(NB I have checked the manual before posting; I didn’t find an answer - doesn’t mean it isn’t there, just that I didn’t find it! It is compendious and it’s sometimes hard to know whether the question is not addressed or one has simply failed to ask the right question… )
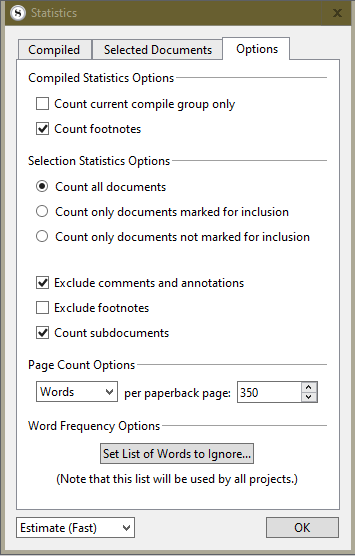
Celebration I just discovered the Word Frequencies option* at the bottom of the Project… Statistics dialog.
Confusion Unexpectedly I found my name occurs ~200 times, but I am not a character in my novel. My name is not in the documents it is in the comments (comment author). I suspected that, but sought confirmation by searching and found that my name was found (via comments) if the search target options = All, but not otherwise.
Analysis This implies that search All includes comments, but comments are not separately specifiable for searching or exclusion.
This suggests that comments may also being included in word frequency analysis.
Questions That’s not such a big deal, but can you confirm that
word counts are not including comment text?
word frequencies are (erroneously?) including comment text? (If so, any workaround?)
Comment text is in search scope of All, but is not independently searchable (or excludable)?
Bonus Confusion I did a quick test on a single document where it seems that comment text isn’t counted, but on the other hand the word frequency for that single document with a comment by me also does show my name in the word frequencies.
* Applause Word Frequencies, yay! Very nice! I don’t suppose one can export that, or get a breakdown document by document can one? I was in the middle of doing precisely that using Python & NLTK when I discovered the word frequencies capability. Naturally I am looking for overuse and rare words that might be typos or should be replaced with a more common word, etc.
Good catch! It definitely should be excluding all of the text in comments and annotations from the word frequency list as well, when that option is checked.
I don’t suppose one can export that, or get a breakdown document by document can one?
In the latter case, only by selecting a document and checking the Selected Documents tab in this window, the moving on to the next.
Export is supposed to exist, but it wasn’t added—it would be as simple as selecting any number of words and copying and pasting (tab delineated data for easy input into a spreadsheet).
OK, Amber, thanks for confirming the observation. Moving on.
Any plans to fix the search options to add Comments to the list of selectable targets?
The word frequencies are interesting, but - no criticism intended - not terribly practical for my use-cases; since I’ve got the .scrivx parser etc. I think I’ll knock up my own concordance thing with Python (when I’ve finished the MS!)
Basic outline for anyone interested (and also notes to self in case I forget the plan ) :
From scrivx Map IDs to folders so content.rtf is associated with a binder item - DONE
For each content.rtf
extract text - DONE
Tokenise with NLTK, remove punctuation, remove stopwords
Lemmatize (tried Porter Stemming; stems are not so readable and/or ambiguous)
Use Python collections Counter to count words per doc, and then to update a global Counter
Probably convert results to pandas dataframes and then do histograms…
You mean to isolate the search scope down to comments only? If so there aren’t any immediate plans for that in Project Search, no. Otherwise though:
Edit ▸ Find ▸ Find by Formatting... already has this scope as well as many others, and though it works in a more traditional step-by-step way, it does have the capability to escape the item boundary and jump to the next instance, wherever it may be in the project.
Although there isn’t a scope for it, comment text is indexed and can be found by searching for it in Project Search, so long as the Text scope is active.