Hello! I browsed and searched here and there on these forums, but I cannot find any way to detect repeated words in a text - I am not talking about statistics, but a tool able to enlighten close repetitions of words, in order for the writer to spot and eliminate them.
Is there already something similar in Scrivener? If not, I think it should be implemented in some update, it doesn’t seem such a difficult feature to add!
Sorry, I was not very clear. For ‘repeated words’ I did not mean the same instance of a word put/left by mistake as in ‘I am am Italian’.
I meant rather the recurrence of the same word like twice in a sentence, or three times in a couple of lines. As in: ‘His eyes were blue, while his wife’s eyes were deep green, a very nice eye colour’. These are stylistic blunders that sort of tool (recurrent word detector) could help to correct
Even I am looking for a tool within Scrivener that will highlight word density and proximity/ spread – how often I have repeated a word and how close the repeats are to each other.
For example, in my case, I tend to use the word “also” a bit too often! So it would be most useful if Scrivener can highlight every occurrence of “also” in the text, giving me a visual overview of how close together these alsos are.
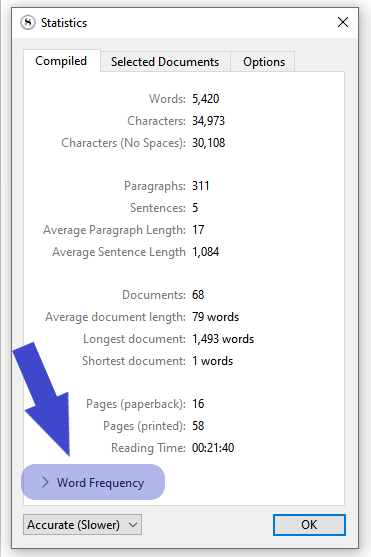
Similarly for other words, Perhaps this feature can be added to the Statistics box where clicking on an individual word shows you where all you have used it in the document.
Incidentally, to the previous poster, I don’t see any option under Edit to run a Spelling and Grammer check. The only option is Spelling. I am on the latest Windows beta – has the Grammer check been removed?
It would be super awesome if you could tell Scrivener to find all documents in which a certain word is used more than x amount of times within a span of y number of words.
This would help so much with eliminating the ‘Favourite Word of the Month’-phenomenon!
EDIT: Although one of my more pressing problems - using the same five conjunctions over and over in close proximity - can be solved with Scrivs search function, b/c you can search for more than one word at a time. It still involves a lot of scrolling, though.
Correct me if this is already possible, but I’d settle for an instance count in the little search box at the top right corner when you type something in. Eg:
Search box: ‘eye’ [3] <-- number of times I’ve typed that character string in the current document
That way I can instantly see if I’ve used a word before, and how many times I’ve used it, without having to scroll through the document looking for highlighted words. A lot of the time, to make a decision, the only thing I need to know is that number. I’m a fiction writer and I waste a lot of time during editing scrolling back and forth through my document trying to figure out whether or not I’ve overused a word. It’s hard to remember if you’ve used a word when you’re constantly taking out phrases, sticking them back in, moving them around, etc. Especially if you did all that work the day before or last week.
I know you can get that information from statistics, but that takes far too long. I can’t be constantly stopping and generating word counts for every word in the project when I just need that one text string for that one document. Especially when it counts variants as separate words and I can use a partial word in the search box to highlight different variations of the same word (eg. eye, eyes).
Any news on this feature? So, well, I apparently probably use too many instances of “So,” “Well,” “apparently,” and “probably” in my writing, and was wondering if there was a way to count how many times they’re used in a manuscript, or maybe add them into the linguistic focus mode, etc.
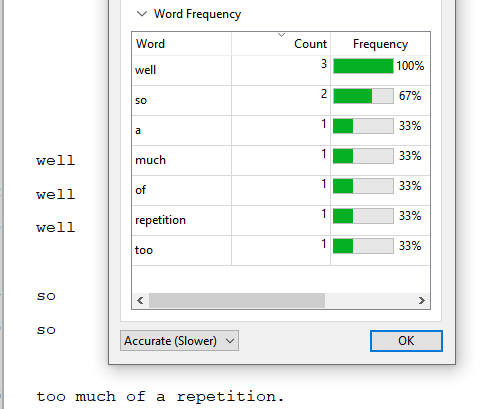
Or at the very least a way to search through the Word Frequency list… trying to scroll through a VERY long list to find a certain phrase/word could be tedious… and in the case of "So, " I’m not looking for lowercase ‘so’ or "So " without the comma, etc… it’s a very specific grouping I’m looking for a count of.
