For others who don’t use Markdown or write academic papers, some examples may be helpful. In the past, I tweaked Scrivener’s styling system to add visual gloss whenever Markdown was present.
Simple typography
So here is typical typography, with my own styling gloss set up in Scrivener to make things visually apparent to me when writing. Note that the colors don’t actually “do” anything – they are meaningless, except to me. They just serve as a reminder of what is raw Markdown, Quarto Markdown, code spans or blocks, executable code, etc. It is Scrivener’s compiler and the post-processor (in my case Quarto) that will render the styling the way it is supposed to be.

Stare at this long enough, and your eyes will glaze over!
Here’s what it ends up looking like when rendered:
Tables
Simple tables are readable in Scrivener:

but complex ones are not:
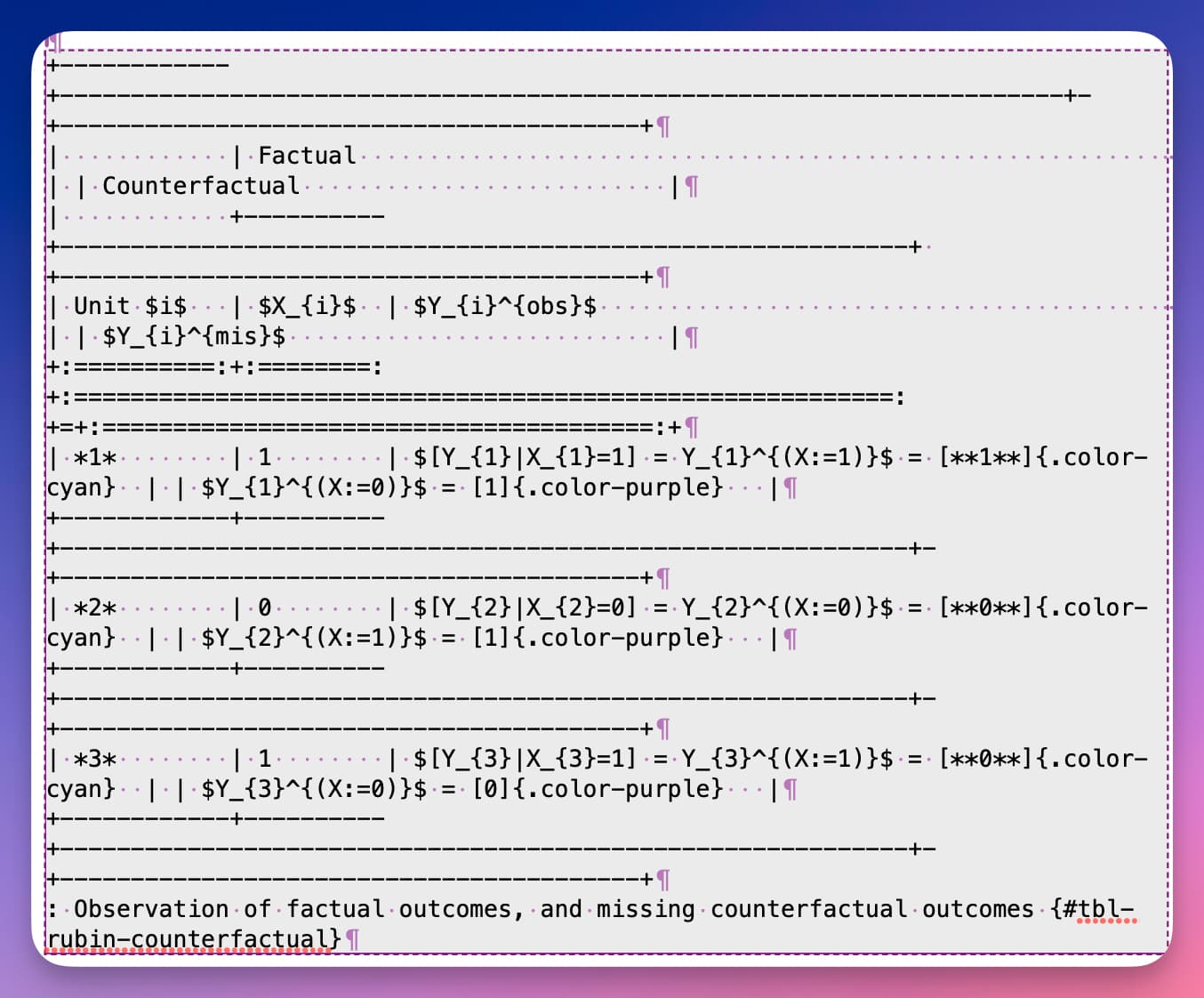
And of course, they don’t help you see what will be rendered:

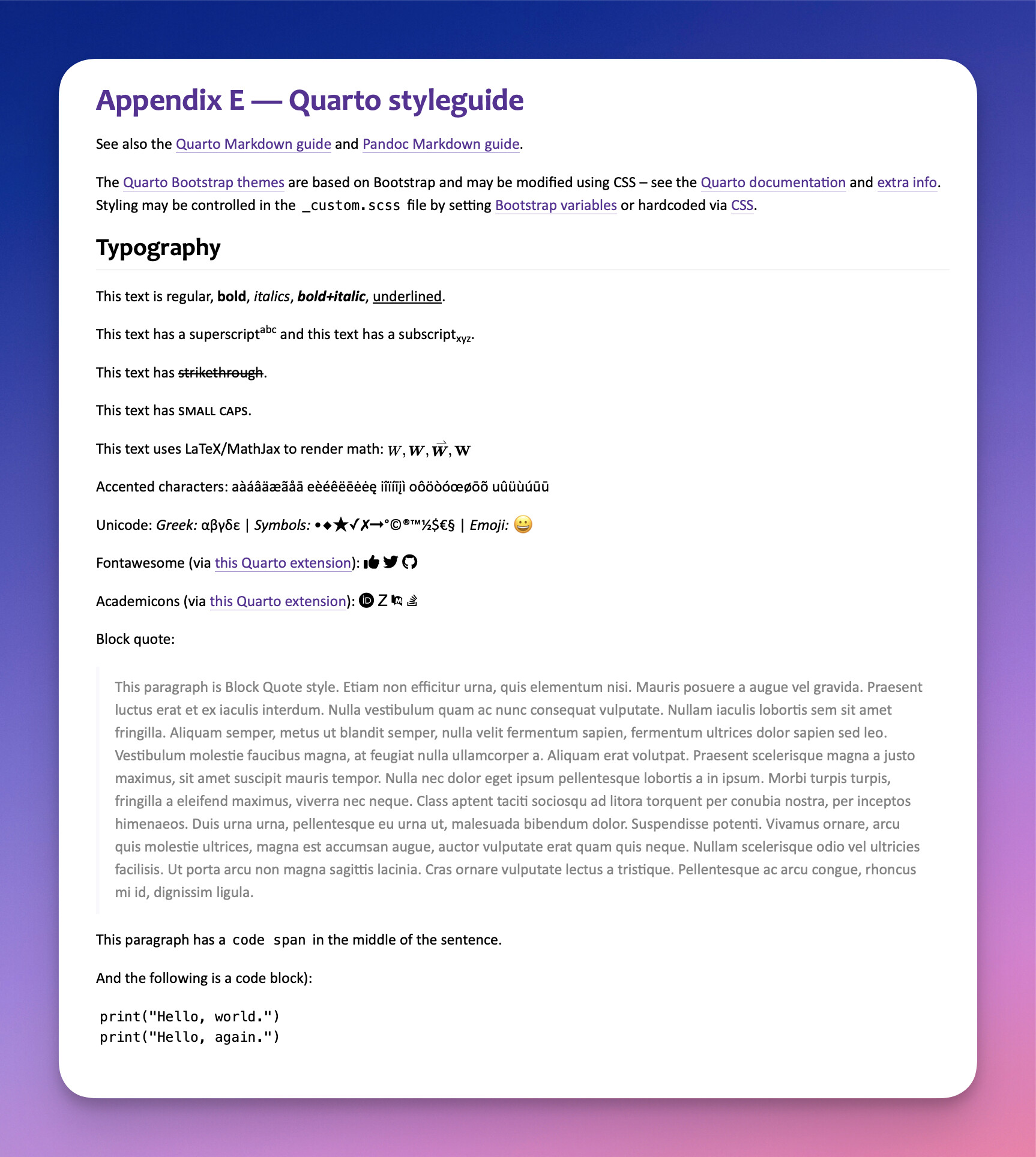
Equations
Equations are equally daunting to view and edit:


Figures
Here is a sample figure. It is contained in nested Markdown <div> blocks (indicated by the :::::: and ::: markers) and uses a LaTeX library called tikz to create the figure dynamically.

