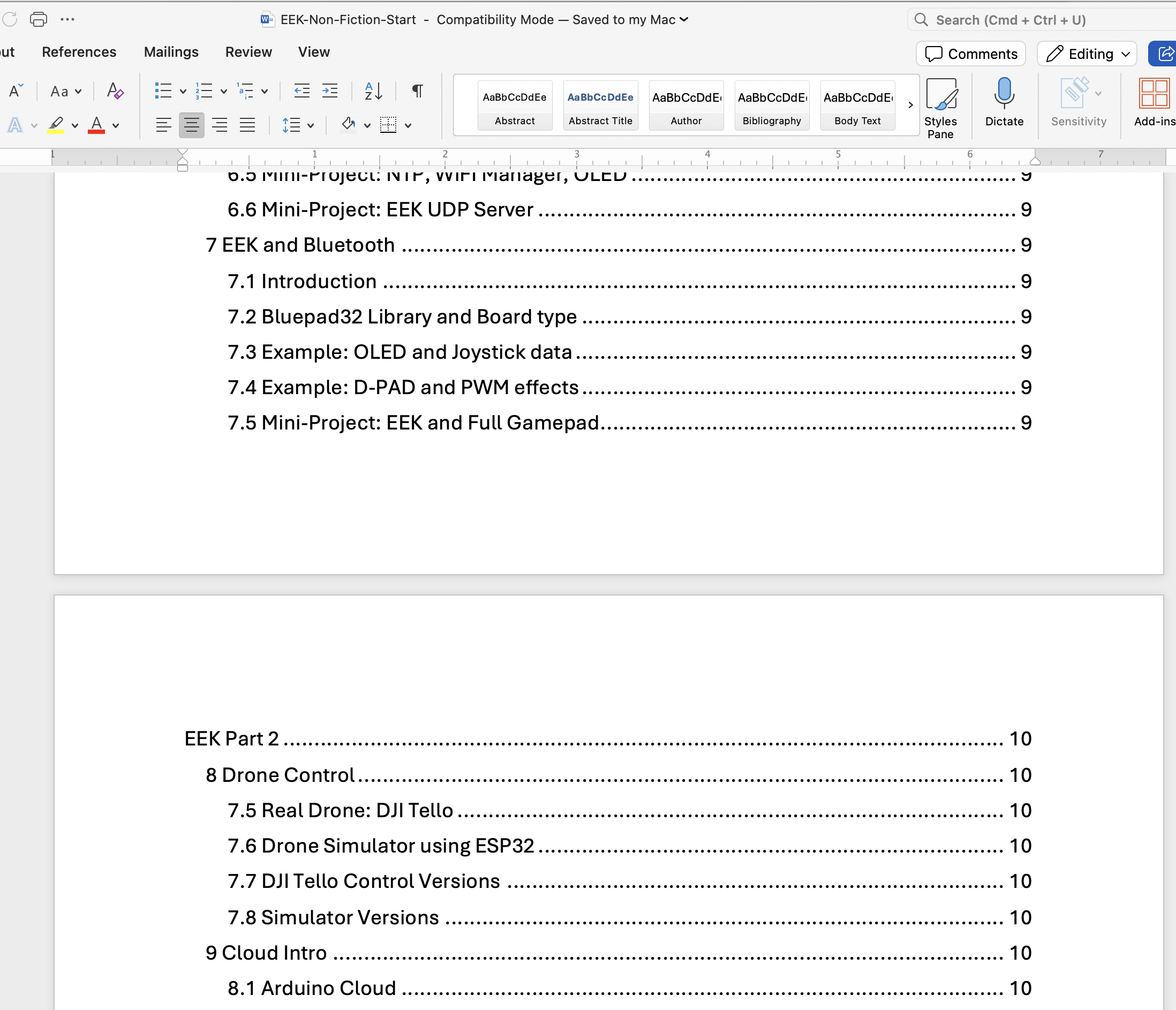
I am getting close to the effect I want but as I move to the next Part heading (Part 2) which I want as unnumbered, the chapter heading that follows is numbered correctly, but the first headed subsection retains the numbering that the last subsection of Part 1 ended with. See:
Well, I guess it was simple-minded operator error – can’t mix <$n> and <$hn>. When I made both chapter and section titles use <$hn_level1> I got the behavior I was looking to achieve.
