I am writing a technical manual and there will be a lot of images. I am proposing to used a placeholder with link to the image.
I am looking for any tips on
a: doing this
b: subtitling the image with say chapter.section.image number
Also, I have tried “hard” naming the images e.g. Fig 21.3 for Chap 21 fig 3, but this gets messy should I reorder the chapters on say the corkboard.
Can you get away with using Pandoc or Quarto for the document production process, so that you can benefit from its better document generation capabilities and wider array of file formats? For example I use LaTeX, and I’ve never had to mess with anything so fiddly as managing numbering or links to them. I can instead very simply indicate which figure to refer to by its handle or name, and LaTeX automates and formats the rest from that (resulting in what you see in Scrivener’s own user manual, for example): the chapter.fignum style numbering itself on the caption, the caption formatting, the look-up from the cross-ref point to get that number, and the placement of the parenthetical hyperlink itself.
Here is Quarto’s documentation on figures. Just from skimming the ToC, I feel one could safely surmise that for technical writing this is going to be a far superior approach than trying to do everything in Scrivener itself, without any external help. It’s an okay tool for that, but that’s not its primary focus really (end format production), and I wouldn’t stress its auto-number system for much other than basic setups.
It’s worth considering that it pushes the problem you describe at the end, further down the workflow rather than solving it: the result is static text in the output, just as though you had typed it in. While some of Quarto/Pandoc’s output does likewise out of the box, I would say these are different things because in that case you can get very close to a finished document with them, one that will not require working with it extensively to get its formatting finalised. With Scrivener’s built-in word processor output on the other hand, it is very unlikely you will get to that point for technical writing, which means the .docx file or whatever will be in a primitive state, and likely go on to receive all future edits, without the original project being returned to. And that means static numbering is still a problem.
Here is a brief introduction to the idea of using Markdown in Scrivener. Our approach is to look at the process of automating or making easier the writing process with Markdown. While you can just drop raw .md straight into the editor and have it work fine (as described in that post), most will be using some combination of features (documented in Chapter 21 of the user manual PDF—which incidentally I did not number in Scrivener either) to go a bit beyond what can be done with that.
In short:
You don’t have to learn much about Markdown to get a lot of benefit back from it. In fact many don’t even write with it in the editor, and only learn the little bits they need to make the compiler do that for them (what it doesn’t do already, which is fairly comprehensive).
The integration can be so seamless that you would be producing final, or close to final quality documentation straight out of the compiler. To again use the user manual as an example, a document of that quality can be produced by clicking the compile button and nothing more. So we aren’t talking about not using Scrivener in other words, we’re talking about using it to produce better documents, by hooking it up directly to better converters.
No worries, I didn’t explain much, because if some of that jargon means something to you, then the main message is that: yes, Scrivener supports integration with this technology.
If it’s all a wild new world, and you have never seen a tool like Obsidian or Ulysses or even iA Writer before, there may be some gaps in what I wrote. Feel free to ask any questions, but we also have a whole Markdown & LaTeX forum here, which years of discussion on how to work with Scrivener this way. There you will tend to find a higher concentration of those using Scrivener for technical, sciences and academic work.
I would start with Quarto (documentation link), because it is (like Markdown and Scrivener) a bridge to other formats, whereas LaTeX is very specifically oriented toward print (or at least fixed layout on screen via PDF); it is an end point.
Quarto on the other hand can get you to Word, OpenOffice, ePub, presentations, web sites[1], other bridge formats, LaTeX too (and other higher-end typesetting), and lots more. From there, you have dozens of pathways and can work with anyone.
And if that looks promising, check out some Scrivener-specific discussions, including some fantastic templates from fellow users:
The main reason to target an end-format specifically, like LaTeX, is if you’re sure that will work for you and be all you need. There are of course advantages to doing so. Any bridge format is going to by necessity be an abstraction, or a generalisation of document formatting. With Quarto/Scrivener I can say, “put a footnote here, with this text”, with LaTeX I can say, “this footnote is special and should be in the margin, which will cause this page layout to have a wider margin than the rest of the book, and space the left edge of the footnote 18.842pts from the justified right margin, using 10pt font, and bold face on the anchor number”. That’s the difference in a nutshell, and that should also illustrate which of these is, by and large, a better tool for writing.