My Scrivener gloss just lets me know that it is raw Markdown, but doesn’t help me beyond that. This is what the figure looks like this once rendered by Quarto:
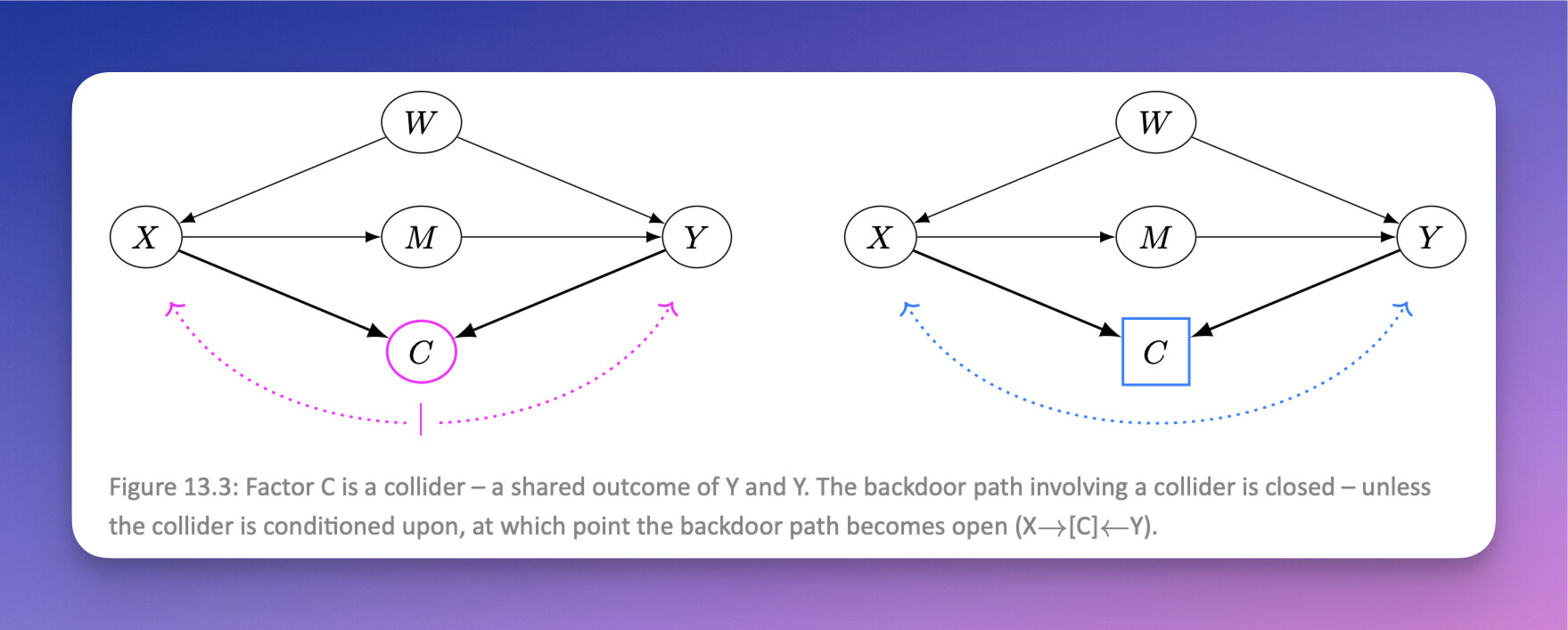
Notice that the figure caption is automatically labeled as “Figure 13.3” by the Quarto Processor.
