I want to compile via markdown converting richtext to markdown yet using pandoc processing for converting the markdown file to word with zotero placeholders.
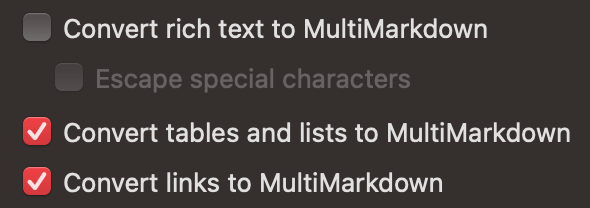
when I use the option convert richtext to markdown + escape special character this still transforms
this: [@deleuze_tausend_1992 10]
into this: \[@deleuze\_tausend\_1992 10\]
how can I get my richtext converted to markdown yet my pandoc zotero placeholders intact?
I am very sorry, if this had been hundred times answered, but I couldn’t find the solution to this anywhere.
I know, I could simply search+replace the wrong characters in the markdown file and then hand it over to pandoc, converting it into a word document with dynamic zotero placeholders, yet it would be much better – since it works perfectly – to use the processing function of the scrivener markdown compilation to get it in one export.
and regarding Scrivener styles: can I use them to transform bold and italics within a paragraph into properly styled markdown? If this is possible, I could do it without using RTF to MultiMarkdown… and my problems would be solved.
in this case: thanks for the unrequested advice! (now I have to figure out, how to have the same convenience for unnumbered and numbered lists… but one day I will).
However: if there was a solution to my original problem, I would be very grateful to hear!
Being able to use richtext to markdown export seems to me quite important for a richtext editor like Scrivener. It would be amazingly simple, if I only could make the _ appear just as it is in the exported markdown file before I give it over to the pandoc processing, preparing it for word and zotero magic.
And in your compiler format, make sure that style has “Treat as raw markup” (note just as an example I also inject the @ via the style, keeps the text a smidgen cleaner):
This is a **test**. Here is a ref [@peters_2024]. This is a \_test\_ (that has preserve formatting) to see what happens to \*stuff\*...
This gets you rich text (note the bold) and citations no matter what characters are in your BibTeX key…
Third workaround: there is a Preserve Formatting option in Format menu. If then in the compiler you activate:
Then you get the same effect as the style option without needing to create a style. I find this less useful as a solution…
BUUUUUUT:
These are converted whether you use rich text or not. In fact almost all Scrivener native functions work: lists, tables, cross-references & links, figures + captions, usual placeholders, etc. all work without needing to use “Convert rich text…” — so the main thing that “Convert rich text…” uniquely does is bold and italic. Styles can do these easily, and you can use System Preferences or a tool like BetterTouchTool to bind the same keys to make it transparent. You end up with semantically “pure” text without any additional heavy lifting. So my unsolicited advice remains: the best workflow that fully utilises Scrivener’s editor features (RTF or otherwise) and a flexible pandoc output is to use Styles…
Again, thanks so much!
creating a citations style for the whole placeholder, which then is “treated as raw markup” during the export is doing the trick.
When I find the time I will work on getting used to do everything with styles, just glad that, in the meantime, I have a solution for the problem.
Just in case others come across this topic in search for a solution to the same problem:
Another, clean way of preventing the issue to arrise in the first place would be: enforcing citation keys in zotero (via the better bibtex plugin) without any “_”, like [@deleuzetausend1992], for example. Unfortunately, this was – at least for now – not a solution for me, since changing all citation keys would break the backward compatibility of my zotero library for early projects that I worked on in LaTeX.
one last question, hopefully: the solution, as it turns out, does not work for footnotes, since I cannot map a style to a part of footnote, can I?
If this indeed is not possible: how would I solve this problem?
Right, footnotes are a pain — they don’t support either styles or preserve formatting workarounds AFAIK. That means you need to either:
Deal with this using a post-processing method (i.e. a script to unescape strings that are in a footnote). A regular expression like (?<=\S)\\_(?=\S) will remove \_ when it has a non-space before and after it. You could ensure there is a @ and word characters also just to make sure it is part of a cite key etc, the regex can be pretty specific and can be run via ruby or another scripting language.
Edit the markdown manually and run pandoc yourself.
Switch over to styles. This then at least allows you to use raw markdown in the footnote and compile directly.
I can write you a quick script to run on the markdown to remove the escaping in footnotes if you want.
