In another thread, I wrote:
One limitation is that Scrivener Sync does not convert its rich text to Markdown when syncing to the sync folder and does not convert Markdown to rich text when pulling the plain text back into Scrivener.
@popcornflix made an interesting suggestion:
Pandoc can convert RTF>MD>RTF; is there a way you could automate it with a bit of JavaScript and folder triggers? I’m on a Mac, and I could do this using built-in AppleScript or a macro app called Keyboard Maestro. I don’t know Windows well enough to work out the particulars.
After thinking about it, I think I have an approach that would work well in Windows:
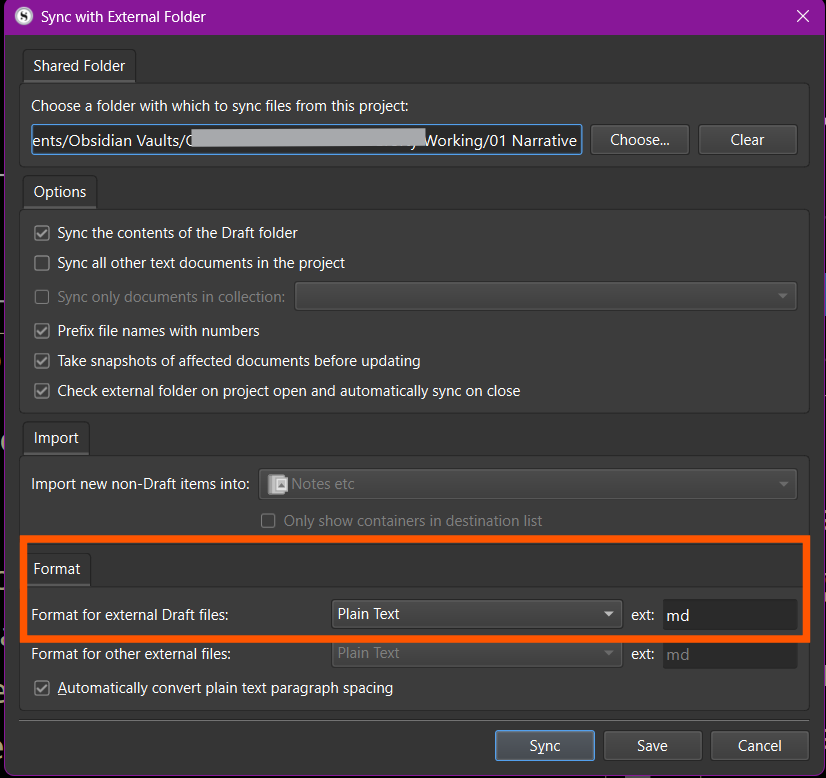
As suggested, Scrivener drops RTF files into the External Folder Sync, and Pandoc is perfectly happy to convert those files to Markdown and back again. The missing piece is just a watcher that notices when something changes and runs the conversion automatically.
Caveat
I’ve not used Pandoc, but I read up on it a little to come up with this solution. I haven’t tested it, though.
On Windows, I’d probably use Python for this because it’s already part of my workflow, and the watchdog library makes folder watching straightforward. I’d point one watcher at the Scrivener sync folder so that whenever Scrivener updates an RTF file, the script immediately runs Pandoc to convert it to Markdown and saves the result to my Obsidian vault. Then I’d point a second watcher at the Obsidian folder so that when I edit the Markdown version, the script converts it back to RTF and drops it right back into the sync folder for Scrivener to pick up.
The only thing I’d be careful about is ensuring that Scrivener alone controls the filenames and folder structure (I can almost hear @AmberV warning me about that, haha). As long as the script only replaces the contents of the files and doesn’t rename or move anything, Scrivener is perfectly happy. From what I’ve read (see my caveat above), Pandoc doesn’t have any trouble preserving the filenames, so that part is easy.
Setting this up is not something I personally need right now because I’m fine working with plain text in Obsidian and occasional Markdown syntax when writing in Scrivener, but if I ever wanted a true round‑trip Markdown workflow, this is how I’d build it. It keeps Scrivener’s sync folder intact, gives me Markdown in Obsidian, and lets Pandoc handle the heavy lifting in both directions.
Thanks for the suggestion, @popcornflix. If I ever implement this approach, I’ll be sure to share how I do it.