No recent news. See this thread for a similar discussion. Here@AmberV of L&L Support mentions that current Mac Scriv features for finding duplicates will someday make their way to Windows. No target date was given for this–providing target dates for features is not L&L policy. You might want to have a look at the Mac Scriv manual to see whether these features are what you’re after. This post in another thread discusses the Mac features a bit, but the manual will give you details.
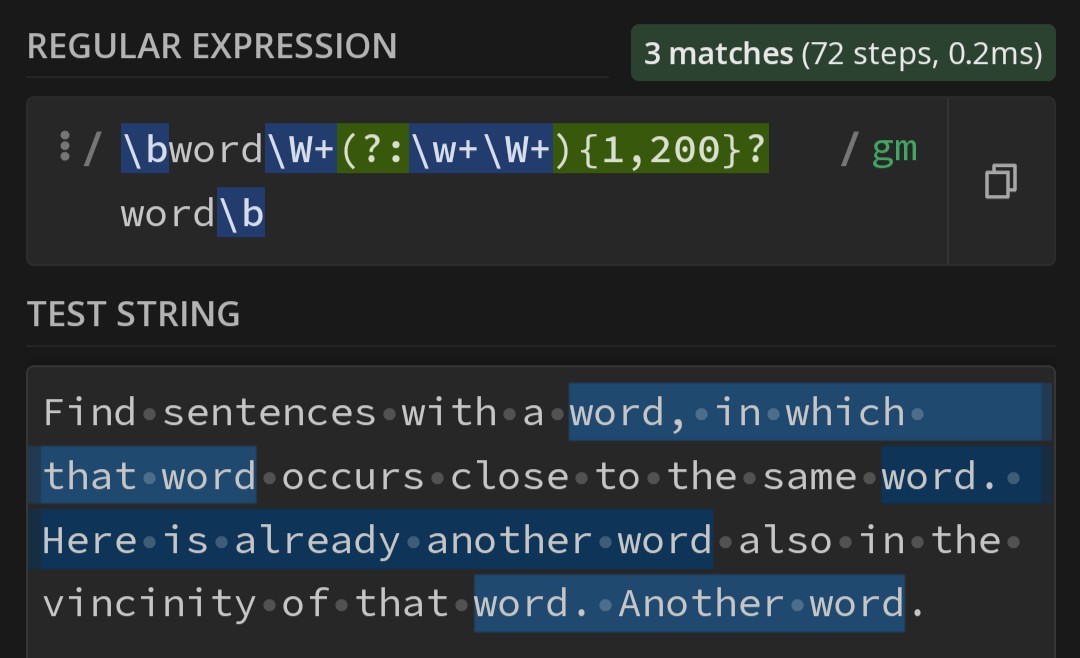
Finally, see this post that offers a Regex that finds duplicates. I’ve never tried it, so not sure how well it works.
I suppose I could go through the sync files and do an egrep or the like, but not every writer was a coder in a former life, so I was wondering if there was a built-in feature. Hey L&L - are you hiring?
+1. this is the killer feature that scrivener is missing for me. if there was some way to underline or highlight words that are used too closely together in realtime (rather than with with, say, a search function or button you have to press), that would be ideal. even better would be to have toggles for it to recognise only certain parts of speech like adjectives/adverbs (similar to how IA writer handles it).
i’m not sure what scrivener’s code base is like, but i’ve seen solutions for this on github that seem like they’d be pretty easy to implement. this codepen in-particular demonstrates the feature nicely (and it works in realtime): https://codepen.io/harunpehlivan/pen/MWeJejY
The word frequency panel is sort of useful, and specific words can always be searched for (using regex if necessary), but a tool to highlight proximity of non-common words (I, he, the etc) within a doc would be fantastic.
I’m just editing a draft ms now by eye, and this is my most common problem. A tool to help with this would save me a few days’ work