When you are on their site, you are looking at an example of what it can do. ↩︎
So what is the main advantage of quarto over just using pandoc, aside from some “opinionated” decisions about layout that are kind of burned into quarto…which may be a good thing if you are happy with those layouts and don’t want to mess with it…or not if it doesn’t match your idea… but anyway I am embarking on some writing… initially will all be output as various forms of markdown for various blog systems such as Hugo, or GitHub readme’s and wiki’s, etc… basically slightly different flavors of markdown. But later on I may go to ePub or HTML or even printed PDF…so I’m just thinking ahead about the workflow I should adopt…
I mean it seems like the first phase, where I am targeting various flavors of markdown…its pretty simply I can just make edits to the included markdown compiler that comes with Scrivener, and near as I can tell at that point I don’t need pandoc, don’t need quarto…just tweak the compiler for the various flavors of markdown…which are really close anyway, just some slight differences related to callouts and little additions they each provide to go slightly beyond basic markdown.
Do I have that right so far?
But then I’ve seen of course many people talking here about pandoc and how that will offer in the long run more flexibility. So if I wanted to do that, would I create some kind of pandoc compiler format that follows panda’s own version of markdown(which I am not familiar with yet), and then use pandoc itself to translate to those endpoint markdown flavors initially. (and later go to ePub, PDF, etc)… or quarto markdown? Does Quarto have its own markdown? And aside from being able to easily crank out quarto layouts…what would be the advantage of doing the quarto markdown approach over pandoc markdown… I don’t know much about either one yet, on whether they would even be able to easily handle the various flavors of markdown I need to crank out now in the short term…which seems most easily handled by simply editing scrivener’s compile formats and don’t even need to mess around with pandoc or quarto unless there are some compelling reasons I am not aware of yet.
There are so many options and everyone is doing different things. I find it mind numbing to follow some of these discussions. Some of you are DEEP in the rabbit hole and I applaud you…but its hard to know how I should best setup my compile setup to get going and not end up down the wrong rabbit hole for too long.
My hunch is you are concerned about an uncertain future. Do what you do now in Scrivener. Focus on the writing, which is what Scrivener excels at. Scrivener output via the compiler is flexible enough that when you get to the future imagined you’ve lost nothing by not going there now. Explore Pandoc and/or Quarto when your output needs change and native Scrivener can’t do it.
Mostly yes. And, um, a bit no. Scrivener’s compiler actually natively supports two flavours of markdown, MMD and Pandoc (but it only bundles one executable, MMD). Nevertheless for outputting markdown the workflow is 99.8% identical.
As mentioned above, Pandoc is natively supported. Most of us use Scrivener’s features and map them at compile time. Your experience in Scrivener will be identical, Styles and/or Section Types and/or custom metadata. The mapping to Pandoc or MMD is mostly identical.
Click the checkbox, Scrivener outputs Pandoc markdown for you.
So there is little work involved if you did want to “transition”. My (probably unsurprising) advice is to: nevertheless use Pandoc from the start. The workflow is basically identical, the only downside is you need to install a single exe, the upsides are many… Like for example Pandoc natively supports Github-flavoured markdown, so you can let it handle some of the small low-level differences to reduce cognitive load if you do want to output to Github.
Quarto is Pandoc with Bells + Whistles so the core markdown is identical. It uses Pandoc’s markdown with extensions for doing things like multi-panel figure layout (only useful for academics probably) etc. Quarto is less flexible than Pandoc (it demands every related file in a project folder), so I usually recommend people use Pandoc to start, then they can tweak/twiddle towards Quarto only if they really need a feature it offers. For example if you want to make a full website with multiple articles liked via a nice navigation navigation and hosted on Github pages with automatic push, that is just one command in Quarto.
My 2¢ — use Pandoc at the start. The compile format for Pandoc is the generic markdown workflow in the Scrivener manual, there are no gotchas other than your ability to download an installer. You in fact don’t even need to run Pandoc to use a Pandoc-flavoured compile if you don’t want to run post-processing from Scrivener (which if you are outputting to markdown is not needed).
My 2¢ — use Pandoc at the start. The compile format for Pandoc is the generic markdown workflow in the Scrivener manual, there are no gotchas other than your ability to download an installer. You in fact don’t even need to run Pandoc to use a Pandoc-flavoured compile if you don’t want to run post-processing from Scrivener (which if you are outputting to markdown is not needed).
Already installed pandoc via macports.
so from what you are saying, if I click the checkbox you mentioned (which I haven’t been able to find yet), then Scrivener outputs pandoc markdown instead of generic markdown? I was under the impression previously that the markdown was generated purely by the way the factory compile formats are configured…in other words its included with Scrivener that way, not hard coded inside the program somewhere, but do I have that wrong that Scrivener has some mmd and pandoc format markdown that is built into, or are these provided by way of included compile formats? The reason I ask is because I was thinking if my end goal in the short run is no printed anything, no PDF, no ePub…just markdown in probably GFM format and/or sometimes some extensions to it… then is that something I would handle by modifying the included compile formats…or does that require post processing with scripts or pandoc or something like that?