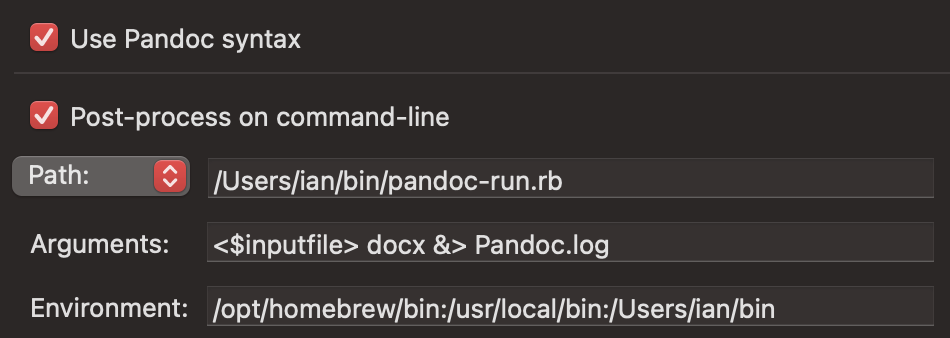
I would be very greatful, if you indeed could write me a quick script to run on the markdown to remove the escaping in footnotes… at the moment I use pandoc with these arguments: -s --lua-filter=...path.../zotero.lua --citeproc --bibliography ...path.../MyLibrary.yaml -o "<$outputname>.docx".
the lua script for zotero I have from here: Markdown/Pandoc :: Better BibTeX for Zotero
which is great, but you probably knew what I was talking about… but just in case it was important, which other arguments and scripts I use.
However: what do you mean by the third option – switching over to styles? Could I define a style, which compiles to footnotes? Probably, right? yet then I loose the function of the footnotes pane, which I found quite handy.
I have no idea, why it must be so hard in scrivener to format and define text in footnotes. I thought it was an app for really complex text projects.
Ok I modified my existing run scripts (for pandoc> typst and quarto) to do a simple edit of the markdown footnotes:
You will need to edit bib and filter lines to your requirements. Then you use this script instead of pandoc in the post-processor. You can change output format by changing docx to another extension:
This script simply replaces \_ with _ ONLY in footnotes. If your file is called test.md it makes a test-edit.md then runs that with pandoc to generate test.docx
All I meant was that once you’ve switched to styles, then there is no escaping, so you don’t have to worry about escaping in the footnotes. For footnotes, you just write raw markdown, but you get to still use the footnote UI. You could make footnotes with a style, but i also agree this is a pain to do manually…
I imagine there is a technical reason why styles don’t work in footnotes, and while I would prefer styles to work everywhere, given how powerful everything else it it is something I at least can live with…
tried it, changed bib and filter, yet I get this access denied log:
/bin/bash: /Users/mklenk/bin/pandoc-run.rb: Permission denied
I should know these things, I am sorry, but I am clueless. do I have to give scrivener the permission to run scripts (and if so: how do I do this) or do I have to give the permission to myself as the user?
(macos 14.3.1. silicon)
raw markdown in footnotes would be no problem, I guess. But how can I convince scrivener to treat footnotes as “raw markup” when compiling? If that was possible, I wouldn’t have the problem of removing the “\_” either.
I couldn’t find a setting for it though.
In any case: I am so very grateful for all your help!!
maybe I should give up, I feel guilty because always asking you for help!
Unfortunately there is a problem:
the compiler-log reads:
[WARNING] Could not deduce format from file extension
Defaulting to html
pandoc: als: withBinaryFile: does not exist (No such file or directory)
I have no idea, what this points to, but I can say that the test-edit.md file has not changed \_ into _.
The docx file has not been compiled at all.
if I could give you any more information or screenshot some settings, please just let me know, I will try!
Once again, however, I am wondering if the possibility to use styles in footnote might be something the developers could think about? Or any easy way to define any letter or sign as compiled as raw text. Somerthing that would not be that crazy as this issue reveals? But I am very new to scrivener. Maybe I am holding it wrong.
There should be a more complete log, but that sounds like docx is not being correctly passed in for some reason. Here is a scrivener project with the script bundled in the compile format:
---
title: RTFEscape
author: Ian
---
# The Sun
This is a **test**. Here is a ref [@peters\_2024]. This is a \_test\_ to see what happens
# The Moon
This is a **test**. Here is a ref [@peters_2024]. This is a _test_ (that has preserve formatting) to see what happens[^fn1] to \*stuff\*...