(Side note: Why would you want to create a figure dynamically like this instead of cut-n-pasting an image, like Scrivener can do so easily? These figures are created dynamically when the code is run, so if a dataset changes or you otherwise tweak the code, you will get updated figures. These are not cut-n-paste figures that you later have to manually update if something needs to be redone, risking to have errata later on when you inevitably forget to update to the latest figure, or to update figure numbering when you moved something around.)
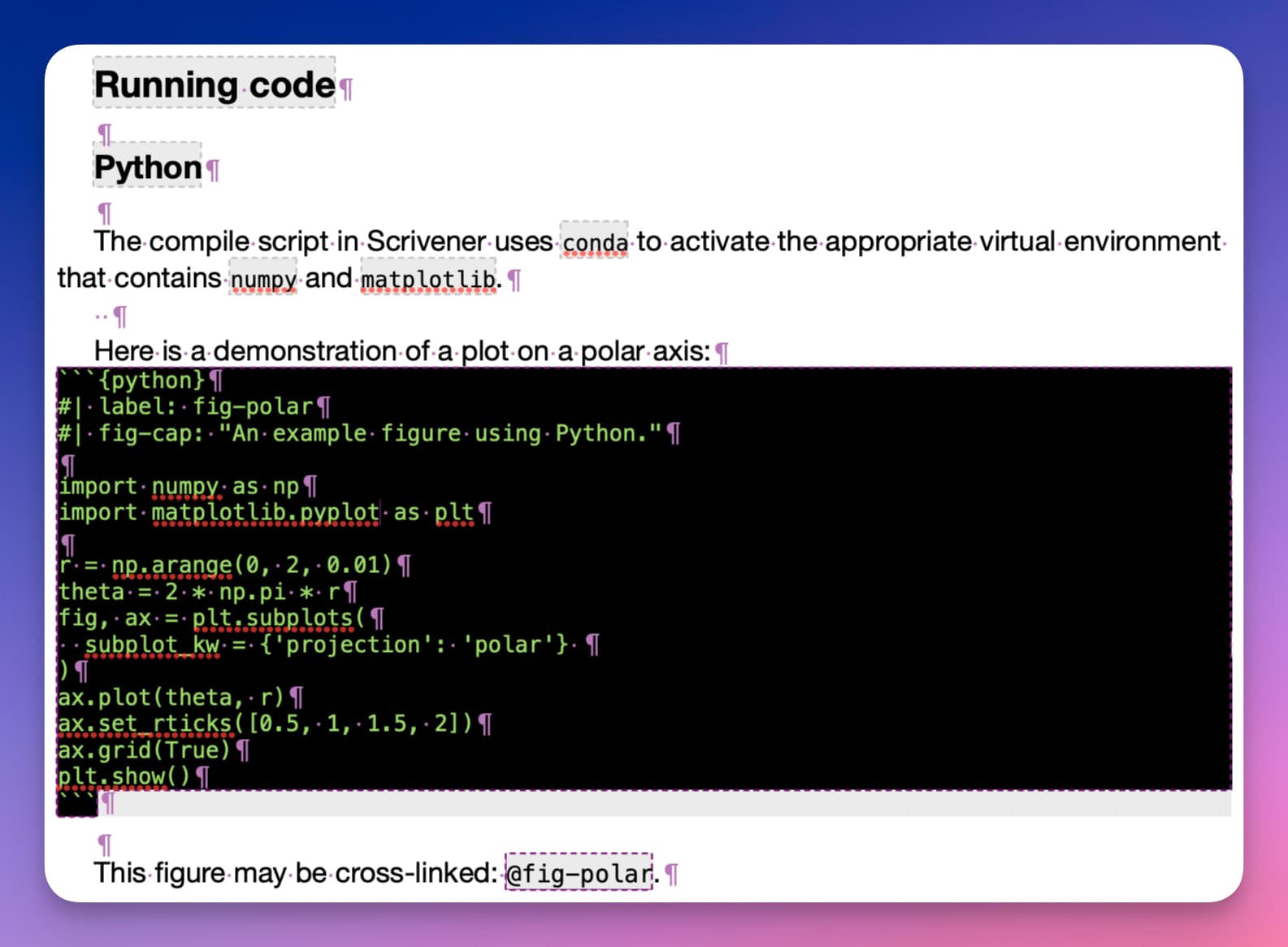
Executable code blocks (also shows crossrefs)
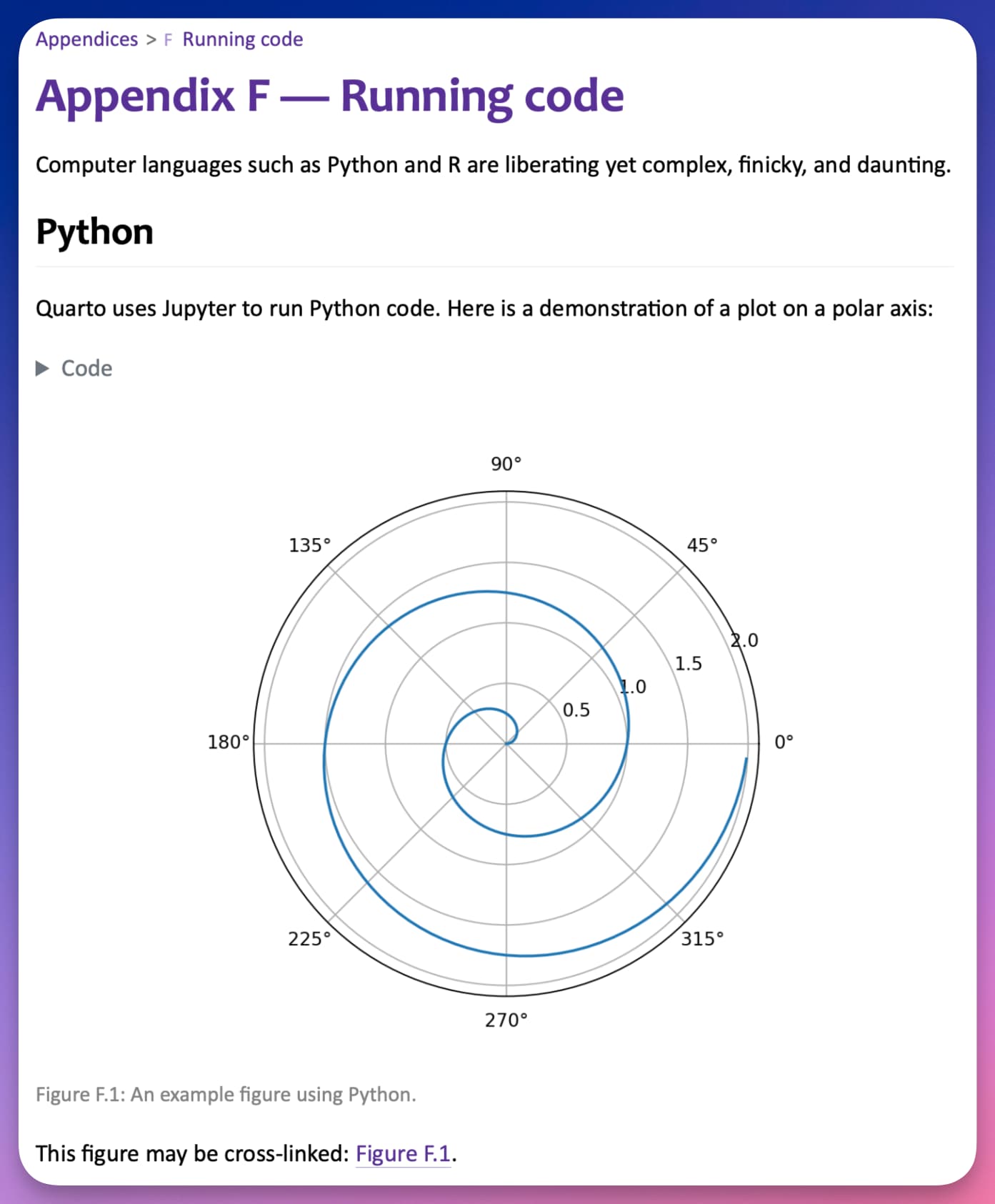
Here is how executable code blocks would look. (At the bottom, you can also see how the figure would be able to be easily referenced via a cross-ref, with the output becoming automatically labeled/numbered. In the second image below, you can see how the Markdown+code get rendered by the Quarto processor.)
Special features like callout blocks
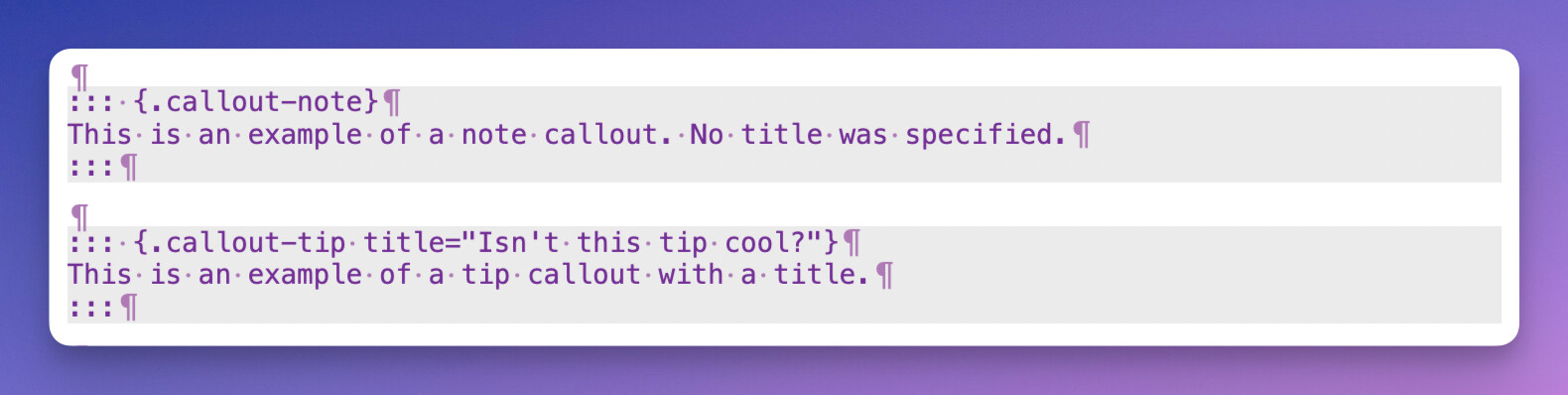
Callout blocks in Scrivener are distinguished as grey boxes. A Quarto-aware system might know that Quarto only allows 5 types of callouts and therefore color-code them according to type (note, tip, warning, caution, important). That would be amazing, but it is not crucial.

And much more!
And of course, there are citations and bibliographies and table of contents and footnotes/endnotes, index compilation, and marginalia all those things that Markdown/Quarto will give you. Combine that with Pandoc (which Quarto does for you), and you can get any output format you want – Word, PDF, web site, etc.
Anyhow, hopefully this gives others a glimpse at what academic/technical writing includes, and the reason there are people advocating for better workflows for academic writing (which is built largely on Markdown and LaTeX).