E.g.
and the same for the headed subsection, I got the increase in chapter number past the unnumbered Part header boundary and the reset of the subsection number.
E.g.
Unfortunately not. With the progressive slipping into irrelevance, word processors have remained to the same concepts of the eighties, and i doubt they will adopt a more modern approach inspired to page layout or web site development programs.
Images are embedded, converted into their own format, and if they include a command to relink the embedded images they save them in their new, arbitrary format and with arbitrary names.
These images are usually recompressed, and with colors coded to RGB. No fidelity to the original is even considered. No way to recover images intended for professional printing. A word processor document has to be considered just as an intermediate for text and styles, to which images will have to be relinked by the page designer at the publishing house.
A compromise I’m experimenting is that to insert both a Markdown image link, and a visible image dragged/linked from the desktop. The first one will be the actual image, the second one a preview to be used while editing.
The Markdown image link and the preview image have different paragraph styles applied. In the Compile format I tell Scrivener to remove all elements with the preview image style.
In the above example, “ipath” is a variable for the full image path, that will be replaced during compile.
The original images will be the ones that I will then use for the resulting Web site or PDF created with a page layout program. Links in the Web site will, luckily, remain the same as written in Scrivener; not so for PDF, if the intermediate exchange format has to remain something like RTF or DOCX.
I’m hoping (but not believing) that Affinity Publisher will allow importing Markdown files directly. The only intermediate formats generated by Pandoc, that can preserve image links, are HTML and ICML. ICML requires a bit of work to be converted to IDML and be read by Publisher (InDesign can already), and is a bit basic. HTML, I’ve still to try extensively.
With the progressive slipping into irrelevance, word processors have remained to the same concepts of the eighties, and i doubt they will adopt a more modern approach inspired to page layout or web site development programs.
OpenDocument format supports that, and with Scrivener you can achieve an embed-free output. You can test it easily enough by switching your compiler to MMD → FODT and observing the results. A neat and tidy folder with all of your original images (if you linked them in Scrivener, if you embedded them then… well they are toast), with their original names, and an .fodt file that references them.
Of course that is a convenient output solution not a mandatory arrangement. You can link to the images from anywhere, and LibreOffice handles them simply.
I’ve heard Affinity Publisher is going to be adding ODT support at some point, so you might not have to struggle with this mediocre file format forever.
Thank you for the information about exporting ODT from Scrivener. Publisher including this file format would be huge. Unfortunately, there is a lot to fight to make them add supported file formats, but one can hope.
Yeah, developers ignoring competitive formats and just implementing “Word” because that’s what most people want is part of the problem. There are better formats out there, and word processors that have gone beyond the '80s in their design. Honestly LibreOffice almost feels like a DTP, it uses different jargon and interface to describe the master page concept and full stylesheet driven design. For example I wouldn’t mess with manually numbering at all, as in the above, because the stylesheet drives numbering when you load Scrivener’s output into the template. That is all around a superior approach because moving a chapter around late in the editing process won’t require manually renumbering hundreds of headings, as though one had typed them in by hand (which is what Scrivener is doing… just faster than a human can).
Thanks @AmberV and @ptram for your replies.
I am working with the company Elektor on a publishing project and it may be that their workflow is not really dependent on a Word docx delivery. That’s what another author that Elektor works with uses, but he has to let the editor be able to correlate figure number references, that are generated in Scrivener and shown in the .docx file, with the source image files. He also compiles an HTML output that retains references to the files as originally named and the editor combs through the HTML to see what’s changed as new document drafts are made and delivered.
I am just starting the writing project and I am liking Scrivener’s approach to things so far, especially for auto-numbering and figure citations. Maybe my editor (waiting for an introduction) will be open to fodt instead. This has the advantage of a good Word-like document interface: formatted text and embedded figures with all numbers as compiled from Scrivener AND the source image files as siblings to the fodt file.
For Pandoc > ODT it would be quite easy to make a Lua filter to link rather than embed images in a document. The XML is really simple for ODT, and in fact Pandoc already uses links for OpenDocument output (which ODT uses under the hood):
For DOCX I did check the XML source, and it was horrible as usual, but I suspect just as for my Index builder filter, it could be made to work too…