I like the idea of using pandoc markdown from the get go, I want to setup my scrivener styles and sections so that I can’t have to an actually write any markdown in scrivener while writing. I specifically do not want to look at markdown in there. I will use carefully crafted styles and sections that will compile all markdown. But I am not sure if I will be able to generate all the markdown extensions directly in scrivener via the compile formats…or if I will need to post process some stuff to produce it? I was kind of under the impression that mainly the reason for using pandoc would be in order that later on, if I wanted to crank out a Latex version or whatever, then pandoc post processing would do that for me. but for the initial markdown output, I guess no post processing needed, its just a matter of outputting markdown + extensions. By extensions, I means things like shortcodes, etc…things that systems like Hugo have implemented…that are kind of above and beyond generic GFM markdown to enhance the output a little bit. I really would like to find a way to minimize the very little or none the amount of markdown that is written inside Scrivener…using instead styles and section types to compile it…
Anyway I will take your advice and design my styles and section types according to outputting pandoc for Hugo…and we’ll see later I guess if that will translate to simple GFM output somehow, its still not clear to me if I would do that with pandoc Prost processing, or instead create a completely separate compile format that outputs GFM instead of pandoc…and basically don’t need any post processing…don’t even need pandoc installed right?
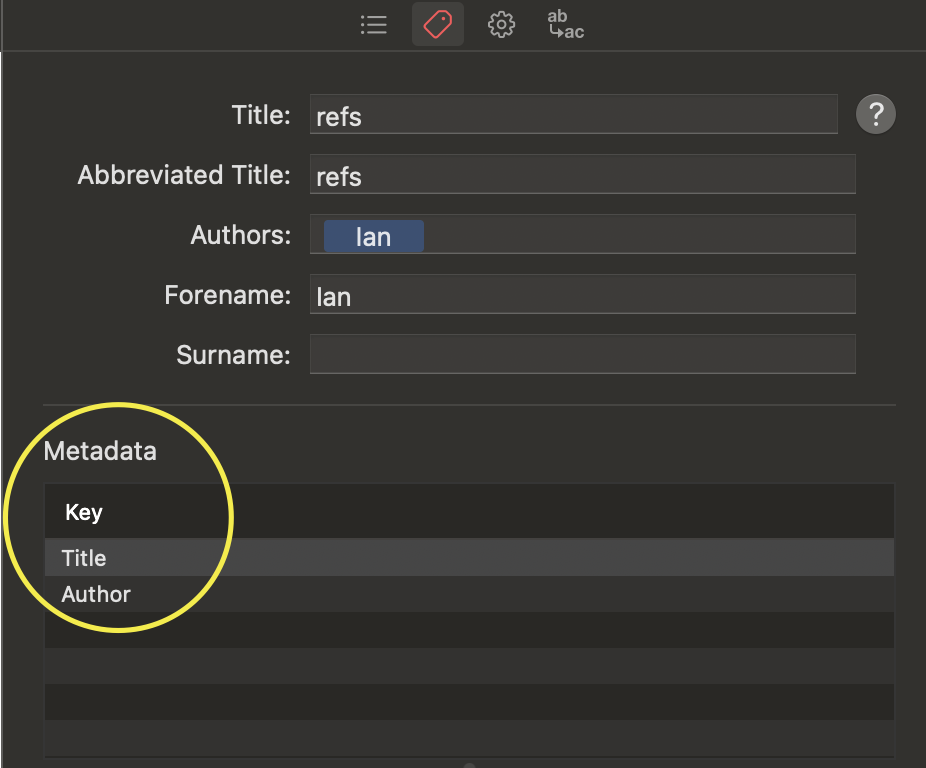
Scrivener generates markdown for its native functions, for example tables, figures with captions, metadata etc. So e.g. the way metadata is formatted is different between MMD and Pandoc, and clicking that checkbox affects what metadata looks like from this compiler interface:
Personally I don’t use metadata from the UI, but prefer to write it as a frontmatter document.
For most bits of markup yes, you can customise as you please, but for lists / figures / metadata / tables / links (i.e. the native Scrivener editor features that have to be mapped, not a generic style), these are hardcoded. but I suspect pandoc-flavour will work for GFM without issue
The compiler can handle this without issue. And I wouldn’t overthink this, 99% of the markdown will be consistent.
Right, you can craft the markup with required extensions and tweaks from the compiler without needing the pandoc command installed, you don’t need pandoc for post processing for single output (even though the markdown is compatible with pandoc, i.e. don’t confuse the format with the tool). There will be some fringe issues where Pandoc can help to improve the workflow, and yes, as you want to expand the outputs, Pandoc’s many features will start to shine.
Markdown formats: GFM is a superset of commonmark, which was also codeveloped by John who is the orignal and main author of Pandoc.
You can see what markup extensions each flavour of markdown uses with this command: