Typically, markdown documents are expected to (or allowed to) have metadata at the top, in YAML format, such as:
Date: 2018-07-09
Title: "My Document Title"
Blurb: "Some vague description of the article"
I’m toying with using Scrivener to generate articles into my web site, which expects Markdown files, with YAML I need to specify. I’m having great difficulty discovering where this is specified in Scrivener and how to control its format. Searching the manual for “metadata” does not seem to be the way, so perhaps someone could offer me an outline and/or some links.
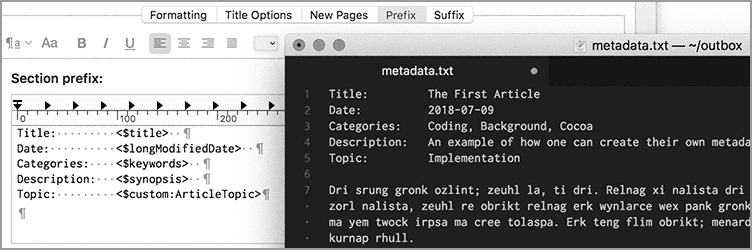
I’ve turned on the metadata checkbox in the Compile Format Section Layouts, and indeed it starts coming out. System-provided metadata seems to be tabbed in:
Created: June 28, 2018 at 3:41 PM
Modified: June 30, 2018 at 10:01 AM
Status: No Status
Label: No Label
When I provide a custom item using the little tag thing in a document, that item appears but is not tabbed in.
How can I get them all NOT to be tabbed in, since I pretty much want metadata left justified? And where are those standard items defined, so that I can add in the ones I want and remove the ones I don’t.
Secondly, I need a metadata line “Categories:” which will be a list, but not of fixed elements but elements that I provide on the fly, as needed, in specific documents. How might this best be done?
Certainly if there’s a nice self-contained writeup of this already, please point me to it, and tell me how I might have found it on my own.
Thanks!