(UPDATE As suggested I’ve converted this to a wiki. )
I am slowly accumulating a collection of regexes for various tasks, such as highlighting duplicated words, and it occurred to me that many other have probably done the likewise.
They’re powerful tools and it can take a while to get them working just right, so why not save your fellow scribblers an hour of hair-pulling by sharing what works for you.
Before making this a wiki I made some general suggestions about what a post might look like, and thanks to @Vincent_Vincent we already have a nice example that explains his Para Exploder, – what it’s for an how it works.
If you’d like to share, that is a great example of key points to cover (feel free to suggest more)
What it does/short title
Why it’s useful/how to exploit it
Proof of concept examples
A pat on your own back for being able to bend PCRE regexes to your mighty will.
StackExchange is a great resource for ideas/templates, but things may need to be customised for Scrivener, so let’s collect ours here.
[V.V in addition:] Although they don’t always work back in Scrivener, regex101.com is a good place to design and test formulas. (They also list the available code elements.)
Thanks for all the initial input! (I’ll add mine when I have more time)
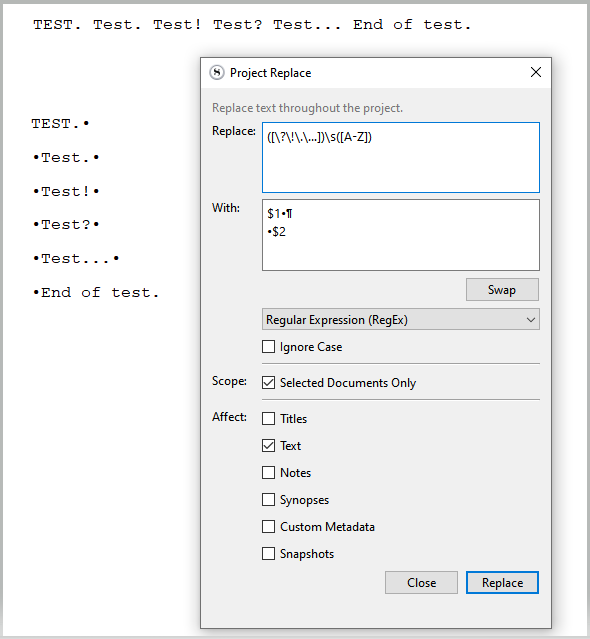
I use it to “explode” paragraphs into their sentences (each sentence technically becoming a paragraph) when I want to do some deep editing of a text in printout. (Say I want room to scribble, or be able to freely reorder sentences, etc.)
It marks the sentences at their beginning and/or end, depending on if a said sentence was previously connected to another sentence in the context of a paragraph. Thus giving a visual cue as to what is – and what isn’t – in fact altogether a paragraph, as well as allowing to quickly rebuild the paragraphs, through a later Project Replace operation.
To later reassemble the paragraphs, replace with a space.
(No RegEx this time. Just a normal replace.)
. . . . . . . . . . .
Though unlikely (it is not the same one as the lists’), first make sure you don’t somehow have the dot symbol already in use in your project.
Use any other “special” character/symbol if needed. Which one doesn’t matter, as long as it is searchable and exclusive to this operation.
What does it do? Highlights repeated words, optionally excluding certain patterns.
Why? To find and eliminate the "the the"s, and the "and and"s, etc., that inevitably creep into an MS, whilst optionally ignoring deliberate repetitions, like the e.g. “click click”
Regexes
for all repeated words — (\b\S+\b)\s+\b\1\b
for all repeated words except… XXXX, YYYY, etc. — \b(?!XXXXX\b|YYYY\b)(\w+)\s+\1\b
To add another pattern to ignore, added another “|ZZZZ\b” (without the quotes) at the end of the first ( ) group.
My understanding of regexes is limited so I will only say that AFAIK “\b” marks a (word) boundary, and the “\1” is a reference to the first match in brackets ( ) that does the “and here it is again”, secondary match.
Regex to find two opening double quotes without closing the first one.
Why? Find and fix typos and omissions in marking off dialogue
Regex
\x{201C}(?:(?!\x{201D}).)*?\x{201C}
Acknowledgement: ChatGPT4 and ME for hitting it repeatedly with a stick till it got it right, as in, finally, “it works but only if you leave off the /s you specified” “oh, yes, as a large language model I can be a complete dufus, can’t I?” (or words to that effect)
Here are a few REGEXs that I frequently use when editing: Finds any repeated words. \b(\w+)\s+\1\b Finds missing capital letters after the end of a statement, question, or exclamation. Excludes “etc.”, “e.g.”, “i.e.”, and “vs.”. (?<!etc)(?<!vs)(?<!e.g)(?<!i.e)(?<!..).\s[a-z] Finds numbers under 100 (so you can write them out with words). [^\S]\d{1,2}(?!\d)(?!))(?!-)(?!:\d{2}) Finds missing Oxford commas. \w+, \w+ and Finds words that begin with a vowel immediately preceded by an “a” rather than “an” a [aeiou] Finds , and . inside quotation marks (for UK English) = .,?! Missing Cappitals after full stop [^.][^A-Z]. [a-z] Missing Brackets ([^)]*$
This REGEX is my killer for discovering “Show don’t Tell” words in my texts. Its big but it really catches most instances where a writer should be Showing instead of Telling.
REGEX is just like learning a new language, albeit a very powerful for handling text patterns with the most concise use of symbols. It would be nearly impossible to perform some searches just using the simple dialog box.
I understand your point and don’t want to question the power of REGEX. I wasn’t thinking of a simple dialogue box either, but rather an intelligent, perhaps AI-based search function that searches texts with simple commands and criteria to achieve the desired result.