[^fn1]: Here is \*\*some\*\* text [@peters\_2024]. Here is some\_text. Here is some\_text.
The script changes it to:
---
title: RTFEscape
author: Ian
---
# The Sun
This is a **test**. Here is a ref [@peters\_2024]. This is a \_test\_ to see what happens
# The Moon
This is a **test**. Here is a ref [@peters_2024]. This is a _test_ (that has preserve formatting) to see what happens[^fn1] to \*stuff\*...
[^fn1]: Here is \*\*some\*\* text [@peters_2024]. Here is some_text. Here is some_text.
Note the ref in the footnote is unescaped. And generates this log:
--> Input Filename: /Users/ian/Desktop/compile-mmd/RTFEscape.md
--> Output Filetype: docx
--> Modified path: /Users/ian/.rbenv/shims:/Users/ian/.pyenv/shims:/opt/homebrew/bin:/usr/local/bin:/Users/ian/Library/TinyTeX/bin/universal-darwin:/Users/ian/.local/bin:/opt/homebrew/bin:/Users/ian/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/Applications/Scrivener.app/Contents/Resources/MultiMarkdown/bin
--> Modified File with fixed footnotes: /Users/ian/Desktop/compile-mmd/RTFEscape-edit.md
--> Parsing took: 0.000449s
--> Running Command: pandoc -s --verbose --citeproc --lua-filter=/Users/ian/.local/share/pandoc/filters/pretty-urls.lua --bibliography=/Users/ian/.local/share/pandoc/Core.json --to=docx --output=/Users/ian/Desktop/compile-mmd/RTFEscape.docx /Users/ian/Desktop/compile-mmd/RTFEscape-edit.md
[INFO] Running filter citeproc
[INFO] Loaded /Users/ian/.local/share/pandoc/Core.json from /Users/ian/.local/share/pandoc/Core.json
[WARNING] Citeproc: citation peters not found
[WARNING] Citeproc: citation peters_2024 not found
[INFO] Completed filter citeproc in 228 ms
[INFO] Running filter /Users/ian/.local/share/pandoc/filters/pretty-urls.lua
[INFO] Completed filter /Users/ian/.local/share/pandoc/filters/pretty-urls.lua in 3 ms
I have citation errors as peters_2024 doesn’t exist in my database, but the docx is generated…
You are welcome to make a wishlist post, I would also prefer styles worked in footnotes (don’t worry you aren’t holding it wrong!) I vaguely remember this was previously discussed, either on this forum or during the beta period when styles were first added to Scrivener 3, but a new wishlist post wouldn’t hurt…
Yet I had to tweak it a little bit or let’s say: find some more problems (and avoid them):
it only works if the name of the project folder does not contain any spaces (maybe also the project itself, yet this I have not tested yet). I had to rename it, but I don’t know why this is the case. Sounds like the 20th century to me…
in the footnotes must not be any new paragraph. If there is, it will be compiled to markedown like this:
[^fn5]: This is a test of a footnote.
If you write a new paragraph here, any bibtex marker containing _ will not be changed as the script is supposed to do. See for example here: @benjamin\_ankleben\_2006
to be precise: the second paragraph within the same footnote will be indented – and therefor (?) omitted by the script? Yet I have no idea why.
Compared to this – the same footnote without a line break in it:
will be compiled properly to this
[^fn6]: This is a test of a footnote. If you do not write a new paragraph here, any bibtex marker containing _ will be changed as the script is supposed to do. See for example here: [@benjamin_ankleben_2006].
This is a side effect of the fact every path needs to be properly quoted. Terminals use spaces to separate options etc (whitespace is semantically meaningful), so spaces in paths remain an issue in the 21st century unless you escape spaces, or alwaus “/quote your path/” — which I wasn’t doing… I’ve tweaked the script (V0.1.04, redownload it from github) to use quotes everywhere. I do tend to always remove spaces in my paths, so didn’t see any issues…
Right this was actually by design, i was being cautious… My code found lines that started with [^xxx]: and only converted \_ in that line. The paragraph breaks mean subsequent lines don’t start with a footnote marker and so no processing. The question is what you want to happen? If you don’t care where escaping is removed (i.e. you always want \_ to become _), then in fact the code is much easier. This is modified to:
But with the caveat if you use _ in other places they could confused for markup. A script can do basically anything, but your input and output goals must be clear…